storm从入门到放弃(一),storm介绍
背景:目前就职于国内最大的IT咨询公司,恰巧又是毕业季,所在部门招了20多个应届毕业生,本人要跟部门新人进行为期一个月的大数据入职培训,特此将整理的文档分享出来。

Storm是一个开源的分布式实时计算系统,可以简单、可靠的处理大量的数据流。Storm支持水平扩展,具有高容错性,保证每个消息都会得到处理。
Storm核心组件

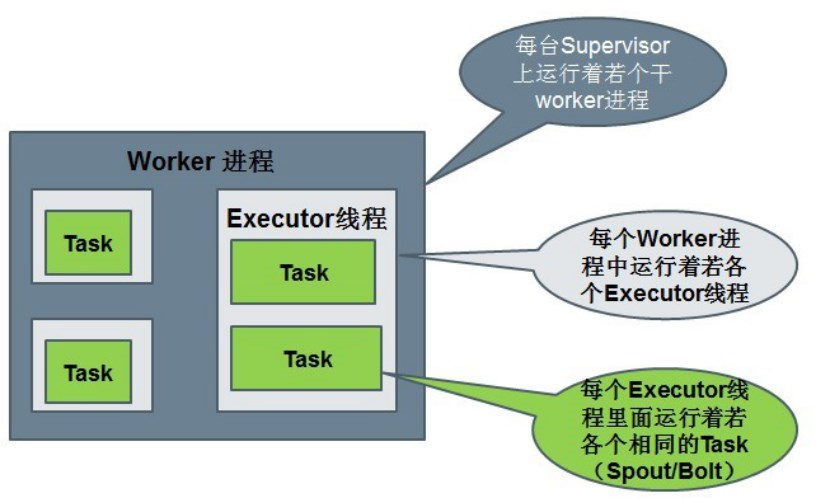
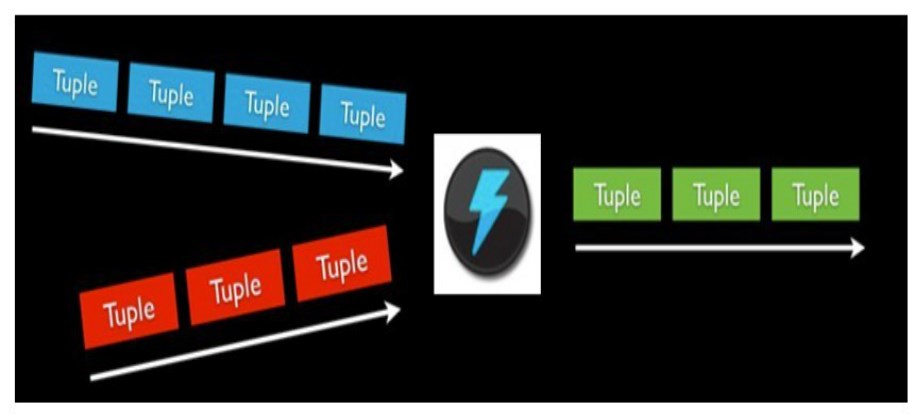
Storm编程模型

public class RandomSentenceSpout extends BaseRichSpout {
public void nextTuple() {
collector.emit(new Values("+ - * % /"));
Utils.sleep(50000);
}
......
}
public class SplitSentenceBolt extends BaseBasicBolt {
public void execute(Tuple input, BasicOutputCollector collector) {
String sentence = (String)input.getValueByField("intsmaze");
System.out.println(Thread.currentThread().getId()+" "+sentence);
}
......
}
public class TwoBolt extends BaseBasicBolt {
public void execute(Tuple input, BasicOutputCollector collector) {
String sentence = (String)input.getValueByField("intsmaze");
System.out.println(Thread.currentThread().getId()+" "+sentence);
}
......
}
public class WordCountTopologyMain {
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout1", new RandomSentenceSpout(),1);
builder.setBolt("two", new TwoBolt(),1).shuffleGrouping("spout1");
builder.setBolt("split1", new SplitSentenceBolt(),2).shuffleGrouping("spout1");
Config conf = new Config();
conf.setDebug(false);
conf.setMaxTaskParallelism(3);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("word-count", conf, builder.createTopology());
}
}
}
可以发现spout每隔一段时间间隔发一份数据,这份数据会被两个bolt同时接收,而不是说这次A bolt接收下次B bolt接收。 同一个bolt业务逻辑如果设置了并行度,他们才会根据分组策略依次接收上游发来的消息。
----------------84 + - * % / 这个是tow bolt接收
----------------78 + - * % / 这个是split1 bolt 中78线程接收的
----------------80 + - * % / 这个是split1 bolt中线程80接收的。
----------------84 + - * % /
----------------78 + - * % /
----------------84 + - * % /
Fields Grouping:按字段分组,比如按userid来分组,具有同样userid的tuple会被分到相同的Bolts里的一个task,而不同的userid则会被分配到不同的bolts里的task。
All Grouping:广播发送,对于每一个tuple,所有的bolts都会收到。
Global Grouping:全局分组, 这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
Non Grouping:不分组,这stream grouping个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果, 有一点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程里面去执行。
Direct Grouping: 直接分组, 这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)。
Local or shuffle grouping:如果目标bolt有一个或者多个task在同一个工作进程中,tuple将会被随机发生给这些tasks。否则,和普通的Shuffle Grouping行为一致。
conf.setNumWorkers(4) 表示设置了4个worker来执行整个topology的所有组件
builder.setBolt("boltA-intsmaze",new BoltA(), 4) ---->指明 boltA组件的线程数excutors总共有4个
builder.setBolt("boltB-intsmaze",new BoltB(), 4) ---->指明 boltB组件的线程数excutors总共有4个
builder.setSpout("randomSpout-intsmaze",new RandomSpout(), 2) ---->指明randomSpout组件的线程数excutors总共有2个
-----意味着整个topology中执行所有组件的总线程数为4+4+2=10个
----worker数量是4个,有可能会出现这样的负载情况,worker-1有2个线程,worker-2有2个线程,worker-3有3个线程,worker-4有3个线程
如果指定某个组件的具体task并发实例数
builder.setSpout("randomspout-intsmaze", new RandomWordSpout(), 4).setNumTasks(8);
----意味着对于这个组件的执行线程excutor来说,一个excutor将执行8/4=2个task,默认情况一个线程执行一个task.
storm从入门到放弃(一),storm介绍的更多相关文章
- Storm编程入门API系列之Storm的Topology多个Workers数目控制实现
前期博客 Storm编程入门API系列之Storm的Topology默认Workers.默认executors和默认tasks数目 继续编写 StormTopologyMoreWorker.java ...
- Storm编程入门API系列之Storm的Topology多个Executors数目控制实现
前期博客 Storm编程入门API系列之Storm的Topology默认Workers.默认executors和默认tasks数目 Storm编程入门API系列之Storm的Topology多个Wor ...
- Storm编程入门API系列之Storm的Topology多个tasks数目控制实现
前期博客 Storm编程入门API系列之Storm的Topology默认Workers.默认executors和默认tasks数目 Storm编程入门API系列之Storm的Topology多个Wor ...
- Storm编程入门API系列之Storm的定时任务实现
概念,见博客 Storm概念学习系列之storm的定时任务 Storm的定时任务,分为两种实现方式,都是可以达到目的的. 我这里,分为StormTopologyTimer1.java 和 Sto ...
- Storm编程入门API系列之Storm的Topology的stream grouping
概念,见博客 Storm概念学习系列之stream grouping(流分组) Storm的stream grouping的Shuffle Grouping 它是随机分组,随机派发stream里面的t ...
- Storm编程入门API系列之Storm的Topology默认Workers、默认executors和默认tasks数目
关于,storm的启动我这里不多说了. 见博客 storm的3节点集群详细启动步骤(非HA和HA)(图文详解) 建立stormDemo项目 Group Id : zhouls.bigdata Art ...
- Storm编程入门API系列之Storm的可靠性的ACK消息确认机制
概念,见博客 Storm概念学习系列之storm的可靠性 什么业务场景需要storm可靠性的ACK确认机制? 答:想要保住数据不丢,或者保住数据总是被处理.即若没被处理的,得让我们知道. publi ...
- storm从入门到放弃(二),任务分配过程-核心机密
背景:目前就职于国内最大的IT咨询公司,恰巧又是毕业季,所在部门招了100多个应届毕业生,本人要跟部门新人进行为期一个月的大数据入职培训,特此将整理的文档分享出来. 原文和作者一起讨论:http:// ...
- storm从入门到放弃(三),放弃使用《StreamId》特性。
序:StreamId是storm中实现DAG有向无环图的重要一个特性,但是从实际生产环境来看,这个功能其实蛮影响生产环境的稳定性的,我们系统在迭代时会带来整体服务的不可用. StreamId是stor ...
随机推荐
- ubuntu 系统 更改屏幕亮度为最大(15级亮度)
历经千辛万苦终于搞定屏幕亮度,现将成果分享如下. 硬件:联想K29 系统:UBUNTU 14.04 一.执行命令 sudo gedit /etc/default/grub 二.更改文本 然后找到 GR ...
- Vue2 全家桶仿 微信App 项目,支持多人在线聊天和机器人聊天
前言 这个项目是利用工作之余写的一个模仿微信app的单页面应用,整个项目包含27个页面,涉及实时群聊,机器人聊天,同学录,朋友圈等等,后续页面还是开发中.写这个项目主要目的是练习和熟悉vue和vuex ...
- flask 扩展之 -- flask-moment
一. 安装 $ pip install flask-moment 二. 初始化 from flask_moment import Moment moment = Moment(app) 三. 解决依赖 ...
- 选课 树形DP+多叉树转二叉树+dfs求解答案
问题 A: 选课 时间限制: 1 Sec 内存限制: 128 MB 题目描述 大 学里实行学分.每门课程都有一定的学分,学生只要选修了这门课并考核通过就能获得相应的学分.学生最后的学分是他选修的各门 ...
- IDEA报错处理:Application Server was not connected before run configuration stop, reason: Unable to ping server at localhost:8080
把wildfly的整个软件包更换成新的,配置文件重新配置,JBOSS_HOME环境变量修改成新的,在wildfly-10.1.0.FinalForTest\modules\system\layers\ ...
- PHP+MySql实现后台数据的读取
我们使用的是PHP 的php_mysqli扩展 首先了解一些基础的用法 1.连接数据库使用 mysqli_connect() 参数:①主机地址 ②MYSQL用户名 ③MYSQL密码 ④选择 ...
- docker私有库搭建过程(Registry)
实验环境: CentOS7 1611 Docker 1.12.6 registry 2.0 1.安装并运行registry 安装: [root@docker01 ~]# docker pull r ...
- DDD领域驱动之干活(四)补充篇!
距离上一篇DDD系列完结已经过了很长一段时间,项目也搁置了一段时间,想想还是继续完善下去. DDD领域驱动之干货(三)完结篇! 上一篇说到了如何实现uow配合Repository在autofac和au ...
- iis部署wcf服务过程
一.在iis网站中添加wcf服务,一直添加到web.config目录即可 二.点击基本设置-->连接为-->特定用户.填写登入电脑的用户名和密码. 三.点击身份验证 四.控制面板,设置防火 ...
- angular 4使用jquery 第三方插件库
用jBox插件为例子 1,npm install jBox --save 2,找到.angular-cli.json 增加 "../node_modules/jbox/Source/jBo ...