Flink 状态编程
概念
在Flink架构体系中,有状态计算可以说是Flink非常重要的特性之一
Flink优势:
- 支持高吞吐、低延迟、高性能
- 支持事件时间Event_time概念
- 支持有状态计算
有状态计算是指:
在程序计算过程中,在Flink程序内部存储计算产生的中间结果,并提供给后续Function或算子计算结果使用。(如下图所示)
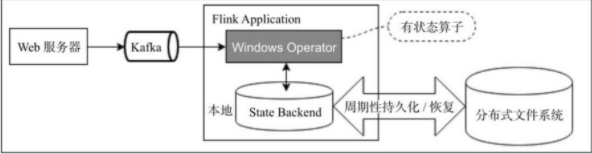
无状态计算实现的复杂度相对较低,实现起来较容易,但是无法完成提到的比较复杂的业务场景:
CEP(复杂事件处理):获取符合某一特定事件规则的事件,状态计算就可以将接入的事件进行存储,然后等待符合规则的事件触发
最大值、均值等聚合指标(如pv,uv):
需要利用状态来维护当前计算过程中产生的结果,例如事件的总数、总和以及最大,最小值等
机器学习场景,维护当前版本模型使用的参数
其他需要使用历史数据的计算
Flink状态编程
支持的状态类型
Flink根据数据集是否根据Key进行分区,将状态分为Keyed State和 Operator State(Non-keyed State) 两种类型。
其中Keyed State是Operator State的特例,可以通过Key Groups进行管理,主要用于当算子并行度发生变化时,自动重新分布Keyed Sate数据
同时在Flink中Keyed State和Operator State均具有两种形式:
一种为托管状态(ManagedState)形式,由Flink Runtime中控制和管理状态数据,并将状态数据转换成为内存Hashtables或RocksDB的对象存储,然后将这些状态数据通过内部的接口持久化到Checkpoints中,任务异常时可以通过这些状态数据恢复任务。
另外一种是原生状态(Raw State)形式,由算子自己管理数据结构,当触发Checkpoint过程中,Flink并不知道状态数据内部的数据结构,只是将数据转换成bytes数据存储在Checkpoints中,当从Checkpoints恢复任务时,算子自己再反序列化出状态的数据结构。
在Flink中推荐用户使用Managed State管理状态数据,主要原因是Managed State能够更好地支持状态数据的重平衡以及更加完善的内存管理。
Managed Keyed State
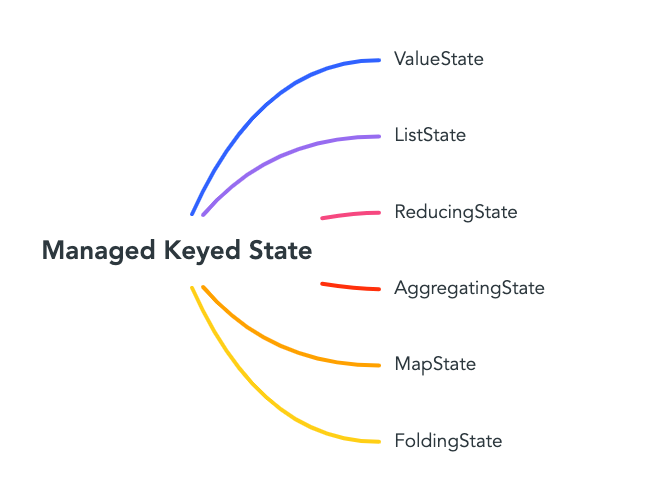
六种类型
Managed Keyed State 又分为如下六种类型:
基本API
在Flink中需要通过创建StateDescriptor来获取相应State的操作类。如下方代码,构建一个ValueState:
lazy val isPayedState: ValueState[Boolean] = getRuntimeContext.getState(new ValueStateDescriptor[Boolean]("is-payed-state", classOf[Boolean]))
其中对ValueState可以增删改查:
- 获取状态值
val isPayed = isPayedState.value()
- 更新状态值
isPayedState.update(true)
- 释放状态值
isPayedState.clear()
状态的生命周期
对于任何类型Keyed State都可以设定状态的生命周期(TTL),以确保能够在规定时间内及时地清理状态数据。
实现方法:
1、生成StateTtlConfig配置
2、将StateTtlConfig配置传入StateDescriptor中的enableTimeToLive方法中即可
import org.apache.flink.api.common.state.StateTtlConfig
import org.apache.flink.api.common.state.ValueStateDescriptor
import org.apache.flink.api.common.time.Time
val ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build
val stateDescriptor = new ValueStateDescriptor[String]("text state", classOf[String])
stateDescriptor.enableTimeToLive(ttlConfig)
Managed Operator State
Operator State是一种non-keyed state,与并行的操作算子实例相关联,例如在KafkaConnector中,每个Kafka消费端算子实例都对应到Kafka的一个分区中,维护Topic分区和Offsets偏移量作为算子的Operator State。在Flink中可以实现Checkpointed-Function或者ListCheckpointed两个接口来定义操作Managed Operator State的函数。
Case : 订单延迟告警统计
需求描述
在电商平台中,最终创造收入和利润的是用户下单购买的环节;更具体一点,是用户真正完成支付动作的时候。用户下单的行为可以表明用户对商品的需求,但在现实中,并不是每次下单都会被用户立刻支付。当拖延一段时间后,用户支付的意愿会降低。
所以为了让用户更有紧迫感从而提高支付转化率,同时也为了防范订单支付环节的安全风险,电商网站往往会对订单状态进行监控,设置一个失效时间(比如 15 分钟),如果下单后一段时间仍未支付,订单就会被取消。
此时需要给用户发送一个信息提醒用户,提高支付转换率
需求分析
本需求可以使用CEP来实现, 这里推荐使用process function原生的状态编程。
问题可以简化成: 在pay事件超时未发生的情况下,输出超时报警信息。
一个简单的思路是:
- 在订单的 create 事件到来后注册定时器,15分钟后触发;
- 用一个布尔类型的 Value 状态来作为标识位,表明 pay 事件是否发生过。
- 如果 pay 事件已经发生,状态被置为true,那么就不再需要做什么操作;
- 而如果 pay 事件一直没来,状态一直为false,到定时器触发时,就应该输出超时报警信息。
数据及模型
Demo data:
34729,create,,1558430842
34730,create,,1558430843
34729,pay,sd76f87d6,1558430844
34730,modify,3hu3k2432,1558430845
34731,create,,1558430846
34731,pay,35jue34we,1558430849
34732,create,,1558430852
34733,create,,1558430855
34734,create,,1558430859
34734,create,,1558431000
34733,pay,,1558431000
34732,pay,,1558449999
Flink的输入与输出类:
//定义输入订单事件的样例类
caseclassOrderEvent(orderId: Long, eventType: String, txId: String, eventTime: Long)
//定义输出结果样例类
caseclassOrderResult(orderId: Long, resultMsg: String)
代码实现
case class OrderEvent(orderId: Long, eventType: String, txId: String, eventTime: Long)
case class OrderResult(orderId: Long, resultMsg: String)
object OrderTimeOut {
val orderTimeoutOutputTag = new OutputTag[OrderResult]("orderTimeout")
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
val orderEventStream = env.socketTextStream("127.0.0.1", 9999)
.map(data => {
val dataArray = data.split(",")
OrderEvent(dataArray(0).trim.toLong, dataArray(1).trim, dataArray(2).trim, dataArray(3).trim.toLong)
})
.assignAscendingTimestamps(_.eventTime * 1000L)
.keyBy(_.orderId)
val orderResultStream = orderEventStream.process(new OrderPayMatch)
orderResultStream.print("payed")
orderResultStream.getSideOutput(orderTimeoutOutputTag).print("time out order")
env.execute("order timeout without cep job")
}
class OrderPayMatch() extends KeyedProcessFunction[Long, OrderEvent, OrderResult]() {
lazy val isPayedState: ValueState[Boolean] = getRuntimeContext.getState(new ValueStateDescriptor[Boolean]("is-payed-state", classOf[Boolean]))
lazy val timerState: ValueState[Long] = getRuntimeContext.getState(new ValueStateDescriptor[Long]("timer-state", classOf[Long]))
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[Long, OrderEvent, OrderResult]#OnTimerContext, out: Collector[OrderResult]): Unit = {
val isPayed = isPayedState.value()
if (isPayed) {
ctx.output(orderTimeoutOutputTag, OrderResult(ctx.getCurrentKey, "payed but no create"))
} else {
//Only create, but no pay
ctx.output(orderTimeoutOutputTag, OrderResult(ctx.getCurrentKey, "order timeout"))
}
isPayedState.clear()
timerState.clear()
}
override def processElement(value: OrderEvent, ctx: KeyedProcessFunction[Long, OrderEvent, OrderResult]#Context, out: Collector[OrderResult]): Unit = {
val isPayed = isPayedState.value()
val timerTs = timerState.value()
if (value.eventType == "create") {
if (isPayed) {
out.collect(OrderResult(value.orderId, "payed successfully"))
ctx.timerService().deleteEventTimeTimer(timerTs)
isPayedState.clear()
timerState.clear()
} else {
val ts = value.eventTime * 1000L + 15 * 60 * 1000L
ctx.timerService().registerEventTimeTimer(ts)
timerState.update(ts)
}
} else if (value.eventType == "pay") {
if (timerTs > 0) {
if (timerTs > value.eventTime * 1000L) {
out.collect(OrderResult(value.orderId, "payed successfully"))
} else {
ctx.output(orderTimeoutOutputTag, OrderResult(value.orderId, "this order is timeout"))
}
ctx.timerService().deleteEventTimeTimer(timerTs)
isPayedState.clear()
timerState.clear()
} else {
//pay first
isPayedState.update(true)
ctx.timerService().registerEventTimeTimer(value.eventTime * 1000L)
timerState.update(value.eventTime * 1000L)
}
}
}
}
}
总结
有状态计算是Flink的一个很好特性,在一些场景下如累加计算pv,uv等,不用在项目中引用外部存储如redis等,架构上更简单,更易于维护。
参考:
《大数据技术之电商用户行为分析》
Flink 状态编程的更多相关文章
- Flink的状态编程和容错机制(四)
一.状态编程 Flink 内置的很多算子,数据源 source,数据存储 sink 都是有状态的,流中的数据都是 buffer records,会保存一定的元素或者元数据.例如 : ProcessWi ...
- 【大数据面试】Flink 04:状态编程与容错机制、Table API、SQL、Flink CEP
六.状态编程与容错机制 1.状态介绍 (1)分类 流式计算分为无状态和有状态 无状态流针对每个独立事件输出结果,有状态流需要维护一个状态,并基于多个事件输出结果(当前事件+当前状态值) (2)有状态计 ...
- 【Flink】概念、入门、部署(yarn和standalone模式)、架构(组件和运行流程)、批处理、流处理API、window、时间语义、Wartermark、ProcessFunction、状态编程、Table API和SQL、CEP、面试题
一.Flink简介 1.概述 Apache Flink是为分布式.高性能.随时可用以及准确的流处理应用程序打造的开源流处理框架 对无界和有界数据流进行有状态计算 2.重要特点 (1)事件驱动型:从一个 ...
- 第03讲:Flink 的编程模型与其他框架比较
Flink系列文章 第01讲:Flink 的应用场景和架构模型 第02讲:Flink 入门程序 WordCount 和 SQL 实现 第03讲:Flink 的编程模型与其他框架比较 本课时我们主要介绍 ...
- 第09讲:Flink 状态与容错
Flink系列文章 第01讲:Flink 的应用场景和架构模型 第02讲:Flink 入门程序 WordCount 和 SQL 实现 第03讲:Flink 的编程模型与其他框架比较 第04讲:Flin ...
- Flink状态专题:keyed state和Operator state
众所周知,flink是有状态的计算.所以学习flink不可不知状态. 正好最近公司有个需求,要用到flink的状态计算,需求是这样的,收集数据库新增的数据. ...
- Flink DataStream 编程入门
流处理是 Flink 的核心,流处理的数据集用 DataStream 表示.数据流从可以从各种各样的数据源中创建(消息队列.Socket 和 文件等),经过 DataStream 的各种 transf ...
- 大数据计算引擎之Flink Flink状态管理和容错
这里将介绍Flink对有状态计算的支持,其中包括状态计算和无状态计算的区别,以及在Flink中支持的不同状态类型,分别有 Keyed State 和 Operator State .另外针对状态数据的 ...
- Flink状态管理与状态一致性(长文)
目录 一.前言 二.状态类型 2.1.Keyed State 2.2.Operator State 三.状态横向扩展 四.检查点机制 4.1.开启检查点 (checkpoint) 4.2.保存点机制 ...
- Flink状态后端的对比及机制
1. Flink状态后端的类型: MemoryStateBackend FsStateBackend RocksDBStateBackend 2. 各状态后端对比: 2.1 MemoryStateBa ...
随机推荐
- __set_BASEPRI(); 使用不正常
虽然 BASEPRI 是8位寄存器,但是STM32的CortexM3&M4只用了高4位,低四位是没有用到的. __set_BASEPRI(0x0f); // 无效,小于0x0f的值无效 __s ...
- 使用SiliconCloud快速体验SimpleRAG(手把手教程)
SiliconCloud介绍 SiliconCloud 基于优秀的开源基础模型,提供高性价比的 GenAI 服务. 不同于多数大模型云服务平台只提供自家大模型 API,SiliconCloud上架了包 ...
- 使用inno setup 打包Pyinstaller生成的文件夹
背景:pyinstaller 6.5.0.Inno Setup 6.2.2 1. 需要先使用pyinstaller打包,生成包括exe在内的可执行文件夹 注意:直接使用pyinstaller打包,生成 ...
- 【YashanDB知识库】kettle从DM8的number类型同步到YashanDB的varchar类型,存入是科学计数法形式的数据
[标题]kettle从DM8的number类型同步到YashanDB的varchar类型,存入是科学计数法形式的数据 [问题分类]数据导入导出 [关键字]数据同步,number类型,科学计数法 [问题 ...
- Round #2022/12/10
问题 D:城市大脑 题目描述 杜老师正在编写杭州城市大脑智能引擎.杭州的道路可以被抽象成为一幅无向图.每条路的初始速度都是 \(1\ m/s\).杜老师可以使用 \(1\) 块钱让任意一条路的速度提升 ...
- Mmdetection dataset pipline
数据的加载顺序是上图(来自mmdetection官网)中的顺序进行,上图中只有一次padding,但是其实dataloader一共有两次padding,一次是pad,另外一次就是collect后,给模 ...
- CSS – Icon
前言 Icon 并不容易搞. 市场有许多平台支持 Icon, 有些收费有些免费. 有些 icon 很丰富, 有些很缺失. 尤其是在做网站的时候寻找 icon 是一个挺累的事情. 这篇就来聊聊 icon ...
- ASP.NET Core – Work with X509
前言 这篇主要是说如何用 ASP.NET Core 读写系统里的证书 Store 和创建一个证书, 还有使用证书做加密, 解密, 签名. 主要参考: C#数字证书编程总结 (读写证书 Store) E ...
- SpringMVC —— RESTful入门
RESTful入门案例 1.设定http请求动作(动词) @RequestMapping(value = "/users",method = RequestMethod.POS ...
- MyBatis——案例——查询-多条件查询-动态条件查询(关键字 if where)
动态条件查询 SQL语句会随着用户的输入或外部条件的变化而变化,我们称为 动态SQL MyBatis 对动态SQL有很强大的支撑: if choose(when,otherwise) ...