python 爬虫如何爬取动态生成的网页内容
--- 好的方法很多,我们先掌握一种 ---
【背景】
对于网页信息的采集,静态页面我们通常都可以通过python的request.get()库就能获取到整个页面的信息。
但是对于动态生成的网页信息来说,我们通过request.get()是获取不到。
【方法】
可以通过python第三方库selenium来配合实现信息获取,采取方案:python + request + selenium + BeautifulSoup
我们拿纵横中文网的小说采集举例(注意:请查看网站的robots协议找到可以爬取的内容,所谓盗亦有道):
思路整理:
1.通过selenium 定位元素的方式找到小说章节信息
2.通过BeautifulSoup加工后提取章节标题和对应的各章节的链接信息
3.通过request +BeautifulSoup 按章节链接提取小说内容,并将内容存储下来
【上代码】
1.先在开发者工具中,调试定位所需元素对应的xpath命令编写方式
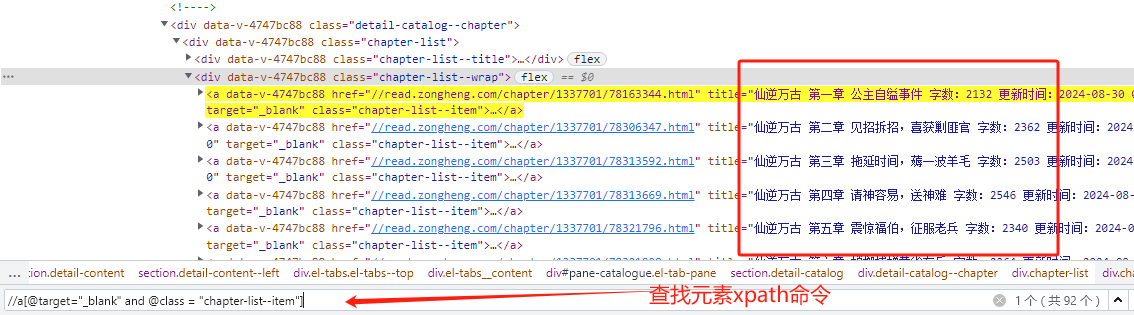
2.通过selenium 中find_elements()定位元素的方式找到所有小说章节,我们这里定义一个方法接受参数来使用
def Get_novel_chapters_info(url:str,xpath:str,skip_num=None,chapters_num=None):
# skip_num 需要跳过的采集章节(默认不跳过),chapters_num需要采集的章节数(默认全部章节)
# 创建Chrome选项(禁用图形界面)
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
driver.get(url)
driver.maximize_window()
time.sleep(3)
# 采集小说的章节元素
catalogues_list = []
try:
catalogues = driver.find_elements(By.XPATH,xpath)
if skip_num is None:
for catalogue in catalogues:
catalogues_list.append(catalogue.get_attribute('outerHTML'))
driver.quit()
if chapters_num is None:
return catalogues_list
else:
return catalogues_list[:chapters_num]
else:
for catalogue in catalogues[skip_num:]:
catalogues_list.append(catalogue.get_attribute('outerHTML'))
driver.quit()
if chapters_num is None:
return catalogues_list
else:
return catalogues_list[:chapters_num]
except Exception:
driver.quit()
3.把采集到的信息通过beautifulsoup加工后,提取章节标题和链接内容
# 获取章节标题和对应的链接信息
title_link = {}
for each in catalogues_list:
bs = BeautifulSoup(each,'html.parser')
chapter = bs.find('a')
title = chapter.text
link = 'https:' + chapter.get('href')
title_link[title] = link
4.通过request+BeautifulSoup 按章节链接提取小说内容,并保存到一个文件中
# 按章节保存小说内容
novel_path = '小说存放的路径/小说名称.txt'
with open(novel_path,'a') as f:
for title,url in title_link.items():
response = requests.get(url,headers={'user-agent':'Mozilla/5.0'})
html = response.content.decode('utf-8')
soup = BeautifulSoup(html,'html.parser')
content = soup.find('div',class_='content').text
# 先写章节标题,再写小说内容
f.write('---小西瓜免费小说---' + '\n'*2)
f.write(title + '\n')
f.write(content+'\n'*3)
python 爬虫如何爬取动态生成的网页内容的更多相关文章
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- python爬虫实战---爬取大众点评评论
python爬虫实战—爬取大众点评评论(加密字体) 1.首先打开一个店铺找到评论 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经 ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- Python爬虫之爬取站内所有图片
title date tags layut Python爬虫之爬取站内所有图片 2018-10-07 Python post 目标是 http://www.5442.com/meinv/ 如需在非li ...
- Python爬虫之爬取淘女郎照片示例详解
这篇文章主要介绍了Python爬虫之爬取淘女郎照片示例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧 本篇目标 抓取淘宝MM ...
- python爬虫项目-爬取雪球网金融数据(关注、持续更新)
(一)python金融数据爬虫项目 爬取目标:雪球网(起始url:https://xueqiu.com/hq#exchange=CN&firstName=1&secondName=1_ ...
- 初次尝试python爬虫,爬取小说网站的小说。
本次是小阿鹏,第一次通过python爬虫去爬一个小说网站的小说. 下面直接上菜. 1.首先我需要导入相应的包,这里我采用了第三方模块的架包,requests.requests是python实现的简单易 ...
- python 爬虫之爬取大街网(思路)
由于需要,本人需要对大街网招聘信息进行分析,故写了个爬虫进行爬取.这里我将记录一下,本人爬取大街网的思路. 附:爬取得数据仅供自己分析所用,并未用作其它用途. 附:本篇适合有一定 爬虫基础 crawl ...
- Python爬虫项目--爬取链家热门城市新房
本次实战是利用爬虫爬取链家的新房(声明: 内容仅用于学习交流, 请勿用作商业用途) 环境 win8, python 3.7, pycharm 正文 1. 目标网站分析 通过分析, 找出相关url, 确 ...
随机推荐
- k8s资源预留
Kubernetes 的节点可以按照 Capacity 调度.默认情况下 pod 能够使用节点全部可用容量. 这是个问题,因为节点自己通常运行了不少驱动 OS 和 Kubernetes 的系统守护进程 ...
- C#反射在数据库操作中的应用(反射属性,反射字段)
这几天学习反射的应用,今天把其应用到数据操作中 现记录学习笔记 环境为: 编译器:vs2017 数据库:access 反射类型为:字段 1先在类文件的定义是用哪种数据库,和用字段还是属性来反射 本例是 ...
- 什么?!90%的ThreadLocal都在滥用或错用!
最近在看一个系统代码时,发现系统里面在使用到了 ThreadLocal,乍一看,好像很高级的样子.我再仔细一看,这个场景并不会存在线程安全问题,完全只是在一个方法中传参使用的啊!(震惊) 难道是我水平 ...
- java_Web
开始进入学习java web部分 一.Socket技术 字节流传输 使用bytes[] 封装字节进行传输数据 文件传输 浏览器访问 使用http协议进行访问 二.MySQL数据库 环境 Phpstyd ...
- Java是值传递还是引用传递,又是怎么体现的
关于Java是值传递还是引用传递,可以从代码层面来实现一下拿到结果 执行下面的代码: public static void main(String[] args) { int num = 10; St ...
- OpenAI注册-临时手机号/邮箱
OpenAI 在注册ChatGPT时,发生了一个错误,使用邮箱进行注册后,在注册界面会提示"Not available OpenAI's services are not available ...
- ServiceMesh 1:大火的云原生微服务网格,究竟好在哪里?
1 关于云原生 云原生计算基金会(Cloud Native Computing Foundation, CNCF)的官方描述是: 云原生是一类技术的统称,通过云原生技术,我们可以构建出更易于弹性扩展. ...
- IIS Reverse Proxy 反向代理
前言 反向代理是这样的: 2 台 web server, A server, B server A server 是 public 的, 有 domain, 有 SSL (作为 B server 的代 ...
- Centos7 阿里云镜像 2207-02 下安装docker-compose后,docker-compose version 命令失效问题
吐槽下,按照官方教程和网上各种教程折腾了很久,最后试出来的. 首先找到docker-compose被安装到那里 whereis docker --输出示例,cd命令进入各自目录查看docker-com ...
- 运输小猫娘之再续 5k 传奇
写的比较意识流 前情提要 上回书说到,5k 因为拯救大家被炸断了 \(1000000007\) 米的牛至中的十五千米,尽管大家的欢呼声如此热烈,就像大家的热量正在像烈火一样散发出来,但是 5k 却无心 ...