Elasticsearch-分片原理1
Elasticsearch版本:6.0
Elasticsearch基于Lucene,采用倒排索引写入磁盘,Lucene引入了按段搜索的概念,来动态更新索引。
一个Lucene索引包含一个提交点和三个短,如图:
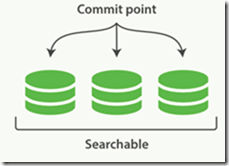
关于索引和分片
一个Lucene索引在Elasticsearch成为分片,一个Elasticsearch索引是分片的集合。
Elasticsearch在索引中搜索时,它发送查询到每一个属于索引的分片,然后合并每个分片的结果到一个全局的结果集。
按段写入磁盘的流程如下:
1、新文档的Lucene索引到达内存缓存
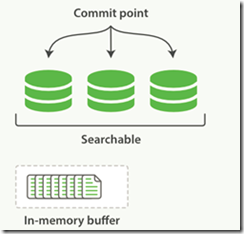
2、提交后新的段添加到提交点,并清空内存缓存
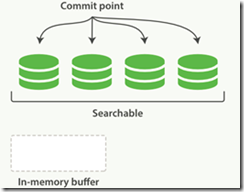
3、在从内存缓存提交到磁盘的过程中,文档会先被写入到文件系统缓存,这一步的代价比刷新到磁盘的代价低,而在文件缓存就可以像其他文件一样被打开读取。而Lucene在此时就可以对这个未完成提交的文档进行搜索。
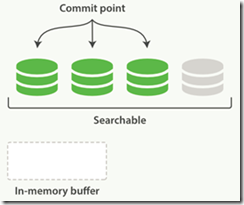
Elasticsearch中,写入和打开一个新段的过程叫refresh,默认情况每个分片每秒自动刷新一次,所以称Elasticsearch是近实时搜索的。文档的变化并不是立即对搜索可见,但会在一秒之内变为可见。
刷新时间可以手动指定
POST /_refresh 刷新(Refresh)所有的索引。
POST /blogs/_refresh 只刷新(Refresh) blogs 索引。
关闭或者设置刷新时间
PUT /my_logs/_settings{ "refresh_interval": -1 }PUT /my_logs/_settings{ "refresh_interval": "1s" }
为了保证Elasticsearch的可靠性,增加了translog事务日志,每次Elasticsearch的操作均进行了日志记录。
1.一个文档被索引之后,就会被添加到内存缓冲区,并且 追加到了 translog
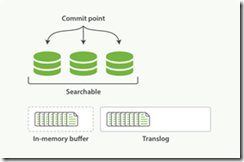
2. 刷新(refresh)完成后, 缓存被清空但是事务日志不会
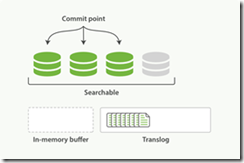
3.这个进程继续工作,更多的文档被添加到内存缓冲区和追加到事务日志
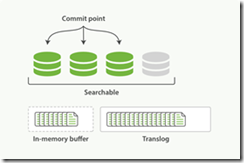
4. 每隔一段时间--例如 translog 变得越来越大--索引被刷新(flush);一个新的 translog 被创建,并且一个全量提交被执行,并且事务日志被清空
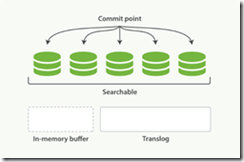
这个执行一个提交并且截断 translog 的行为在 Elasticsearch 被称作一次 flush 。 分片每30分钟被自动刷新(flush),或者在 translog 太大的时候也会刷新。
段合并
Elasticsearch通过后台进行段合并,合并时会将旧的已删除的文档从文件系统清除。
1、两个提交了的段和一个未提交的段正在被合并到一个更大的段
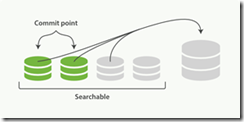
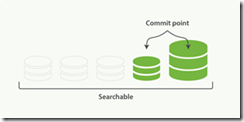
2、一旦合并结束,老的段被删除
Elasticsearch-分片原理1的更多相关文章
- Elasticsearch 分片集群原理、搭建、与SpringBoot整合
单机es可以用,没毛病,但是有一点我们需要去注意,就是高可用是需要关注的,一般我们可以把es搭建成集群,2台以上就能成为es集群了.集群不仅可以实现高可用,也能实现海量数据存储的横向扩展. 新的阅读体 ...
- Elasticsearch工作原理
一.关于搜索引擎 各位知道,搜索程序一般由索引链及搜索组件组成. 索引链功能的实现需要按照几个独立的步骤依次完成:检索原始内容.根据原始内容来创建对应的文档.对创建的文档进行索引. 搜索组件用于接收用 ...
- 进阶的Redis之哈希分片原理与集群实战
前面介绍了<进阶的Redis之数据持久化RDB与AOF>和<进阶的Redis之Sentinel原理及实战>,这次来了解下Redis的集群功能,以及其中哈希分片原理. 集群分片模 ...
- ElasticSearch高可用集群环境搭建和分片原理
1.ES是如何实现分布式高并发全文检索 2.简单介绍ES分片Shards分片技术 3.为什么ES主分片对应的备分片不在同一台节点存放 4.索引的主分片定义好后为什么不能做修改 5.ES如何实现高可用容 ...
- Elasticsearch 分片路由原理指定分片存储查询
Elasticsearch 项目中使用到Es的父子结构.在数据填充之后,查看每个节点的数据分布情况,发现有的节点数据多,有的节点少的情况,在未使用Es父级结构之前,每个节点的数据分布还算平均,如下图: ...
- ElasticSearch(3)-原理
参考文档: http://learnes.net/distributed_crud/bulk_requests.html 一.分布式集群 1.1 空集群 单台机器,其中没有数据,也没有索引. 集群中一 ...
- Elasticsearch架构原理
架构原理 本书作为 Elastic Stack 指南,关注于 Elasticsearch 在日志和数据分析场景的应用,并不打算对底层的 Lucene 原理或者 Java 编程做详细的介绍,但是 Ela ...
- ElasticSearch工作原理与优化
elasticsearch设计的理念就是分布式搜索引擎,底层其实还是基于lucene的,通过倒排索引的方式快速查询.比如一本书的目录是索引,然后快速找到每一章的的文本内容这种叫正向索引:而如果一件衣服 ...
- Elasticsearch分片、副本与路由(shard replica routing)
本文讲述,如何理解Elasticsearch的分片.副本和路由策略. 1.预备知识 1)分片(shard) Elasticsearch集群允许系统存储的数据量超过单机容量,实现这一目标引入分片策略sh ...
- Elasticsearch索引原理
转载 http://blog.csdn.net/endlu/article/details/51720299 最近在参与一个基于Elasticsearch作为底层数据框架提供大数据量(亿级)的实时统计 ...
随机推荐
- openStack cinder 在往虚拟机上挂载云磁盘时总是提示挂在错误 最后找到原因原来是指定挂载云磁盘的虚拟机被锁定
openStack 虚拟机的锁定功能是一个为了保护虚拟机 被误删除的一项创新共! 在VMs锁定状态下,一大部分针对此锁定的虚拟机都是无法执行的!! 需要进行相应的操作前,请注意解锁指定虚拟机,操作完成 ...
- kindeditor Springmvc 整和解决图片上传问题
1. 在编辑页面引入js <script type="text/javascript" charset="utf-8" src="${baseP ...
- netstat -st输出解析(二)
转自:http://perthcharles.github.io/2015/11/10/wiki-netstat-proc/ netstat -st输出的两个重要信息来源分别是/proc/net/sn ...
- excel批量提取网页标题
最近时间比较忙,有时候很多网页需要临时保存,以便空闲的时候查看.单纯的保存网页链接会让人很枯燥,所以需要自动批量提取标题. 为了这个小功能去写个小程序有点不划算,所以就利用excel实现了这个功能. ...
- java中多个线程访问共享数据的方式有哪些
多个线程对共同数据的访问的实现,要根据情况而定 (1)当访问共同的代码的时候:可以使用同一个Runnable对象,这个Runnable对象中有这个共享数据,比如卖票系统就可以这么做.或者这个共享数据封 ...
- Parallel类
Parallel类是对线程很好的一个抽象.该类位于System.Threading.Tasks名称空间中,提供了数据和任务并行性. Parallel类定义了并行的for和foreach的静态方法.Pa ...
- 493. Reverse Pairs(BST, BIT, MergeSort)
Given an array nums, we call (i, j) an important reverse pair if i < j and nums[i] > 2*nums[j] ...
- 深度卷积网络-Inception系列
目录 1. Inception V1 1.1 Inception module 2. Inception V2 3. Inception V3 4. Inception V4, Inception-R ...
- java利用URL发送get和post请求
import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import ...
- [Algorithm]巧用多项式系数与进制的联系
★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★➤微信公众号:山青咏芝(shanqingyongzhi)➤博客园地址:山青咏芝(https://www.cnblogs. ...