python 爬虫如何爬取动态生成的网页内容
--- 好的方法很多,我们先掌握一种 ---
【背景】
对于网页信息的采集,静态页面我们通常都可以通过python的request.get()库就能获取到整个页面的信息。
但是对于动态生成的网页信息来说,我们通过request.get()是获取不到。
【方法】
可以通过python第三方库selenium来配合实现信息获取,采取方案:python + request + selenium + BeautifulSoup
我们拿纵横中文网的小说采集举例(注意:请查看网站的robots协议找到可以爬取的内容,所谓盗亦有道):
思路整理:
1.通过selenium 定位元素的方式找到小说章节信息
2.通过BeautifulSoup加工后提取章节标题和对应的各章节的链接信息
3.通过request +BeautifulSoup 按章节链接提取小说内容,并将内容存储下来
【上代码】
1.先在开发者工具中,调试定位所需元素对应的xpath命令编写方式
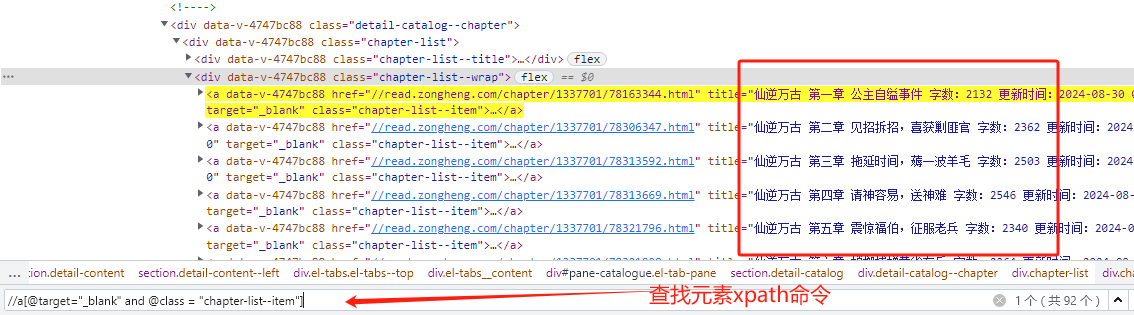
2.通过selenium 中find_elements()定位元素的方式找到所有小说章节,我们这里定义一个方法接受参数来使用
def Get_novel_chapters_info(url:str,xpath:str,skip_num=None,chapters_num=None):
# skip_num 需要跳过的采集章节(默认不跳过),chapters_num需要采集的章节数(默认全部章节)
# 创建Chrome选项(禁用图形界面)
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
driver.get(url)
driver.maximize_window()
time.sleep(3)
# 采集小说的章节元素
catalogues_list = []
try:
catalogues = driver.find_elements(By.XPATH,xpath)
if skip_num is None:
for catalogue in catalogues:
catalogues_list.append(catalogue.get_attribute('outerHTML'))
driver.quit()
if chapters_num is None:
return catalogues_list
else:
return catalogues_list[:chapters_num]
else:
for catalogue in catalogues[skip_num:]:
catalogues_list.append(catalogue.get_attribute('outerHTML'))
driver.quit()
if chapters_num is None:
return catalogues_list
else:
return catalogues_list[:chapters_num]
except Exception:
driver.quit()
3.把采集到的信息通过beautifulsoup加工后,提取章节标题和链接内容
# 获取章节标题和对应的链接信息
title_link = {}
for each in catalogues_list:
bs = BeautifulSoup(each,'html.parser')
chapter = bs.find('a')
title = chapter.text
link = 'https:' + chapter.get('href')
title_link[title] = link
4.通过request+BeautifulSoup 按章节链接提取小说内容,并保存到一个文件中
# 按章节保存小说内容
novel_path = '小说存放的路径/小说名称.txt'
with open(novel_path,'a') as f:
for title,url in title_link.items():
response = requests.get(url,headers={'user-agent':'Mozilla/5.0'})
html = response.content.decode('utf-8')
soup = BeautifulSoup(html,'html.parser')
content = soup.find('div',class_='content').text
# 先写章节标题,再写小说内容
f.write('---小西瓜免费小说---' + '\n'*2)
f.write(title + '\n')
f.write(content+'\n'*3)
python 爬虫如何爬取动态生成的网页内容的更多相关文章
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- python爬虫实战---爬取大众点评评论
python爬虫实战—爬取大众点评评论(加密字体) 1.首先打开一个店铺找到评论 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经 ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- Python爬虫之爬取站内所有图片
title date tags layut Python爬虫之爬取站内所有图片 2018-10-07 Python post 目标是 http://www.5442.com/meinv/ 如需在非li ...
- Python爬虫之爬取淘女郎照片示例详解
这篇文章主要介绍了Python爬虫之爬取淘女郎照片示例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧 本篇目标 抓取淘宝MM ...
- python爬虫项目-爬取雪球网金融数据(关注、持续更新)
(一)python金融数据爬虫项目 爬取目标:雪球网(起始url:https://xueqiu.com/hq#exchange=CN&firstName=1&secondName=1_ ...
- 初次尝试python爬虫,爬取小说网站的小说。
本次是小阿鹏,第一次通过python爬虫去爬一个小说网站的小说. 下面直接上菜. 1.首先我需要导入相应的包,这里我采用了第三方模块的架包,requests.requests是python实现的简单易 ...
- python 爬虫之爬取大街网(思路)
由于需要,本人需要对大街网招聘信息进行分析,故写了个爬虫进行爬取.这里我将记录一下,本人爬取大街网的思路. 附:爬取得数据仅供自己分析所用,并未用作其它用途. 附:本篇适合有一定 爬虫基础 crawl ...
- Python爬虫项目--爬取链家热门城市新房
本次实战是利用爬虫爬取链家的新房(声明: 内容仅用于学习交流, 请勿用作商业用途) 环境 win8, python 3.7, pycharm 正文 1. 目标网站分析 通过分析, 找出相关url, 确 ...
随机推荐
- SPI协议,MCP2515裸机驱动详解
SPI概述 Serial Peripheral interface 通用串行外围设备接口 是Motorola首先在其MC68HCXX系列处理器上定义的.SPI接口主要应用在 EEPROM,FLASH, ...
- 嵌入式数据库sqlite3【进阶篇】-子句和函数的使用,小白一文入门
在<嵌入式数据库sqlite3命令操作基础篇-增删改查,小白一文入门>一文中讲解了如何实现sqlite3的基本操作增删改查,本文介绍一些其他复杂一点的操作.比如where.order by ...
- Ubuntu16.04换成清华大学源
第一:备份源文件 # 源文件sources.list 在/etc/apt/目录下 # 备份源文件 sudo cp sources.list sources.list.bak 第二步:替换源文件 # 清 ...
- k8s手动安装
一.主节点安装 设置主机名hostnamectl set-hostname masterhostnamectl set-hostname node01 修改hosts文件vim /etc/hosts1 ...
- js_问题记录2022年6月24日19:35:12
小问题中的大问题 新建子js脚本一定记得创建函数,不然写什么都无法实现 比如 新建了new1.js脚本,首先需要创建function后才能在里面进行参数操作和调用 js实现的功能: 获取到对应的id= ...
- NumPy 使用
NumPy 相当于 Python 中的 MATLAB import numpy as np # 被除数数组 dividends = np.array([10, 20, 30, 40, 50]) # 除 ...
- 全网最适合入门的面向对象编程教程:42 Python常用复合数据类型-collections容器数据类型
全网最适合入门的面向对象编程教程:42 Python 常用复合数据类型-collections 容器数据类型 摘要: 在 Python 中,collections 模块提供了一组高效.功能强大的容器数 ...
- sql日期创建
TRUNCATE TABLE SYS_DATEINFO declare @i int set @i=-30000 WHILE @i<1000000 BEGIN INSERT INTO SYS_D ...
- JavaScript Library – YouTube Embedded、YouTube Player API、YouTube Data API
YouTube Embed Video 参考: Embed videos & playlists 它和 Google Maps Embed 类似,是通过 iframe 完成的. <ifr ...
- Avalonia upgrade from 0.10 to 11.x
Avalonia 从0.10版本升级到11.x版本.由于11.x新版本与旧版本对比发生了破坏性的变化,因此官方给出了升级的攻略可以参考. https://docs.avaloniaui.net/doc ...