selenium自动化测试+OCR-获取图片页面小说
随着爬虫技术的发展,反爬虫技术也越来越高。
目前有些网站通过自定义字体库的方式实现反爬,主要表现在页面数据显示正常,但是页面获取到的实际数据是别的字符或者是一个编码。
这种反爬需要解析网站自己的字体库,对加密字符使用字体库对应字符替换。需要制作字体和基本字体间映射关系。
还有些网站通过图片加载内容的方式实现反爬,想要获取网页内容,可以结合使用OCR技术获取图片文字内容。
第一步:先获取网页内容截图
结合之前《selenium自动化测试-获取动态页面小说》相关的文章代码,改造下,封装成一个新方法,只获取小说网页内容截图,按章节ID分目录保存每页截图文件。
依旧采用拆分步骤细化功能模块封装方法编写代码,便于后续扩展功能模块,代码中缺少的封装方法代码,详情参考之前的《selenium自动化测试》文章。
def spider_novel_content_save_image(req_dict):
'''
@方法名称: 爬取小说章节明细内容,保存内容截图文件
@中文注释: 爬取小说章节明细内容,保存内容截图文件
@入参:
@param req_dict dict 请求容器
@出参:
@返回状态:
@return 0 失败或异常
@return 1 成功
@返回错误码
@返回错误信息
@param rsp_dict dict 响应容器
@作 者: PandaCode辉
@weixin公众号: PandaCode辉
@创建时间: 2023-09-26
@使用范例: spider_novel_content_save_image(req_dict)
''' try:
if (not type(req_dict) is dict):
return [0, "111111", "请求容器参数类型错误,不为字典", [None]]
# 章节目录文件名
json_name = req_dict['novel_name'] + '.json'
# 检查文件是否存在
if os.path.isfile(json_name):
print('json文件存在,不用重新爬取小说目录.')
else:
print('json文件不存在')
# 爬取小说目录
spider_novel_mulu(req_dict)
# 读取json文件
with open(json_name, 'r') as f:
data_str = f.read()
# 转换为字典容器
mulu_dict = json.loads(data_str) # 在列表中查找指定元素的下标,未完成标志下标
flag_index = mulu_dict['flag'].index('0')
print(flag_index)
# 章节总数
chap_len = len(mulu_dict['chap_url'])
# 在列表中查找指定元素的下标
print('章节总数:', chap_len) # 截图目录
screenshot_dir = os.path.join(os.path.dirname(__file__), 'screenshot')
if not os.path.exists(screenshot_dir):
os.makedirs(screenshot_dir) print('打开浏览器驱动')
open_driver()
# 循环读取章节
for chap_id in range(flag_index, chap_len):
print('chap_id : ', chap_id)
# 章节url
chap_url = mulu_dict['chap_url'][chap_id]
# 截图目录,根据章节ID分类保存
chap_id_dir = os.path.join(screenshot_dir, str(chap_id))
if not os.path.exists(chap_id_dir):
os.makedirs(chap_id_dir)
# 打开网址网页
print('打开网址网页')
driver.get(chap_url)
# 等待6秒启动完成
driver.implicitly_wait(6)
print('随机休眠')
# 随机休眠 暂停0-2秒的整数秒
time.sleep(random.randint(0, 2)) # 章节分页url列表初始化
page_href_list = []
# 根据url地址获取网页信息
chap_rst = get_html_by_webdriver(chap_url)
time.sleep(3)
if chap_rst[0] != 1:
# 跳出循环爬取
break
chap_html_str = chap_rst[3][0]
# 使用BeautifulSoup解析网页数据
chap_soup = BeautifulSoup(chap_html_str, "html.parser")
# 章节内容分页数和分页url
# 获取分页页码标签下的href元素取出
page_href_list_tmp = chap_soup.select("div#PageSet > a")
all_page_cnt = len(page_href_list_tmp)
print("分页页码链接数量:" + str(all_page_cnt))
# 去除最后/后面数字+.html
tmp_chap_url = re.sub(r'(\d+\.html)', '', chap_url)
for each in page_href_list_tmp:
if len(each) > 0:
chap_url = tmp_chap_url + str(each.get('href'))
print("拼接小说章节分页url链接:" + chap_url)
# 判断是否已经存在列表中
if not chap_url in page_href_list:
page_href_list.append(chap_url)
print("分页url链接列表:" + str(page_href_list)) # 网页长宽最大化,保证截图是完整的,不会出现滚动条
S = lambda X: driver.execute_script('return document.body.parentNode.scroll' + X)
driver.set_window_size(S('Width'), S('Height')) # 章节页码,首页
page_num = 1
# 章节内容截图
image_file = os.path.join(chap_id_dir, str(page_num) + '.png')
# 元素定位
chap_content_element = driver.find_element(By.ID, 'content')
print(chap_content_element)
# 元素截图
chap_content_element.screenshot(image_file) # 分页列表大于0
if len(page_href_list) > 0:
for chap_url_page in page_href_list:
print("chap_url_page:" + chap_url_page)
time.sleep(3) # 打开网址网页
print('打开网址网页')
driver.get(chap_url_page)
# 等待6秒启动完成
driver.implicitly_wait(6)
print('随机休眠')
# 随机休眠 暂停0-2秒的整数秒
time.sleep(random.randint(0, 2)) # 章节页码
page_num += 1
# 章节内容截图
image_file = os.path.join(chap_id_dir, str(page_num) + '.png')
# 元素定位
chap_content_element = driver.find_element(By.ID, 'content')
print(chap_content_element)
# 元素截图
chap_content_element.screenshot(image_file) # 爬取明细章节内容截图成功后,更新对应标志为-2-截图已完成
mulu_dict['flag'][chap_id] = '2'
print('关闭浏览器驱动')
close_driver() # 转换为json字符串
json_str = json.dumps(mulu_dict)
# 再次写入json文件,保存更新处理完标志
with open(json_name, 'w', encoding="utf-8") as json_file:
json_file.write(json_str)
print("再次写入json文件,保存更新处理完标志")
# 返回容器
return [1, '000000', '爬取小说内容截图成功', [None]] except Exception as e:
print('关闭浏览器驱动')
close_driver()
# 转换为json字符串
json_str = json.dumps(mulu_dict)
# 再次写入json文件,保存更新处理完标志
with open(json_name, 'w', encoding="utf-8") as json_file:
json_file.write(json_str)
print("再次写入json文件,保存更新处理完标志")
print("爬取小说内容异常," + str(e))
return [0, '999999', "爬取小说内容截图异常," + str(e), [None]]
第二步:通过OCR接口识别截图
结合之前《PaddleOCR学习笔记3-通用识别服务》和《selenium自动化测试-获取动态页面小说》相关的文章代码,改造下,封装成一个新方法,通过OCR接口识别小说网页内容截图,然后写入文件保存。
依旧采用拆分步骤细化功能模块封装方法编写代码,便于后续扩展功能模块,代码中缺少的封装方法代码,详情参考之前的《selenium自动化测试》文章。
# 模拟http请求
def requests_http(file_path, file_name, url):
full_file_path = os.path.join(file_path, file_name)
# 请求参数,文件名
req_data = {'upload_file': open(full_file_path, 'rb')} # 模拟http请求
rsp_data = requests.post(url, files=req_data)
# print(rsp_data.text)
result_dict = json.loads(rsp_data.text)
# print(result_dict)
return result_dict def spider_novel_content_by_ocr(req_dict):
'''
@方法名称: 通过OCR接口获取小说章节明细内容文字
@中文注释: 读取章节列表json文件,通过OCR接口获取小说章节明细内容文字,保存到文本文件
@入参:
@param req_dict dict 请求容器
@出参:
@返回状态:
@return 0 失败或异常
@return 1 成功
@返回错误码
@返回错误信息
@param rsp_dict dict 响应容器
@作 者: PandaCode辉
@weixin公众号: PandaCode辉
@创建时间: 2023-09-26
@使用范例: spider_novel_content_by_ocr(req_dict)
''' try:
if (not type(req_dict) is dict):
return [0, "111111", "请求容器参数类型错误,不为字典", [None]]
# 章节目录文件名
json_name = req_dict['novel_name'] + '.json'
# 检查文件是否存在
if os.path.isfile(json_name):
print('json文件存在,不用重新爬取小说目录.')
else:
print('json文件不存在')
# 爬取小说目录
spider_novel_mulu(req_dict)
# 读取json文件
with open(json_name, 'r') as f:
data_str = f.read()
# 转换为字典容器
mulu_dict = json.loads(data_str)
"""
关于open()的mode参数:
'r':读
'w':写
'a':追加
'r+' == r+w(可读可写,文件若不存在就报错(IOError))
'w+' == w+r(可读可写,文件若不存在就创建)
'a+' ==a+r(可追加可写,文件若不存在就创建)
对应的,如果是二进制文件,就都加一个b就好啦:
'rb' 'wb' 'ab' 'rb+' 'wb+' 'ab+'
"""
file_name = req_dict['novel_name'] + '.txt'
# 在列表中查找指定元素的下标,2-截图完成,标志下标
flag_index = mulu_dict['flag'].index('2')
print(flag_index)
# 2-截图完成,标志下标为0,则为第一次爬取章节内容,否则已经写入部分,只能追加内容写入文件
# 因为章节明细内容很多,防止爬取过程中间中断,重新爬取,不用重复再爬取之前成功写入的数据
if flag_index == 0:
# 打开文件,首次创建写入
fo = open(file_name, "w+", encoding="utf-8")
else:
# 打开文件,再次追加写入
fo = open(file_name, "a+", encoding="utf-8")
# 章节总数
chap_len = len(mulu_dict['chap_url'])
# 在列表中查找指定元素的下标
print('章节总数:', chap_len) # 截图目录
screenshot_dir = os.path.join(os.path.dirname(__file__), 'screenshot')
# 循环读取章节
for chap_id in range(flag_index, chap_len):
# 识别成功标志
succ_flag = False
# 章节标题
chap_title = mulu_dict['chap_title'][chap_id]
print('chap_id : ', chap_id)
# # 写入文件,章节标题
fo.write("\n" + chap_title + "\r\n")
# 截图目录,根据章节ID分类保存
chap_id_dir = os.path.join(screenshot_dir, str(chap_id))
# 列出目录下的所有文件和文件夹
file_list = os.listdir(chap_id_dir)
# 章节目录下文件列表大于0
if len(file_list) > 0:
for file_name in file_list:
print("file_name:" + file_name)
time.sleep(3) url = "http://127.0.0.1:5000/upload/"
# 模拟http请求
result_dict = requests_http(chap_id_dir, file_name, url)
print(result_dict)
# 识别成功
if result_dict['error_code'] == '000000':
succ_flag = True
result_list = result_dict['result']
for data in result_list:
print(data['text'])
# 将识别结果,逐行写入文件,章节内容
fo.write(data['text'] + "\n")
else:
succ_flag = False
print('识别失败异常.')
# 识别成功则更新
if succ_flag:
# 爬取明细章节内容成功后,更新对应标志为-1-已完成
mulu_dict['flag'][chap_id] = '1'
print('关闭浏览器驱动')
close_driver()
# 关闭文件
fo.close()
print("循环爬取明细章节内容,写入文件完成")
# 转换为json字符串
json_str = json.dumps(mulu_dict)
# 再次写入json文件,保存更新处理完标志
with open(json_name, 'w', encoding="utf-8") as json_file:
json_file.write(json_str)
print("再次写入json文件,保存更新处理完标志")
# 返回容器
return [1, '000000', '爬取小说内容成功', [None]] except Exception as e:
print('关闭浏览器驱动')
close_driver()
# 关闭文件
fo.close()
# 转换为json字符串
json_str = json.dumps(mulu_dict)
# 再次写入json文件,保存更新处理完标志
with open(json_name, 'w', encoding="utf-8") as json_file:
json_file.write(json_str)
print("再次写入json文件,保存更新处理完标志")
print("爬取小说内容异常," + str(e))
return [0, '999999', "爬取小说内容异常," + str(e), [None]]
第三步:运行效果
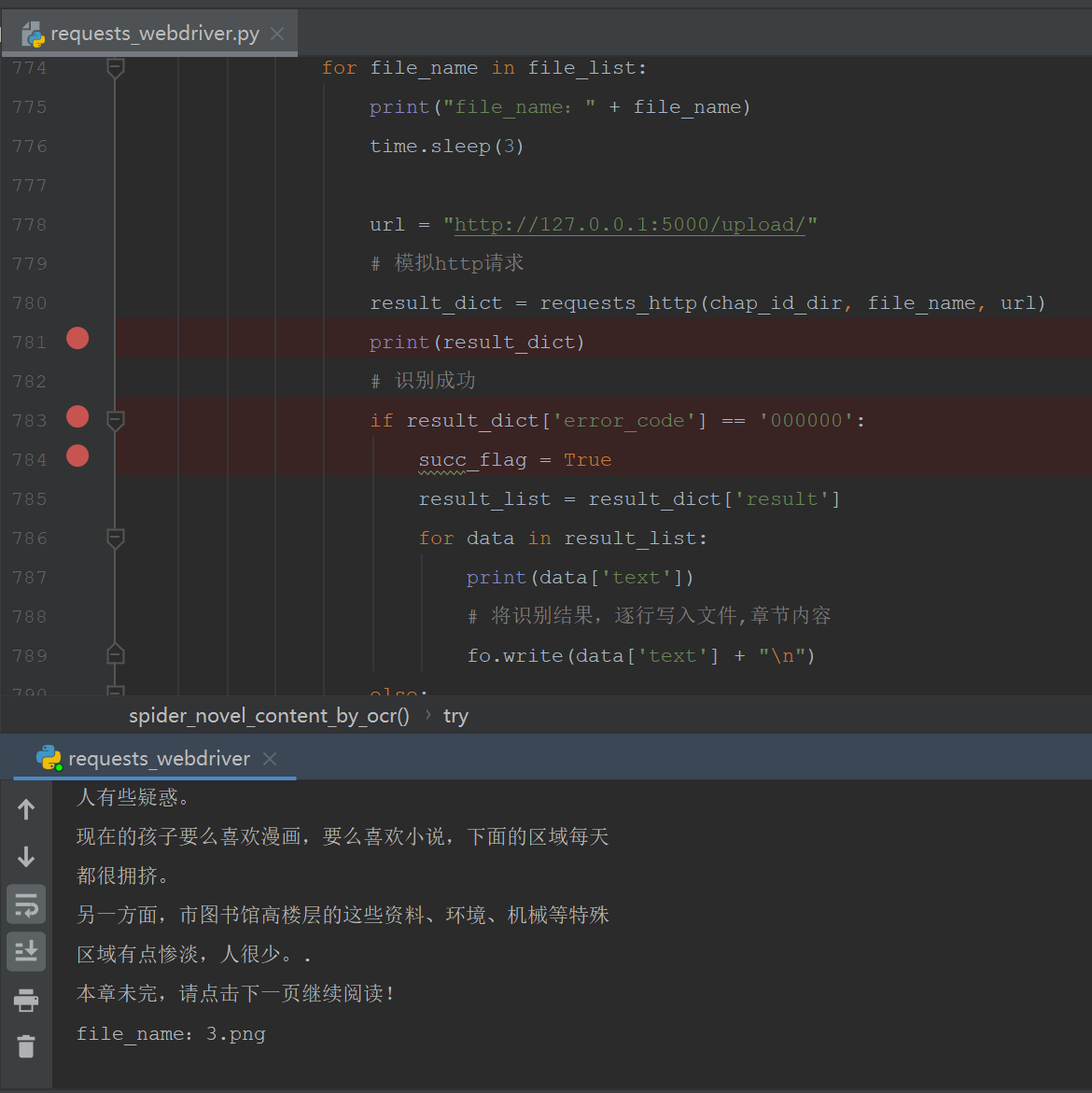
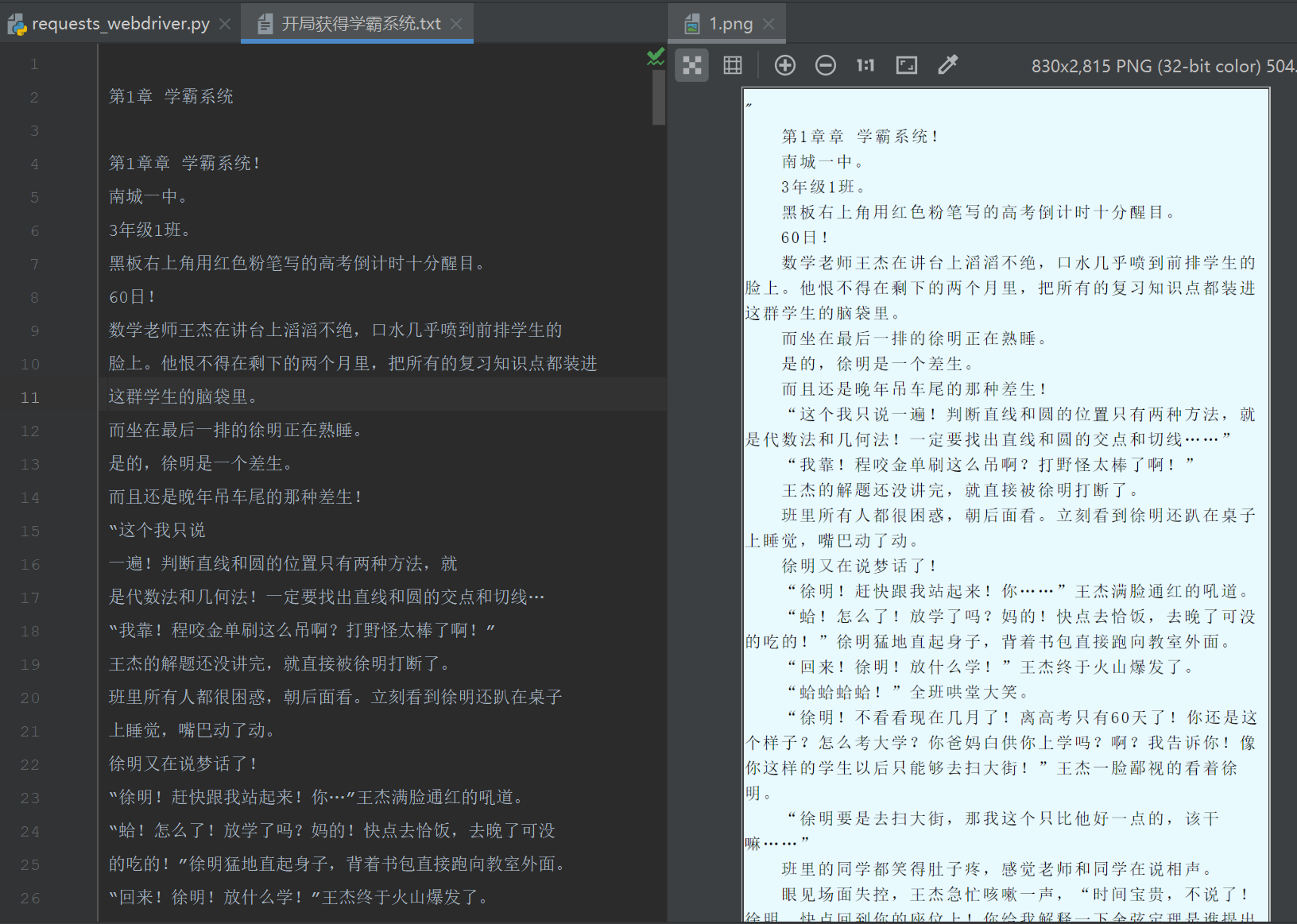
第四步:总结
目前很多网站都有基本的反爬策略,常见就是验证码、JS参数加密这两种。
爬虫本身会对网站增加一定的压力,所以也应该合理设定爬取速率,尽量避免对目标网站造成麻烦,影响网站正常使用,一定注意自己爬虫的姿势。
敬畏法律,遵纪守法,从我做起。

最后说明:上述文章仅供学习参考,请勿用于商业用途,感谢阅读。
selenium自动化测试+OCR-获取图片页面小说的更多相关文章
- selenium自动化测试爬取动态页面大全
目录 一:浏览器信息测试 二:查找结点 三:测试动作 四:获取节点信息 五:切换子页面Frame 六,延时请求 七:前进和后退 八:Cookies 八:选项卡处理 九:捕获异常 这里之讲解用法,安 ...
- Python+Selenium使用Page Object实现页面自动化测试
Page Object模式是Selenium中的一种测试设计模式,主要是将每一个页面设计为一个Class,其中包含页面中需要测试的元素(按钮,输入框,标题 等),这样在Selenium测试页面中可以通 ...
- 使用selenium的方式获取网页中图片的链接和网页的链接,来判断是否是死链(二)
上一篇使用Java正则表达式来判断和获取图片的链接以及跳转的网址,这篇使用selenium的自带的API(getAttribute)来获取网页中指定的内容 实现内容:获取下面所有图片的链接地址以及跳转 ...
- selenium获取新页面标签页(只弹出一个新页面的切换)
selenium获取新页面标签页(只弹出一个新页面的切换) windows = driver.current_window_handle #定位当前页面句柄 all_handles = driver. ...
- 《手把手教你》系列技巧篇(四十五)-java+ selenium自动化测试-web页面定位toast-上篇(详解教程)
1.简介 在使用appium写app自动化的时候介绍toast的相关元素的定位,在Web UI测试过程中,也经常遇到一些toast,那么这个toast我们这边如何进行测试呢?今天宏哥就分两篇介绍一下. ...
- 《手把手教你》系列技巧篇(四十六)-java+ selenium自动化测试-web页面定位toast-下篇(详解教程)
1.简介 终于经过宏哥的不懈努力,偶然发现了一个toast的web页面,所以直接就用这个页面来夯实一下,上一篇学过的知识-处理toast元素. 2.安居客 事先声明啊,宏哥没有收他们的广告费啊,纯粹是 ...
- Selenium自动化测试Python三:WebDriver进阶
WebDriver 进阶 欢迎阅读WebDriver进阶讲义.本篇讲义将会重点介绍Selenium WebDriver API的重点使用方法,以及使用模块化和参数化进行自动化测试的设计. WebDri ...
- Selenium自动化测试第二天(下)
如有任何学习问题,可以添加作者微信:lockingfree 目录 Selenium自动化测试基础 Selenium自动化测试第一天(上) Selenium自动化测试第一天(下) Selenium自动化 ...
- python自动化登录获取图片登录验证码
主要记录一下:图片验证码1.获取登录界面的图片2.获取验证码位置3.在登录页面截取验证码保存4.调用百度api识别(目前准确率较高的识别图片api)本次登录的系统页面,可以看到图片验证码的位置登录页面 ...
- 《手把手教你》系列技巧篇(五十五)-java+ selenium自动化测试-上传文件-下篇(详细教程)
1.简介 在实际工作中,我们进行web自动化的时候,文件上传是很常见的操作,例如上传用户头像,上传身份证信息等.所以宏哥打算按上传文件的分类对其进行一下讲解和分享. 2.为什么selenium没有提供 ...
随机推荐
- Qt数据库应用19-图片转pdf
一.前言 用户的需求真的是千奇百怪,刚做完不同页面横向纵向排版的需求,又来个需要图片转pdf的需求,提供静态函数直接使用. 经过这么些年的社会的毒打,我的原则是:用户是上帝和大爷,尽量站在用户的角度换 ...
- Qt编写地图综合应用42-离线轮廓图
一.前言 离线轮廓图使用起来,就没有在线轮廓图方便了,在线的可以直接传入名称拿到,离线的只能自己绘制了,一般需要用区域轮廓图下载器将你需要的区域下载好对应的js文件,其实就是一堆坐标点集合数组,这些数 ...
- Qt音视频开发40-人脸识别离线版
一.前言 上一篇文章写了在线调用人脸识别api进行处理,其实很多的客户需求是要求离线使用的,尤其是一些事业单位,严禁这些刷脸数据外泄上传到服务器,尽管各个厂家号称严格保密这些数据,但要阻止这些担心,唯 ...
- 微信小游戏直播在Android端的跨进程渲染推流实践
本文由微信开发团队工程师"virwu"分享. 1.引言 近期,微信小游戏支持了视频号一键开播,将微信升级到最新版本,打开腾讯系小游戏(如跳一跳.欢乐斗地主等),在右上角菜单就可以看 ...
- 创建Windows service使用FluentScheduler定时刷新网页
我们都知道iis的程序池默认的闲置回收时间是20分钟, 如果是自己的服务器,我们可以设置成0,闲置不回收. 这样网站就不会出现每隔20分钟没有访客访问就出现打开非常慢的情况. 但是,如果个别网站不是用 ...
- React基础笔记1
官网:https://react.docschina.org/ 一.认知React 概述 React 起源于 Facebook(脸书) 的内部项目,它是一个用于构建用户界面的 javascript 库 ...
- 如何快速的开发一个完整的iOS直播app(礼物篇)
搭建礼物列表 使用modal,设置modal样式为custom,就能做到从小往上显示礼物列表,并且能看见前面的直播界面 礼物模型设计 一开始创建3个礼物模型,保存到数组,传入给礼物View展示,本来礼 ...
- superset 1.3 hello world 开发实录
参考网址: https://superset.apache.org/docs/installation/building-custom-viz-plugins 实际操作: 因为内容是从hub上下载的: ...
- 耳分解、双极定向和 P9394 Solution
耳分解 设无向图 \(G'(V',E')\subset G(V,E)\),简单路径或简单环 \(P:x_1\to \dots \to x_k\) 被称为 \(G\) 关于 \(G'\) 的耳,当且仅当 ...
- FLink17--全窗口聚合方法1--ApplyWindowApp
一.依赖 二.代码 package net.xdclass.class11; import java.util.List; import java.util.stream.Collectors; im ...