ClickHouse之基础使用
[安装]
[YUM]
1.添加官方存储库
sudo yum install -y yum-utils
sudo yum-config-manager --add-repo https://packages.clickhouse.com/rpm/clickhouse.repo
sudo yum install -y clickhouse-server clickhouse-client sudo /etc/init.d/clickhouse-server start
clickhouse-client # or "clickhouse-client --password" if you set up a password.
2.安装
sudo yum install clickhouse-server clickhouse-client
3.启动服务
/etc/init.d/clickhouse-server start
手动启动:
clickhouse-server --config-file=/etc/clickhouse-server/config.xml
日志文件将输出在/var/log/clickhouse-server/文件夹。
检查/etc/clickhouse-server/config.xml中的配置。
4.客户端链接使用
clickhouse-client #指定端口连接
clickhouse-client --port 9020
5.修改端口与远程连接
ClickHouse安装后,默认client连接端口是9000
默认配置文件是只读, 首先需要修改配置文件权限:
chmod u+w /etc/clickhouse-server/config.xml
<!-- Port for interaction by native protocol with:
- clickhouse-client and other native ClickHouse tools (clickhouse-benchmark, clickhouse-copier);
- clickhouse-server with other clickhouse-servers for distributed query processing;
- ClickHouse drivers and applications supporting native protocol
(this protocol is also informally called as "the TCP protocol");
See also 'tcp_port_secure' for secure connections.
-->
<tcp_port>9020</tcp_port>
tcp_port 端口进行修改
远程连接:
找到<listen_host>::</listen_host>的配置项,取消注释,这样就同时支持IPv4和IPv6了。
也可以选择取消注释<listen_host>0.0.0.0</listen_host>,就仅支持IPv4,不允许IPv6。
使用
常用命令汇总:
字段类型表修改) RENAME DICTIONARY dictionary.old_table to dictionary.new_table; 查询数据数量)
select count() from db_name.table_name;
USING使用:
select uniq(number_id) as '玩家数量' from player_all p
left join player_register_all pr
using number_id, app_id
where toDate(data_time) = '2022-07-15'
and p.app_id=[APPID]
AND pr.app_id=[APPID] 这里使用到的USING, 当两个关联的表中出现相同字段名称进行关联的时候, 可以简写成using的方式
==================================================================================================================================================================
数据字段dictionary引擎)
数据字典是clickhouse提供的一种简单 实用的存储媒介,以键值和属性映射的形式定义数据。字典中的数据会主动或被动加载到内存之中,并支持动态更新。由于字典数据常驻内存特性,比较适合保存常量或者经常使用的维度表数据,以避免不必要的JOIN数据。
数据字典分为内置和扩展两种形式,内置数据字典是以clickhouse默认自带的字典;外部字典是通过用户自定义配置实现的字典,也可以从不同源(ClickHouse,MySQL或通用的ODBC)中获取数据。
Clickhouse是外部数据字典来处理多维数据架构,早期的clickhouse版本适用XML配置,在新版本中ClickHouse有了显着的进步,可以使用DDL语句来定义字典。
建表:
CREATE DICTIONARY dict( key_column UInt64 DEFAULT 0, value_column String DEFAULT 'a' ) PRIMARY KEY key_column SOURCE(CLICKHOUSE(HOST 'localhost' PORT 9000 USER 'default' TABLE 't_dict' PASSWORD '' DB 'datasets')) LIFETIME(MIN 1 MAX 10) LAYOUT(HASHED());
或
CREATE TABLE %table_name% (%fields%) engine = Dictionary(%dictionary_name%)`
内置字典
ClickHouse目前只有一种内置字典——Yandex.Metrica字典。从名称上可以看出,这是用在ClickHouse自家产品上的字典,而它的设计意图是快速存取geo地理数据。但较为遗憾的是,由于版权原因Yandex并没有将geo地理数据开放出来。这意味着ClickHouse目前的内置字典,只是提供了字典的定义机制和取数函数,而没有内置任何现成的数据。所以内置字典的现状较为尴尬,需要遵照它的字典规范自行导入数据。
外部扩展字典
外部扩展字典是以插件形式注册到ClickHouse中的,由用户自行定义数据模式及数据来源。目前扩展字典支持7种类型的内存布局和4类数据来源。相比内容十分有限的内置字典,扩展字典才是更加常用的功能。
扩展字典的配置文件由config.xml文件中的dictionaries_config配置项指定:
在默认的情况下,ClickHouse会自动识别并加载/etc/clickhouse-server目录下所有以_dictionary.xml结尾的配置文件。同时ClickHouse也能够动态感知到此目录下配置文件的各种变化,并支持不停机在线更新配置文件。在单个字典配置文件内可以定义多个字典,其中每一个字典由一组dictionary元素定义。在dictionary元素之下又分为5个子元素,均为必填项,它们完整的配置结构如下所示:

在上述结构中,主要配置的含义如下。
name:字典的名称,用于确定字典的唯一标识,必须全局唯一,多个字典之间不允许重复。
structure:字典的数据结构。
layout:字典的类型,它决定了数据在内存中以何种结构组织和存储。目前扩展字典共拥有7种类型。
source:字典的数据源,它决定了字典中数据从何处加载。目前扩展字典共拥有文件、数据库和其他三类数据来源。
lifetime:字典的更新时间,扩展字典支持数据在线更新。
扩展字典的类型使用layout元素定义,目前共有7种类型。一个字典的类型,既决定了其数据在内存中的存储结构,也决定了该字典支持的key键类型。根据key键类型的不同,可以将它们划分为两类:一类是以flat、hashed、range_hashed和cache组成的单数值key类型,因为它们均使用单个数值型的id;另一类则是由complex_key_hashed、complex_key_cache和ip_trie组成的复合key类型。complex_key_hashed与complex_key_cache字典在功能方面与hashed和cache并无二致,只是单纯地将数值型key替换成了复合型key而已。
flat
flat字典是所有类型中性能最高的字典类型,它只能使用UInt64数值型key。顾名思义,flat字典的数据在内存中使用数组结构保存,数组的初始大小为1024,上限为500000,这意味着它最多只能保存500000行数据。如果在创建字典时数据量超出其上限,那么字典会创建失败。
有时候需要更新的立即生效,就需要手动进行字典的更新:
SYSTEM RELOAD DICTIONARIES; 或 SYSTEM RELOAD DICTIONARY 'dictionary_name' # 查看所有字典函数
SELECT name, status FROM system.dictionaries;
参考: https://clickhouse.com/docs/zh/sql-reference/statements/system
hashed
hashed字典同样只能够使用UInt64数值型key,但与flat字典不同的是,hashed字典的数据在内存中通过散列结构保存,且没有存储上限的制约。
range_hashed
range_hashed字典可以看作hashed字典的变种,它在原有功能的基础上增加了指定时间区间的特性,数据会以散列结构存储并按照时间排序。时间区间通过range_min和range_max元素指定,所指定的字段必须是Date或者DateTime类型。
cache
cache字典只能够使用UInt64数值型key,它的字典数据在内存中会通过固定长度的向量数组保存。定长的向量数组又称cells,它的数组长度由size_in_cells指定。而size_in_cells的取值大小必须是2的整数倍,如若不是,则会自动向上取为2的倍数的整数。
cache字典的取数逻辑与其他字典有所不同,它并不会一次性将所有数据载入内存。当从cache字典中获取数据的时候,它首先会在cells数组中检查该数据是否已被缓存。如果数据没有被缓存,它才会从源头加载数据并缓存到cells中。所以cache字典是性能最不稳定的字典,因为它的性能优劣完全取决于缓存的命中率(缓存命中率=命中次数/查询次数),如果无法做到99%或者更高的缓存命中率,则最好不要使用此类型。
complex_key_hashed
complex_key_hashed字典在功能方面与hashed字典完全相同,只是将单个数值型key替换成了复合型。
complex_key_cache
complex_key_cache字典同样与cache字典的特性完全相同,只是将单个数值型key替换成了复合型。现在仿照cache字典进行配置,将layout改为complex_key_cache并替换key类型
ip_trie
虽然同为复合型key的字典,但ip_trie字典却较为特殊,因为它只能指定单个String类型的字段,用于指代IP前缀。ip_trie字典的数据在内存中使用trie树结构保存,且专门用于IP前缀查询的场景,例如通过IP前缀查询对应的ASN信息。
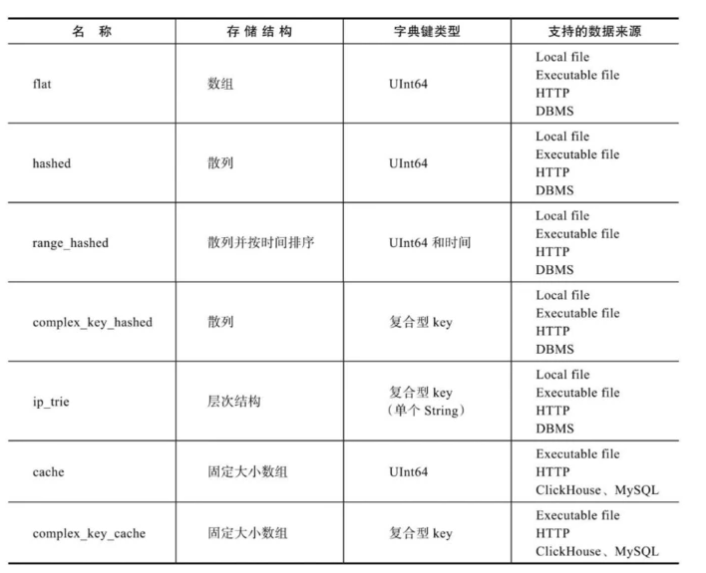
扩展字典的数据源
数据源使用source元素定义,它指定了字典的数据从何而来。现阶段,扩展字典支持3大类共计9种数据源,接下来会以更加体系化的方式逐一介绍它们。
文件类型
文件可以细分为本地文件、可执行文件和远程文件三类,它们是最易使用且最为直接的数据源,非常适合在静态数据这类场合中使用。
本地文件
本地文件使用file元素定义。其中,path表示数据文件的绝对路径,而format表示数据格式,例如CSV或者TabSeparated等。它的完整配置如下所示。

可执行文件
可执行文件数据源属于本地文件的变种,它需要通过cat命令访问数据文件。对于cache和complex_key_cache类型的字典,必须使用此类型的文件数据源。可执行文件使用executable元素定义。其中,command表示数据文件的绝对路径,format表示数据格式,例如CSV或者TabSeparated等。它的完整配置如下所示。

远程文件
远程文件与可执行文件类似,只是它将cat命令替换成了post请求,支持HTTP与HTTPS协议。远程文件使用http元素定义。其中,url表示远程数据的访问地址,format表示数据格式,例如CSV或者TabSeparated。它的完整配置如下所示。

数据库类型
相比文件类型,数据库类型的数据源更适合在正式的生产环境中使用。目前扩展字典支持MySQL、ClickHouse本身及MongoDB三种数据库。
MySQL:
<dictionary>
<name>test_mysql_dict</name>
<source>
<mysql>
<port>3306</port>
<user>root</user>
<password>chen2895161</password>
<replica>
<host>192.168.59.133</host>
<priority>1</priority>
</replica>
<db>gmall</db>
<table>t_organization</table>
<!--
<where>id=1</where>
-->
<invalidate_query>select updatetime from t_organization where id = 8</invalidate_query>
</mysql>
</source> <layout>
<flat/>
</layout> <structure>
<id>
<name>id</name>
</id> <attribute>
<name>code</name>
<type>String</type>
<null_value></null_value>
</attribute> <attribute>
<name>name</name>
<type>String</type>
<null_value></null_value>
</attribute> <attribute>
<name>updatetime</name>
<type>DateTime</type>
<null_value></null_value>
</attribute> </structure> <lifetime>
<min>300</min>
<max>360</max>
</lifetime> </dictionary>
其中,各配置项的含义分别如下。
❑ port:数据库端口。
❑ user:数据库用户名。
❑ password:数据库密码。
❑ replica:数据库host地址,支持MySQL集群。
❑ db:database数据库。
❑ table:字典对应的数据表。
❑ where:查询table时的过滤条件,非必填项。
❑ invalidate_query:指定一条SQL语句,用于在数据更新时判断是否需要更新,非必填项。
ClickHouse:
扩展字典支持将ClickHouse数据表作为数据来源
<dictionary>
<name>test_ch_dict</name> <source>
<clickhouse>
<host>192.168.59.136</host>
<port>9000</port>
<user>default</user>
<password></password>
<db>default</db>
<table>t_organization</table>
<!--
<where>id=10</where>
-->
<invalidate_query>SELECT UpdateTime FROM t_organization WHERE ID = 1</invalidate_query>
</clickhouse>
</source> <layout>
<flat/>
</layout> <!--大小写敏感,需要与数据表字段对应-->
<structure>
<id>
<name>ID</name>
</id> <attribute>
<name>Code</name>
<type>String</type>
<null_value></null_value>
</attribute> <attribute>
<name>Name</name>
<type>String</type>
<null_value></null_value>
</attribute> <attribute>
<name>UpdateTime</name>
<type>DateTime</type>
<null_value></null_value>
</attribute>
</structure> <lifetime>
<min>300</min>
<max>360</max>
</lifetime> </dictionary>
其中,各配置项的含义分别如下。
❑ host:数据库host地址。
❑ port:数据库端口。
❑ user:数据库用户名。
❑ password:数据库密码。
❑ db:database数据库。
❑ table:字典对应的数据表。
❑ where:查询table时的过滤条件,非必填项。
❑ invalidate_query:指定一条SQL语句,用于在数据更新时判断是否需要更新,非必填项。
扩展字典的数据更新策略
扩展字典支持数据的在线更新,更新后无须重启服务。字典数据的更新频率由配置文件中的lifetime元素指定,单位为秒:

其中,min与max分别指定了更新间隔的上下限。ClickHouse会在这个时间区间内随机触发更新动作,这样能够有效错开更新时间,避免所有字典在同一时间内爆发性的更新。当min和max都是0的时候,将禁用字典更新。对于cache字典而言,lifetime还代表了它的缓存失效时间。
字典内部拥有版本的概念,在数据更新的过程中,旧版本的字典将持续提供服务,只有当更新完全成功之后,新版本的字典才会替代旧版本。所以更新操作或者更新时发生的异常,并不会对字典的使用产生任何影响。
不同类型的字典数据源,更新机制也稍有差异。总体来说,扩展字典目前并不支持增量更新。但部分数据源能够依照标识判断,只有在源数据发生实质变化后才实施更新动作。这个判断源数据是否被修改的标识,在字典内部称为previous,它保存了一个用于比对的值。ClickHouse的后台进程每隔5秒便会启动一次数据刷新的判断,依次对比每个数据字典中前后两次previous的值是否相同。若相同,则代表无须更新数据;若不同且满足更新频率,则代表需要更新数据。而对于previous值的获取方式,不同的数据源有不同的实现逻辑,
文件数据源
对于文件类型的数据源,它的previous值来自系统文件的修改时间,这和Linux系统中的stat查询命令类似:

当前后两次previous的值不相同时,才会触发数据更新。
注意点:
1.如果使用外部的字典, 必须使用layout来声明
参考:
ClickHouse之基础使用的更多相关文章
- ByteHouse:基于 ClickHouse 的实时计算能力升级
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 ByteHouse 是火山引擎数智平台旗下云原生数据分析平台,为用户带来极速分析体验,能够支撑实时数据分析和海量离 ...
- 基于 ByteHouse 构建实时数仓实践
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 随着数据的应用场景越来越丰富,企业对数据价值反馈到业务中的时效性要求也越来越高,很早就有人提出过一个概念: 数据的 ...
- 【大数据】Clickhouse基础知识
第1章 ClickHouse概述 1.1 什么是ClickHouse ClickHouse 是俄罗斯的Yandex于2016年开源的列式存储数据库(DBMS),主要用于在线分析处理查询(OLAP),能 ...
- 【clickhouse专栏】基础数据类型说明
本文是clickhouse专栏第五篇,更多内容请关注本号历史文章! 一.数据类型表 clickhouse内置了很多的column数据类型,可以通过查询system.data_type_families ...
- 彪悍开源的分析数据库-ClickHouse
https://zhuanlan.zhihu.com/p/22165241 今天介绍一个来自俄罗斯的凶猛彪悍的分析数据库:ClickHouse,它是今年6月开源,俄语社区为主,好酒不怕巷子深. 本文内 ...
- 列式数据库~clickhouse 副本集架构的搭建
clickhouse 搭建副本集 一 原理: 1 依赖ZK,ZK的基础上,ZK存储数据库元数据 2 使用复制表引擎创建复制表,包括ZK路径和副本名,相同ZK路径的表可以相互复制 3 复制表本身拥 ...
- ClickHouse 简单试用
ClickHouse 具有强劲的数据分析能力,同时支持标准sql 查询,内置了好多聚合参数 同时可以方便的使用表函数连接不同的数据源(url,jdbc,文件目录...) 测试使用docker安装 参考 ...
- SpringBoot2 整合 ClickHouse数据库,实现高性能数据查询分析
本文源码:GitHub·点这里 || GitEE·点这里 一.ClickHouse简介 1.基础简介 Yandex开源的数据分析的数据库,名字叫做ClickHouse,适合流式或批次入库的时序数据.C ...
- Linux系统:Centos7下搭建ClickHouse列式存储数据库
本文源码:GitHub·点这里 || GitEE·点这里 一.ClickHouse简介 1.基础简介 Yandex开源的数据分析的数据库,名字叫做ClickHouse,适合流式或批次入库的时序数据.C ...
- ClickHouse
ClickHouse 是俄罗斯的Yandex于2016年开源的列式存储数据库(DBMS),主要用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告 1 安装前的准备1.1 Cent ...
随机推荐
- 【YashanDB知识库】YashanDB 开机自启
[问题分类] YashanDB 开机自启 [关键字] 开机自启,依赖包 [问题描述] 数据库所在服务器重启后只拉起monit.yasom.yasom进程,缺少yasdb进程: [问题原因分析] 数据库 ...
- axis2添加拦截器
项目背景: 2002年的某保险老项目,项目是部署了多个服务器,每个服务器有2到多个服务(每个服务的日志对应一个日志文件),外部对接是通过F5分发到随机服务器上来进行访问,正式出现问题或者看一些问题就需 ...
- 快速结束 git 输出行
在使用git命令查看操作记录等时,内容很多,想要输出内容快速结束 英文 Q 备注:通过英文Q快速结束
- Facebook Ads – 笔记
前言 记入一些小东西 参考 YouTube – 这是第一次广告投放回报做到11倍!Facebook广告高广告投资回报2023年终极策略密码分享 价值阶梯 先卖便宜 value 低的东西给客户,甚至免费 ...
- Flutter Engage China 开发者常见问题解答 | 下篇
再次感谢大家对 Flutter Engage China 活动 的关注和积极参与!我们在活动前后收到了很多来自开发者的反馈和问题,Flutter 团队和演讲嘉宾在直播 Q&A 环节中也针对部分 ...
- C语言数据类型、变量的输入和输出、进制转换
scanf标准函数可以从键盘得到数字并记录到存储区里,为了使用这个标准函数需要包含stdio.h这个头文件 在scanf函数调用语句里应该使用存储区的地址表示存储区:双引号里使用占位符表示存储区的类型 ...
- 1Before You Install Flask...Watch This! Flask Fridays #1
flask官网: https://flask.github.net.cn/ git官网: https://git-scm.com/ 建立文件: 建立虚拟环境.激活: source virt/Scrip ...
- 大语言模型(LLM)
大语言模型 LLM 人工智能 Artificial Intelligence 一门研究如何使计算机能够模拟和执行人类智能任务的科学和技术领域 是研究.开发用于模拟.延伸和扩展人的智能的理论.方法.技术 ...
- 忽略某个已经托管给git的文件,防止二次提交
# 执行命令将文件加入不提交队列 git update-index --assume-unchanged 你的文件路径 # 执行命令将文件取消加入不提交队列 git update-index --no ...
- vue2基于 vue-cropper插件对图片裁剪
<template> <div id="app"> <div class="model" v-show="model&q ...