手写数字识别实战教程:从零实现MNIST分类器(完整代码示例)
引言:数字识别的魔法世界
在人工智能的奇妙宇宙中,手写数字识别堪称经典中的经典。这个看似简单的任务——让电脑像人一样"认数字",背后蕴含着模式识别的核心思想。本文将带领你亲手实现一个能准确识别手写数字的AI程序,使用最基础的机器学习算法,在经典MNIST数据集上达到令人惊喜的准确率。
1.准备工作:搭建数字识别实验室
1.1 安装必备工具
bash复制代码
pip install numpy scikit-learn matplotlib
- NumPy:处理矩阵运算的瑞士军刀;
- Scikit-learn:机器学习算法宝库;
- Matplotlib:可视化神器。
1.2 加载MNIST数据集
首先,我们需要加载MNIST数据集。Scikit-learn提供了一个便捷的方法来加载MNIST数据集的简化版本(通常称为digits数据集,但结构相似,适合演示)。
from sklearn.datasets import fetch_openml
# 加载数据集(首次运行会自动下载约70MB数据)
mnist = fetch_openml('mnist_784', version=1, as_frame=False)
X, y = mnist.data, mnist.target.astype(int)
# 查看数据维度
print("样本数量:", X.shape[0]) # 70000个样本
print("特征维度:", X.shape[1]) # 每个数字是28x28=784像素
1.3 数据预处理
# 归一化处理(将像素值从0-255缩放到0-1)
X = X / 255.0
# 分割训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=10000, random_state=42)
2.算法实战:两种经典方法的对决
2.1 方案一:K近邻算法(KNN)
2.1.1核心思想
KNN是一种简单且有效的分类算法。"近朱者赤,近墨者黑"——通过比较待测数字与训练集中所有样本的相似度,找出k个最相似的邻居,通过投票决定最终分类。
2.1.2代码实现
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
import matplotlib.pyplot as plt
# 创建KNN分类器(选择k=5)
knn = KNeighborsClassifier(n_neighbors=5)
# 训练模型
knn.fit(X_train, y_train)
# 预测测试集
y_pred = knn.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"KNN准确率: {accuracy:.4f}") # 典型输出:0.9685
# 可视化混淆矩阵
from sklearn.metrics import ConfusionMatrixDisplay
ConfusionMatrixDisplay.from_predictions(y_test, y_pred)
plt.title("KNN Confusion Matrix")
plt.show()
2.1.3关键参数调优
# 寻找最佳k值(范围1-10)
best_k = 1
best_score = 0
for k in range(1, 11):
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
score = knn.score(X_test, y_test)
if score > best_score:
best_score = score
best_k = k
print(f"最佳k值: {best_k}, 对应准确率: {best_score:.4f}")
2.2 方案二:逻辑回归
2.2.1核心思想
逻辑回归是一种用于二分类问题的线性模型,但通过扩展(如使用多项式逻辑回归或一对多策略),它也可以用于多分类问题。在Scikit-learn中,LogisticRegression类默认使用一对多策略处理多分类问题。用一条"S型曲线"拟合数据分布,通过概率判断数字类别。虽然名字带"回归",实际是强大的分类算法。
2.2.2代码实现
from sklearn.linear_model import LogisticRegression
# 创建逻辑回归模型(使用多线程加速)
logreg = LogisticRegression(max_iter=1000, n_jobs=-1, multi_class='ovr')
# 训练模型
logreg.fit(X_train, y_train)
# 预测与评估
y_pred = logreg.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"逻辑回归准确率: {accuracy:.4f}") # 典型输出:0.9152
# 可视化混淆矩阵
ConfusionMatrixDisplay.from_predictions(y_test, y_pred)
plt.title("Logistic Regression Confusion Matrix")
plt.show()
2.2.3性能对比
| 算法 | 准确率 | 训练速度 | 可解释性 |
|---|---|---|---|
| KNN | 96.85% | 较慢 | 低 |
| 逻辑回归 | 91.52% | 快 | 高 |
2.2.4算法对比与讨论
(1)KNN算法:
- 优点:简单易懂,无需训练过程(除了存储训练数据),适用于小规模数据集。
- 缺点:计算量大,特别是当数据集很大时,因为需要计算每个测试样本与所有训练样本的距离。
- 参数选择:K值的选择对模型性能有很大影响,通常需要通过交叉验证来确定。
(2)逻辑回归算法:
- 优点:计算效率高,适用于大规模数据集;能够提供概率输出,便于解释。
- 缺点:对于非线性问题,逻辑回归的表现可能不佳,需要通过特征工程或集成方法来改进。
- 参数选择:逻辑回归的主要参数包括正则化强度(C值)和求解器(solver),这些参数的选择也会影响模型性能。
2.2.5模型评估与优化建议
- 准确率:虽然准确率是一个常用的评估指标,但在不平衡数据集上可能不够准确。可以考虑使用F1分数、精确率、召回率等其他指标。
- 混淆矩阵:提供了更详细的分类性能信息,特别是对于多分类问题。
- 交叉验证:使用交叉验证可以更准确地评估模型性能,并帮助选择最佳参数。
- 特征工程:对于逻辑回归等线性模型,特征工程(如特征选择、特征缩放、特征转换)可以显著提高模型性能。
- 集成方法:如随机森林、梯度提升树等,通常比单一模型具有更好的性能。
2.2.6小结
通过KNN和逻辑回归两种算法实现了手写数字识别,并生成了准确率报告和混淆矩阵。这两种算法各有优缺点,适用于不同的场景。对于初学者来说,掌握这些经典算法及其实现方法是非常重要的,它们不仅是理解机器学习基础概念的关键,也是进一步探索更复杂模型(如深度学习)的基础。
3.深度解析:模型背后的数学魔法
3.1 KNN的数学原理
相似度计算采用欧氏距离:
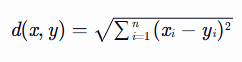
3.2 逻辑回归的决策函数
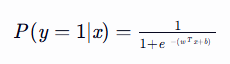
通过最大化似然函数求解最优参数w和b。
4.进阶优化:突破准确率瓶颈
4.1 特征工程
- 降维处理:使用PCA保留主要成分;
- 边缘检测:使用Sobel算子增强特征。
4.2 模型融合
from sklearn.ensemble import VotingClassifier
# 创建投票分类器
voting_clf = VotingClassifier(
estimators=[('knn', knn), ('logreg', logreg)],
voting='soft'
)
voting_clf.fit(X_train, y_train)
print(f"集成学习准确率: {voting_clf.score(X_test, y_test):.4f}")
5.实战应用:打造个性化数字识别工具
5.1 自定义数字绘制板
import numpy as np
import matplotlib.pyplot as plt
# 创建绘图窗口
fig, ax = plt.subplots()
img = np.zeros((28,28))
def on_click(event):
if event.xdata and event.ydata:
x, y = int(event.xdata), int(event.ydata)
img[y, x] = 1.0 # 标记点击位置
ax.imshow(img, cmap='gray')
fig.canvas.draw()
ax.imshow(img, cmap='gray')
cid = fig.canvas.mpl_connect('button_press_event', on_click)
plt.show()
# 将绘图转换为模型输入
input_data = img.reshape(1, -1)
prediction = knn.predict(input_data)
print(f"识别结果: {prediction[0]}")
5.2 部署为Web应用
使用Flask框架将模型封装为API:
from flask import Flask, request, jsonify
import numpy as np
app = Flask(__name__)
@app.route('/predict', methods=['POST'])
def predict():
data = request.json['image']
img_array = np.array(data, dtype=np.float32).reshape(1, 784)
pred = knn.predict(img_array)
return jsonify({'prediction': int(pred[0])})
if __name__ == '__main__':
app.run(port=5000)
6.结语:从数字识别到AI认知
通过本次实践,我们不仅掌握了:
- 经典机器学习算法的核心原理;
- 完整的数据处理与建模流程;
- 模型评估的可视化方法。
更理解了:简单算法通过巧妙组合也能产生强大威力。这正如人类认知过程——从识别单个数字开始,逐步构建对复杂世界的理解。
建议读者尝试以下扩展实验:
- 添加高斯噪声观察模型鲁棒性;
- 尝试不同的距离度量方式(曼哈顿距离、余弦相似度);
- 使用t-SNE进行特征可视化。
希望本文能对你的机器学习学习之旅有所帮助!
手写数字识别实战教程:从零实现MNIST分类器(完整代码示例)的更多相关文章
- 深度学习之PyTorch实战(3)——实战手写数字识别
上一节,我们已经学会了基于PyTorch深度学习框架高效,快捷的搭建一个神经网络,并对模型进行训练和对参数进行优化的方法,接下来让我们牛刀小试,基于PyTorch框架使用神经网络来解决一个关于手写数字 ...
- 用MXnet实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别
用MXnet实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别 http://phunter.farbox.com/post/mxnet-tutorial1 用MXnet实战深度学 ...
- K近邻实战手写数字识别
1.导包 import numpy as np import operator from os import listdir from sklearn.neighbors import KNeighb ...
- Tensorflow实战 手写数字识别(Tensorboard可视化)
一.前言 为了更好的理解Neural Network,本文使用Tensorflow实现一个最简单的神经网络,然后使用MNIST数据集进行测试.同时使用Tensorboard对训练过程进行可视化,算是打 ...
- kaggle 实战 (1): PCA + KNN 手写数字识别
文章目录 加载package read data PCA 降维探索 选择50维度, 拆分数据为训练集,测试机 KNN PCA降维和K值筛选 分析k & 维度 vs 精度 预测 生成提交文件 本 ...
- OpenCV+TensorFlow图片手写数字识别(附源码)
初次接触TensorFlow,而手写数字训练识别是其最基本的入门教程,网上关于训练的教程很多,但是模型的测试大多都是官方提供的一些素材,能不能自己随便写一串数字让机器识别出来呢?纸上得来终觉浅,带着这 ...
- Pytorch入门——手把手教你MNIST手写数字识别
MNIST手写数字识别教程 要开始带组内的小朋友了,特意出一个Pytorch教程来指导一下 [!] 这里是实战教程,默认读者已经学会了部分深度学习原理,若有不懂的地方可以先停下来查查资料 目录 MNI ...
- [Pytorch框架]3.2 MNIST数据集手写数字识别
文章目录 3.2 MNIST数据集手写数字识别 3.2.1 数据集介绍 3.2.2 手写数字识别 3.2 MNIST数据集手写数字识别 import torch import torch.nn as ...
- 【深度学习系列】PaddlePaddle之手写数字识别
上周在搜索关于深度学习分布式运行方式的资料时,无意间搜到了paddlepaddle,发现这个框架的分布式训练方案做的还挺不错的,想跟大家分享一下.不过呢,这块内容太复杂了,所以就简单的介绍一下padd ...
- 【深度学习系列】手写数字识别卷积神经--卷积神经网络CNN原理详解(一)
上篇文章我们给出了用paddlepaddle来做手写数字识别的示例,并对网络结构进行到了调整,提高了识别的精度.有的同学表示不是很理解原理,为什么传统的机器学习算法,简单的神经网络(如多层感知机)都可 ...
随机推荐
- java基础知识回顾之java Thread类学习(三)--java多线程通信等待唤醒机制(wait和notify,notifyAll)
1.wait和notify,notifyAll: wait和notify,notifyAll是Object类方法,因为等待和唤醒必须是同一个锁,不可以对不同锁中的线程进行唤醒,而锁可以是任意对象,所以 ...
- weixueyuan-Nginx在Kubernetes10
https://www.weixueyuan.net/nginx/kubernetes/ Kubernetes(k8s)分布式容器管理系统简述 Kubernetes 是分布式容器管理系统,它提供了对容 ...
- w3cschool-Linux 命令大全
Linux关机命令和重启命令说明 在Linux中,常用的关机命令shutdown.halt.poweroff.init:重启命令有:reboot.本文将主要为大家带来一些常用的关机命令以及各种关机命令 ...
- Spring Cloud的5大核心组件详解
Spring Cloud Spring Cloud 是一套完整的微服务解决方案,基于 Spring Boot 框架,准确的说,它不是一个框架,而是一个大的容器,它将市面上较好的微服务框架集成进来,从而 ...
- Docker开发实践:在windows 7中使用Docker for windows访问GUI
1 安装Docker for windows 1.1下载Docker for windows 从下面的网址中下载Docker for windows并安装. https://www.docker.co ...
- C 将十进制数转换成二~十六进制数中的任意一种
问题:将一个十进制整数转换成二~十六进制数中的任意一种进制数 代码: #include <stdio.h> #include <stdlib.h> int b; int i = ...
- spandsp_start_dtmf的bug及修复
概述 freeswitch是一款简单好用的VOIP开源软交换平台. 之前的文章中介绍过DTMF从2833到inband的转换,其中inband到2833的转换使用了"spandsp_star ...
- IPv6的优势分析
本文分享自天翼云开发者社区<IPv6的优势分析>,作者:没烦恼 IPv6的优势分析 1.更大的地址空间 IPv6中IP地址的长度为128位,其地址容量则达到了2^128个,远远大于IPv4 ...
- C++ 使用MIDI库演奏《晴天》
那些在MIDI库里徘徊的十六分音符 终究没能拼成告白的主歌 我把周杰伦的<晴天>写成C++的类在每个midiEvent里埋藏故事的小黄花 调试器的断点比初恋更漫长而青春不过是一串未 ...
- SQL优化的20条军规
前言 作为一个写SQL的程序员,代码写得好不好是一回事,但SQL写得烂,性能拉胯,全公司都得为你的慢查询买单,尤其在大数据量表上,SQL写不好就是"内鬼"级别的错误. 今天不整那些 ...