JuiceFS v1.3-beta1:全面优化 SQL 数据库支持,十亿级元数据管理新选项
JuiceFS v1.3-beta 今天正式发布。在这个版本中,除了进行了大量使用体验优化和 bug 修复外,新增如下特性:
- 新增 Python SDK:这是一个从企业版移植过来的特性,旨在支持 FUSE 受限的场景,并优化某些高性能环境中的 I/O 性能。
- Windows 客户端可用性大幅优化:
- 修复了 Windows 客户端在 Windows API 调用和用户身份管理等方面存在的多个兼容性问题。
- 完善了工具支持,目前 debug、stat、info 等子命令已可在 Windows 平台下正常使用。
- 新增了对 -d 参数的支持,使 JuiceFS 可以直接作为系统服务进行挂载,无需再借助第三方工具。
- 新增二进制备份功能:可在多种元数据引擎中实现高效的备份和导入。性能提升的同时,还显著降低了内存占用。在 TiKV 上备份亿级别的元数据时,所需时间仅为原 JSON 格式的十分之一。
- 全面优化 SQL 支持:涵盖事务处理、并发控制、连接管理和缓存优化等多个方面,显著提升 SQL 元数据的处理效率。
- 支持 Apache Ranger:引入了与 Apache Ranger 的集成,在大数据场景给用户提供更加灵活和细粒度的权限控制方案。
除此之外,JuiceFS Gateway、sync 、元数据也有多项优化。本次版本更新,共有xx 名贡献者参与,合入 xxx 次代码。感谢每位贡献者的付出!
在近期的博客中,我们将逐一为大家介绍这些特性的原理及应用。
01 JuiceFS 元数据引擎简介
元数据管理直接关系到文件系统的性能与稳定性,JuiceFS 提供对多种具备事务支持的引擎的兼容能力。
- 文件型(如 SQLite) 适用于单机挂载的文件系统,适合百万级文件和以读取为主的场景。
- 内存 KV 类型(如 Redis) 支持多点挂载,适合文件数在一亿以内的场景。
- SQL 数据库(如 MySQL、PostgreSQL) 支持多点挂载,适合文件总数在十亿以内的场景。
- 分布式 KV(如 TiKV) 支持多点挂载,适合百亿级文件的场景。
其中,SQL 类数据库相较于其他类型的数据库,具备更强大的事务处理能力和一致性保障,且在企业核心应用中广泛使用,是 JuiceFS 的元数据存储的理想搭档。然而,由于 SQL 数据库的配置与调优相对复杂,使用者需具备一定的专业背景,这在一定程度上限制了其在社区中的普及。
JuiceFS 1.3 版本对 SQL 数据库的支持进行了全面的优化,涵盖事务处理、并发控制、连接管理和缓存优化等多个方面,显著提升 SQL 元数据的处理效率、系统稳定性和并发处理能力,使社区版在应对十亿级文件规模时表现更稳定高效。
接下来将围绕这些优化展开介绍,解析优化背后的设计思路与技术细节,并通过对比测试数据展示 JuiceFS 在 SQL 元数据模式下性能与稳定性的显著提升。
02 简化事务请求,性能提升 20%+
事务处理机制优化 (PR:#5377 )
为了提升 SQL 元数据在高并发下的处理效率,我们首先对事务执行流程进行了详细梳理。JuiceFS 使用 ORM(Object-Relational Mapping)来操作数据库,以支持多种不同 SQL 元数据类型。在执行读写事务时,JuiceFS 要确保在同一事务内,重复执行同一个 SQL 查询时得到一致的结果,即数据库的事务隔离级别(简称 Isolation Level,要求 Repeatable Read),因此 JuiceFS 使用了事务模板来统一执行所有的 SQL 语句。一个事务模板通常会包含以下几个步骤(每一步都是一次命令交互,即一个网络来回):
- 从连接池取得数据连接或创建一个新连接
- 设置事务隔离级别(通常是 set transaction_isolation 命令)
- 开始事务(通常是 begin 或 start transaction 命令)
- 执行第一个 SQL,并取得结果,进行相关处理
- 执行第二个 SQL,并取得结果,进行相关处理
- 事务提交(commit 命令)或事务回滚(rollback 命令)
- 归还数据库连接到连接池
仔细梳理后,发现有较多的事务中包含单个 SQL 查询语句,这时其实不需要去设置事务隔离级别,也不需要执行开始事务命令、事务提交或回滚命令,以省去这些交互和网络来回。基于此,我们为单个 SQL 增加了专门的处理模板,有效减少与 SQL 元数据的命令交互次数,减少网络来回,有利于提升文件系统访问性能,并有效减轻 SQL 元数据的压力。
MySQL 事务机制优化(#5432)
完成上一个优化后,我们发现不同的数据库对事务设置的实现存在差异。例如,要保证事务内同样的 SQL 查询返回同样的结果,将事务隔离级别设置为 Repeatable Read,PostgreSQL 中可以在开启事务的命令 (START TRANSACTION ISOLATION LEVEL REPEATABLE READ) 中指定当前事务隔离级别,无需额外的交互。
而 MySQL 则不能在开启事务的命令中指定,需要单独发送命令 (SET TRANSACTION_ISOLATION …) ,进一步分析后,我们发现不需要在每个事务开始之前就指定事务隔离级别,只需要在连接建立后执行一次即可,从而避免了每次事务开始前重复设置隔离级别。此优化仅作用于 MySQL 元数据,进一步优化了事务处理机制的效率。
下面我们来简单验证一下效果,以 MySQL 元数据为例,我们通过查看名为 Questions 的全局统计指标(表示客户端收到网络交互请求次数)来评估性能。可以通过 show global status 命令来查询该指标,测试过程为:
- 首次查询 MySQL 中当前的 Questions 统计值
- 创建 10000 个文件,然后删除 10000 个文件
- 再次查询 MySQL 中当前的 Questions 统计值,计算增量
测试脚本如下(仅供参考):
#!/bin/bash
/usr/local/mysql/bin/mysql -u jfs -pjfs \
-e "show global status like 'question%'"
for f in {1..10000};
do
touch testfile_${f}
done
rm -fr testfile_*
/usr/local/mysql/bin/mysql -u jfs -pjfs \
-e "show global status like 'question%'"
我们通过比较 JuiceFS 1.23 和 1.3 版本下 Questions 指标增量值的差异,同样的业务逻辑及业务量的压测下,指标值下降表示有效地减少了网络交互。
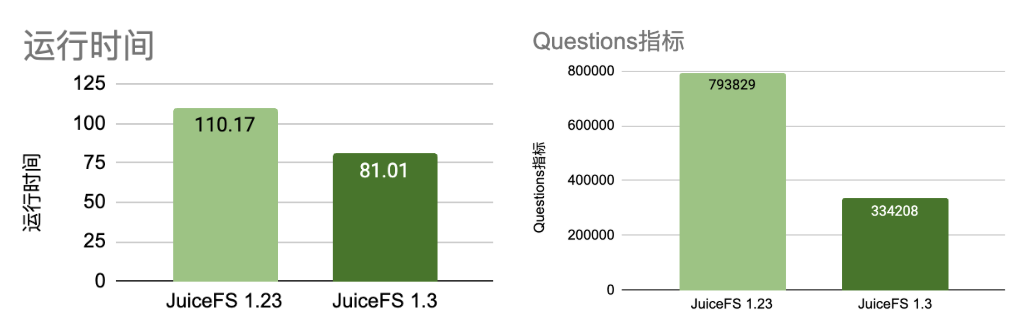
从测试结果可以看出,Questions 指标减少了超过 50%,整体执行时间也缩短了约 30%。由于测试环境中 MySQL 与客户端部署在同一台机器,采用本地连接,网络交互优化的效果相对有限。如果在实际的网络环境中(即 MySQL 和客户端分别部署在不同主机),这一优化在执行时间上的提升将更加显著。
03 优化锁,10 倍提升单目录多并发性能
并发处理机制优化(#5460)
在文件系统中,当创建或删除一个文件时,需要同时更新其所在目录的相关重要信息 (比如 NLINK 值),并保证文件和目录操作的事务性。由于不同类型的元数据具有不同的事务并发能力,一些 Key-Value 类型的元数据的并发机制并不健壮,因此在 1.3 版本之前,系统统一在客户端进行目录级的并发控制,即操作一个文件时,同步锁定其所在目录,保证同一时间内同一目录只能有一个会话进行文件的创建或删除操作,这导致了大目录的并发能力比较弱。
然而以 MySQL/PostgreSQL 为代表的 SQL 元数据有非常强的后端一致性保障能力,可以通过其原生的并发处理机制来提升大目录的并发性能。
仍以目录的 NLINK 属性为例,在 Key-Value 中进行更新时,由于没有足够的后端保障,因此需要挂载点锁定目录,查询取得当前的 NLINK 值,然后加一或减一后再写回去。但当后端是 MySQL 或 PostgreSQL 时,可以使用 “update … set NLINK = NLINK + 1 where …” 这样的原子操作去维护 NLINK 属性,就不再需要提前锁定目录,从而可以极大地提升大目录的并发处理能力。
经过此优化后,1.3 版本的单目录并发能力可达之前版本的 10 倍以上。此优化仅对 MySQL 和 PostgreSQL 有效,其他非 SQL 类型的元数据依旧需要现有的客户端目录锁定保护机制。
QUOTA 相关死锁优化 (#5706)
该问题由社区用户反馈,开启 QUOTA 限额功能时,系统会异步逐层向上统计各级目录的空间使用量,原先的逻辑未考虑到多个目录的更新顺序问题,在 1.3 版本中已经优化和完善逻辑,并且得到该用户的确认回复。
为了验证目录并发度的提升,下面我们使用 JuiceFS 客户端程序自带的 mdtest 工具来进行压测。测试中设置较小的目录深度,使用较高的并发和较大的单目录文件数。需要注意的是,此测试对 MySQL 的资源要求会比较高。压测命令如下:
./juicefs mdtest META_URL testdir1 --depth=1 --dirs=2 --files=5000 --threads 50 --write 8192
不同版本的测试结果如下:
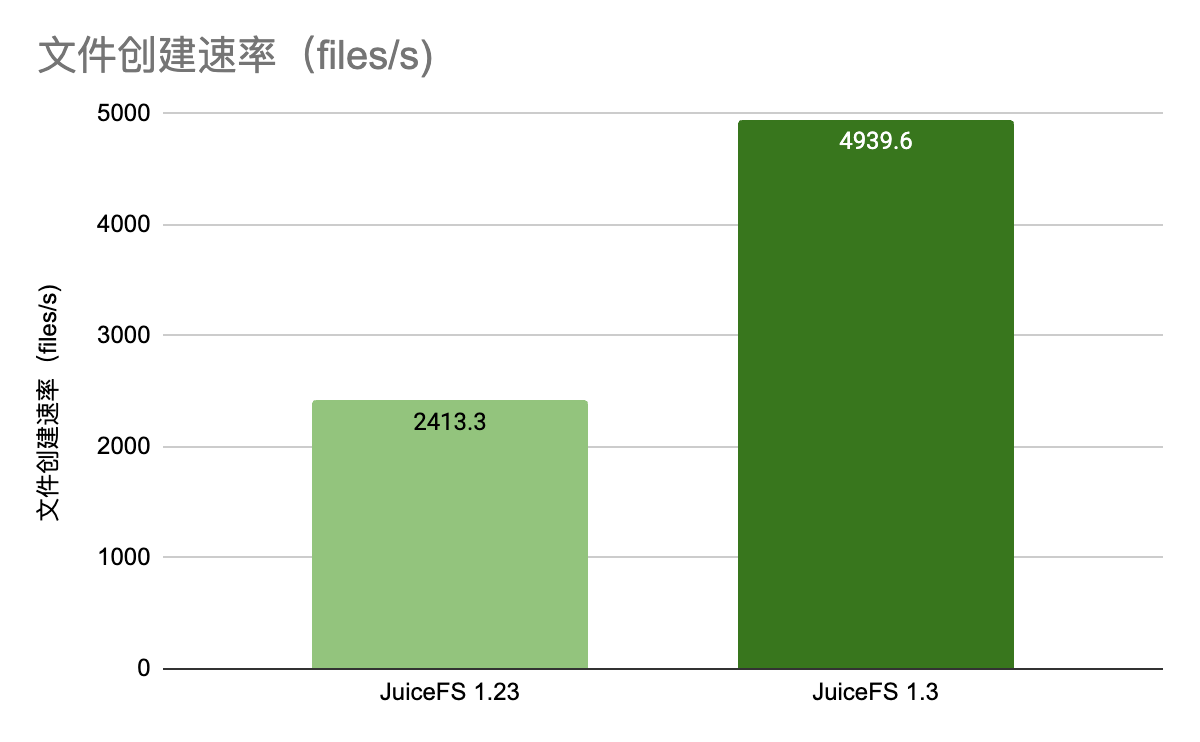
可以看到,1.3 相较于 1.23 版本有一倍以上的提升。由于是本地压测,并且使用了 50 个并发来测试三个目录,单目录的并发压力不算大,提升效果不算明显。如果是在网络环境中,并且使用更高的并发压测更少的目录,可以看到更明显的提升效果。
下面我们来测试 100 并发压测单个目录的情况,测试命令变更为:
./juicefs mdtest META_URL testdir1 --depth=0 --dirs=1 --files=1000 --threads 100 --write 8192
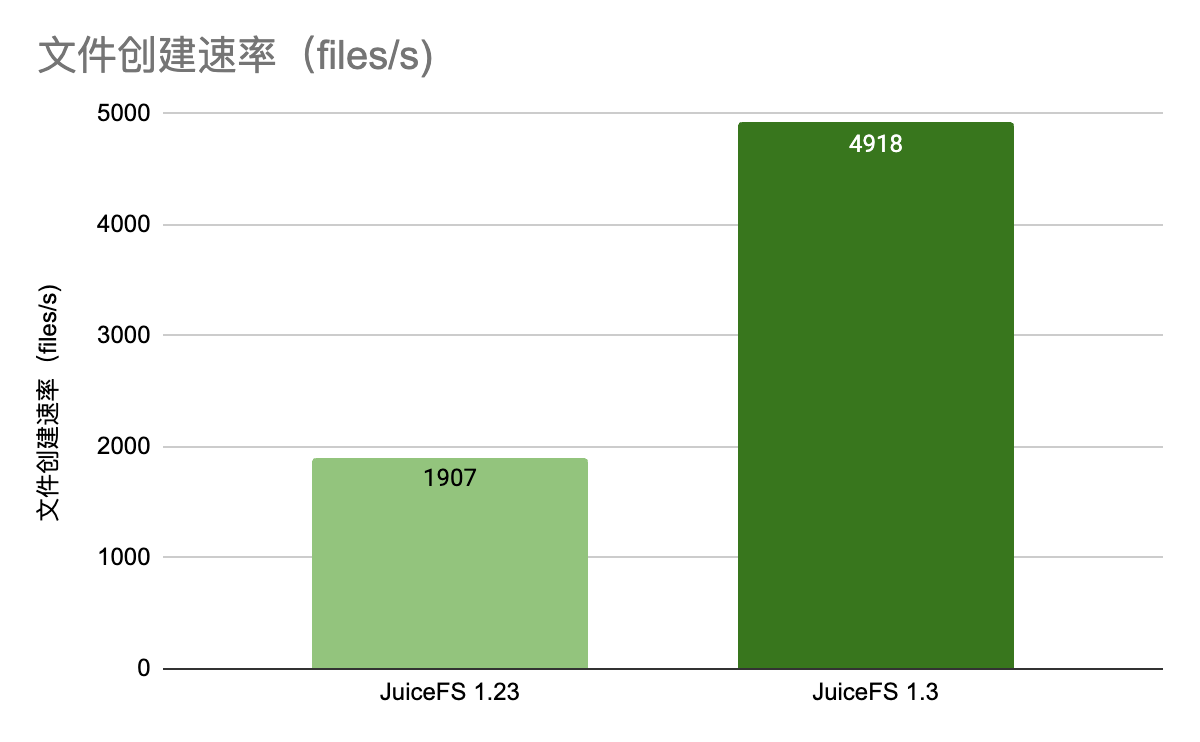
可以看到提高并发减少目录后,1.3 相较于1.23 的提升效果更明显。
接下来我们来测试元数据跨网络场景下的效果,测试结果如下:
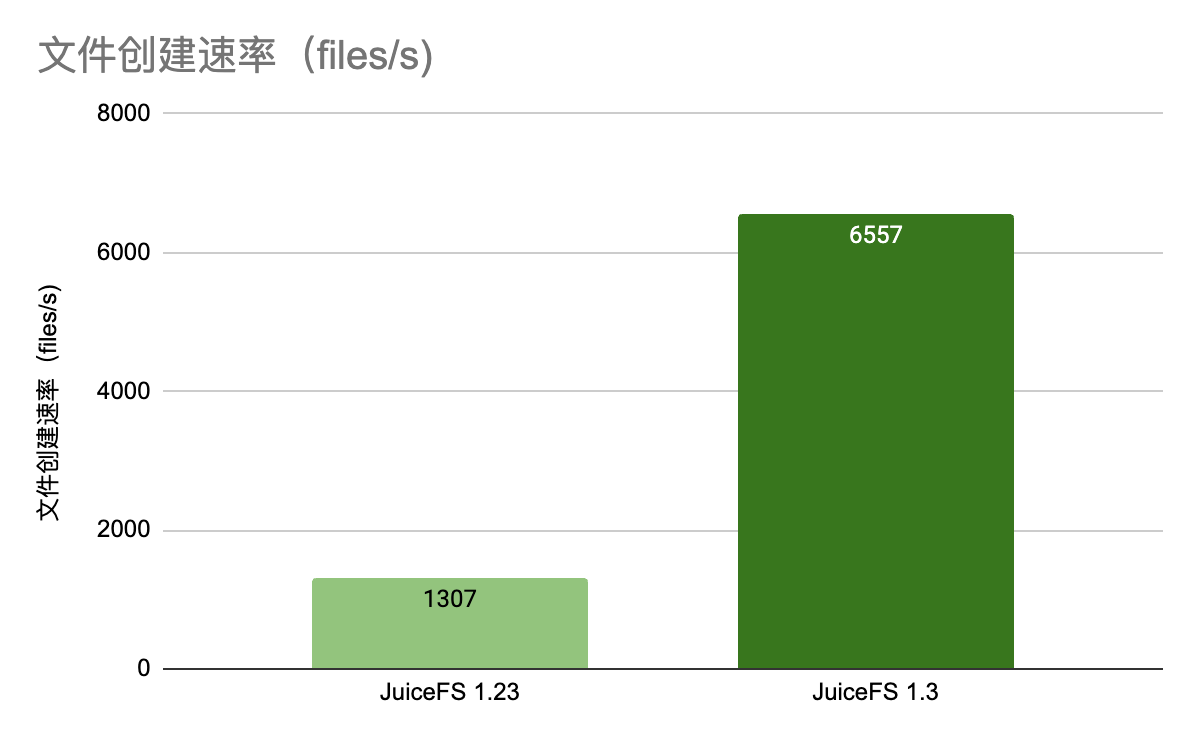
可以看到,在跨网络的场景下,1.3 版本中单目录高并发的吞吐是 1.23 版本的 5 倍左右,这时元数据所在机器的 8v CPU 被打满,如果提升资源规格,可以继续提升到 10 倍左右。欢迎广大社区用户在各自环境中多做压测并反馈测试结果。
04 连接处理机制优化,灵活配置连接参数提升稳定性
数据库连接数控制 (#5512)
由于元数据需要事务支持,一个事务通常包含多个 SQL 请求,只有当所有 SQL 都处理完成后,数据库连接才能被归还到连接池。当客户端的文件操作并发比较高时,可能会创建非常多的数据库连接。大量连接和并发请求发送到数据库后端,可能对元数据服务的稳定性造成压力。考虑到一个文件系统可能有成百上千个客户端挂载点,数据库的连接总数可能会超出可以承受的极限。因此,需要限制每个客户端的数据库连接数,并根据客户端数量合理配置数据库后端。为了应对这个挑战,JuiceFS 1.3 新增了4个 SQL Meta URL 选项,用来控制挂载点到数据库的连接行为:
- max-open-conns:限制到数据库的最大连接数
- max-idle-conns:最大的空闲连接数,超过将会主动断开一些连接
- max-idle-time:最长的连接空闲等待时间,如果一直和数据库无交互会主动断开连接
- max-life-time:连接生命周期,同一连接使用过久可能会有资源泄露,销毁可清理
Go 语言的数据库交互 (database/sql) 模块提供了相关的 API 接口来设置这些特性,允许通过配置而不改动代码来控制数据库的连接行为。以 MySQL 元数据为例,我们在 Meta URL 中增加上述参数来控制挂载点到 MySQL 的最大连接数,这个示例中为 10:
mysql://jfs:jfs@(localhost:3306)/juicefs?max_open_conns=10
这里的 Meta URL 格式就是数据库连接的 URL,更多的连接参数可以参考各数据库的 Go 驱动的实现文档,不同的数据库选项名称各不相同,Redis 和 TiKV 也有其特定的选项(可以查阅相关驱动的文档),可以用同样的方法来指定。
优化 Dump 连接消耗(#5930)
Dump 功能可用于在不同元数据引擎之间迁移数据,也是不同的文件系统之间迁移数据的重要手段。为了加快迁移效率,可以设定一个较大的并发线程数。此前,每个线程都会独占一个或多个数据库连接,容易导致线程数超出限制。1.3 版本对此进行了优化,使得在较少的数据库连接的情况下也能支持较大的并发操作。
下面我们使用前面的 mdtest 并发压测命令来测试连接数控制的效果。我们通过在 META_URL 中加入 max_open_conns 参数,验证连接数限制的实际效果。

从上图可以看到,随着最大连接数从 5 提升到 20,系统吞吐能力稳步提升,文件创建性能也随之提高,说明合理配置数据库连接数有助于释放后端性能瓶颈,提升整体并发处理能力。
05 缓存处理机制优化:减少元数据查询操作,提升整体性能 (#5540)
JuiceFS 支持客户端元数据缓存,可有效地减少对后端元数据的请求,特别是文件属性相关的缓存,简称 Attr Cache,当文件系统中文件数量非常多时,相关的请求量会激增,若缓存缺失或失效,都会给后端带来瞬间性能冲击。
在 1.3 版本中,我们优化了查找( Lookup)和更新操作(SetAttr)流程,在进行这两项操作时,系统会主动用元数据中的最新版本去更新挂载点本地的 Attr Cache,使得后续 GetAttr 请求可以直接从 Attr Cache 命中,既有利于提升文件访问性能,又可减少数据库的查询请求次数,降低元数据的压力。此优化适用于所有元数据类型,不仅限于 SQL 数据库。
此外,1.3 版本还包含诸如错误重试等其他方面的优化,本文不再逐一展开。欢迎大家在实际场景中尝试使用 SQL 数据库作为 JuiceFS 的元数据引擎,体验这些优化带来的性能提升。
欢迎大家下载试用:https://github.com/juicedata/juicefs/releases/tag/v1.3.0-beta1
如果过程中有任何问题或建议,欢迎随时反馈。我们会持续改进!
JuiceFS v1.3-beta1:全面优化 SQL 数据库支持,十亿级元数据管理新选项的更多相关文章
- 完爆 Best Fit,看阿里如何优化 Sigma 在线调度策略节约亿级成本
摘要:2018 年“双 11”的交易额又达到了一个历史新高度 2135 亿.相比十年前,我们的交易额增长了 360 多倍,而交易峰值增长了 1200 多倍.相对应的,系统数呈现爆发式增长.系统在支撑“ ...
- Windows Azure 微软公有云体验(一) 网站、SQL数据库、虚拟机
Windows Azure 微软公有云已经登陆中国有一段时间了,现在是处于试用阶段,Windows Azure的使用将会给管理信息系统的开发.运行.维护带来什么样的新体验呢? Windows Azur ...
- 杂文笔记《Redis在万亿级日访问量下的中断优化》
杂文笔记<Redis在万亿级日访问量下的中断优化> Redis在万亿级日访问量下的中断优化 https://mp.weixin.qq.com/s?__biz=MjM5ODI5Njc2MA= ...
- JuiceFS V1.0 RC1 发布,大幅优化 dump/load 命令性能, 深度用户不容错过
各位社区的伙伴, JuiceFS v1.0 RC1 今天正式发布了!这个版本中,最值得关注的是对元数据迁移备份工具 dump/load 的优化. 这个优化需求来自于某个社区重度用户,这个用户在将亿级数 ...
- JuiceFS v1.0.0 Beta1 发布,加强数据安全能力
在 JuiceFS 开源一周年之际,我们迎来了首个里程碑版本 JuiceFS v1.0.0 Beta1,并将开源许可从 AGPL v3 修改为 Apache License 2.0. JuiceFS ...
- 基于Qt5.5.0的sql数据库、SDK_tts文本语音朗读的CET四六级单词背诵系统软件的编写V1.0
作者:小波 QQ:463431476 请关注我的博客园:http://www.cnblogs.com/xiaobo-Linux/ 我的第二款软件:CET四六级单词背诵软件.基于QT5.5.0.sql数 ...
- 50种方法优化SQL Server数据库查询
查询速度慢的原因很多,常见如下几种: 1.没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷) 2.I/O吞吐量小,形成了瓶颈效应. 3.没有创建计算列导致查询不优化. 4.内存不足 ...
- 转载 50种方法优化SQL Server数据库查询
原文地址 http://www.cnblogs.com/zhycyq/articles/2636748.html 50种方法优化SQL Server数据库查询 查询速度慢的原因很多,常见如下几种: 1 ...
- 数据库优化 - SQL优化
前面一篇文章从实例的角度进行数据库优化,通过配置一些参数让数据库性能达到最优.但是一些"不好"的SQL也会导致数据库查询变慢,影响业务流程.本文从SQL角度进行数据库优化,提升SQ ...
- 转载 数据库优化 - SQL优化
判断问题SQL判断SQL是否有问题时可以通过两个表象进行判断: 系统级别表象CPU消耗严重IO等待严重页面响应时间过长应用的日志出现超时等错误可以使用sar命令,top命令查看当前系统状态. 也可以通 ...
随机推荐
- react给当前元素添加一个类以及key的作用
给当前元素添加一个类是通过className来处理的: 引入css;直接from XXXX import React, { Component } from "react"; // ...
- [记录点滴] 一个Python中实现flatten的方法
之前如果想使用flatten,一般借助于numpy.ndarray.flatten. 但是 flatten只能适用于numpy对象,即array或者mat,普通的list列表不适用. 最近找到一个轻便 ...
- Integer超过128要用对象比较,否则出问题
一.测试代码 public void testEquals() { int int1 = 12; int int2 = 12; Integer integer1 = new Integer(12); ...
- Luogu P10997 Partition 题解 [ 蓝 ] [ 分割线 dp ]
Partition:一道 dp 神题,用到了以轮廓线的轨迹来做 dp 的技巧,和敲砖块这题的状态设计有点相似. 观察 首先观察样例,发现整张图可以看作是被两条线分隔开的.同时每个颜色的四个方向上又存在 ...
- C# Lambda || Linq 效率问题
255条数据 static void Main() { List<IPEndPoint> list = new List<IPEndPoint>(); for (int i = ...
- 朋友说喊搞个简单的微信对接的封装搞外包,不要那么多的方法拿来就用的的那种,来看看Simple.Wechat吧
不知道大家有没有和我朋友一样,很多时候做外包总免不了去对接微信,最简单的微信用户信息获取.微信支付.微信模板消息发送,要是不熟悉总是要去找这个那个的包,但是人家的包封装的又丰富,又不想去看,本文将给大 ...
- 斐讯N1盒子刷入Armbian并安装Docker拉取网络下行流量教程
一直在跑PCDN,目前主推八米云跟点心云,八米单价比点心更高,业务都一样,直播业务. 两种刷机教程我也发下. 八米云:点此跳转 点心云:点此跳转 最近各运营商对PCDN打击力度加大,需求拉取下行流量的 ...
- 腾讯云锐驰型轻量服务器搭建开源远程桌面软件RustDesk中继服务器小记
RustDesk是一个基于Rust编写的全平台开源远程桌面软件,其最大的特点为开箱即用,且数据完全自主掌控,甚至可以依托此项目定制化开发自己专属的远程桌面软件. 一.前言 由于我个人经常性出差,对远程 ...
- Windows 提权-内核利用_2
本文通过 Google 翻译 Kernel Exploits Part 2 – Windows Privilege Escalation 这篇文章所产生,本人仅是对机器翻译中部分表达别扭的字词进行了校 ...
- [AI/GPT/综述] AI Agent的设计模式综述
序:文由 其一,随着大模型的发展,通用智能不断迭代升级,应用模式也不断创新,从简单的Prompt应用.RAG(搜索增强生成).再到AI Agent(人工智能代理). 其中AI Agent一直是个火热的 ...