Spark2.1.0分布式集群安装
一、依赖文件安装
1.1 JDK
参见博文:http://www.cnblogs.com/liugh/p/6623530.html
1.2 Hadoop
参见博文:http://www.cnblogs.com/liugh/p/6624872.html
1.3 Scala
参见博文:http://www.cnblogs.com/liugh/p/6624491.html
二、文件准备
2.1 文件名称
spark-2.1.0-bin-hadoop2.7.tgz
2.2 下载地址
http://spark.apache.org/downloads.html

三、工具准备
3.1 Xshell
一个强大的安全终端模拟软件,它支持SSH1, SSH2, 以及Microsoft Windows 平台的TELNET 协议。
Xshell 通过互联网到远程主机的安全连接以及它创新性的设计和特色帮助用户在复杂的网络环境中享受他们的工作。
3.2 Xftp
一个基于 MS windows 平台的功能强大的SFTP、FTP 文件传输软件。
使用了 Xftp 以后,MS windows 用户能安全地在UNIX/Linux 和 Windows PC 之间传输文件。
四、部署图

五、Spark安装
以下操作,均使用root用户
5.1 通过Xftp将下载下来的Spark安装文件上传到Master及两个Slave的/usr目录下
5.2 通过Xshell连接到虚拟机,在Master及两个Slave上,执行如下命令,解压文件:
# tar zxvf spark-2.1.0-bin-hadoop2.7.tgz
5.3 在Master上,使用Vi编辑器,设置环境变量
# vi /etc/profile
在文件最后,添加如下内容:
#Spark Env
export SPARK_HOME=/usr/spark-2.1.0
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
5.4 退出vi编辑器,使环境变量设置立即生效
# source /etc/profile
通过scp命令,将/etc/profile拷贝到两个Slave节点:
#scp /etc/profile root@DEV-SH-MAP-02:/etc
#scp /etc/profile root@DEV-SH-MAP-03:/etc
分别在两个Salve节点上执行# source /etc/profile使其立即生效
六、Spark配置
以下操作均在Master节点,配置完后,使用scp命令,将配置文件拷贝到两个Worker节点即可。
切换到/usr/spark-2.1.0/conf/目录下,修改如下文件:
6.1 spark-env.sh
将spark-env.sh.template重命名为spark-env.sh
#mv spark-env.sh.template spark-env.sh
使用vi编辑器,打开spark-env.sh,在文件最后,添加如下内容:
export JAVA_HOME=/usr/jdk1..0_121
export SCALA_HOME=/usr/scala-2.12.
export SPARK_MASTER_IP=10.10.0.1
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/usr/hadoop-2.7./etc/hadoop
6.2 slaves
将slaves.template重命名为slaves
#mv slaves.template slaves
使用vi编辑器,打开slaves,在文件最后,添加如下内容:
DEV-SH-MAP-
DEV-SH-MAP-
DEV-SH-MAP-
6.3 拷贝配置文件到两个Worker节点
在Master节点,执行如下命令:
# scp -r /usr/spark-2.1.0/conf/ root@DEV-SH-MAP-02:/usr/spark-2.1.0/
# scp -r /usr/spark-2.1.0/conf/ root@DEV-SH-MAP-03:/usr/spark-2.1.0/
七、Spark使用
7.1 启动Hadoop集群
参见博文:http://www.cnblogs.com/liugh/p/6624872.html
7.2 启动Master节点
Master节点上,执行如下命令:
#start-master.sh
使用jps命令,查看Java进程:
SecondaryNameNode
NameNode Jps
NodeManager
ResourceManager
DataNode
Master
7.3 启动Worker节点
Master节点上,执行如下命令:
#start-slaves.sh
使用jps命令,查看Java进程:
SecondaryNameNode
NameNode
Worker
Jps
NodeManager
ResourceManager
DataNode
Master
7.4 通过浏览器查看Spark信息
浏览器中,输入http://10.10.0.1:8080
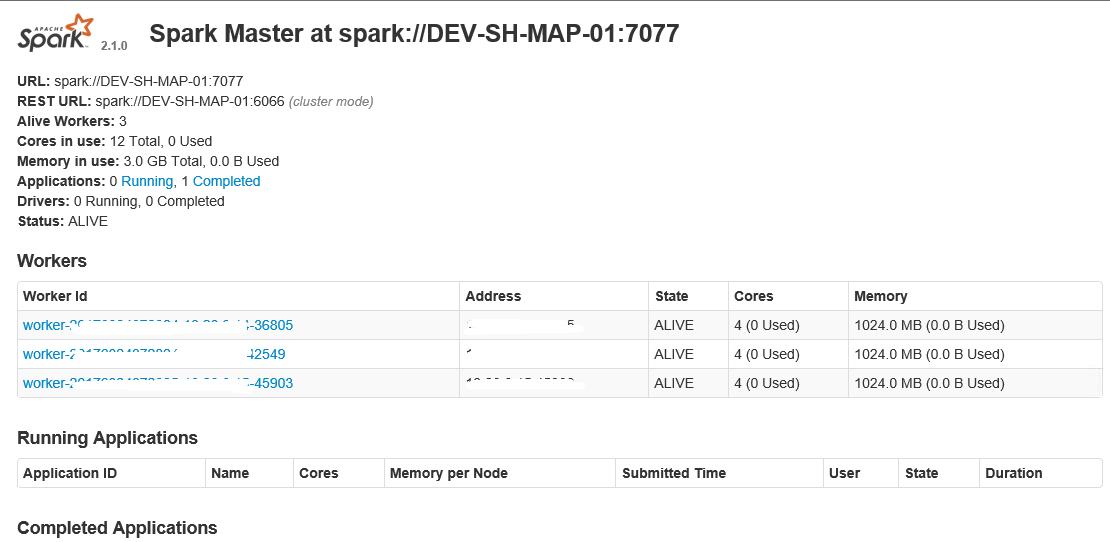
7.5 停止Master及Workder节点
#stop-master.sh
#stop-slaves.sh
Spark2.1.0分布式集群安装的更多相关文章
- Spark2.2.0分布式集群安装(StandAlone模式)
一.依赖文件安装 1.1 JDK 参见博文:http://www.cnblogs.com/liugh/p/6623530.html 1.2 Scala 参见博文:http://www.cnblogs. ...
- Kafka0.10.2.0分布式集群安装
一.依赖文件安装 1.1 JDK 参见博文:http://www.cnblogs.com/liugh/p/6623530.html 1.2 Scala 参见博文:http://www.cnblogs. ...
- CentOS 6+Hadoop 2.6.0分布式集群安装
1.角色分配 IP Role Hostname 192.168.18.37 Master/NameNode/JobTracker HDP1 192.168.18.35 Slave/DataNode/T ...
- (转)ZooKeeper伪分布式集群安装及使用
转自:http://blog.fens.me/hadoop-zookeeper-intro/ 前言 ZooKeeper是Hadoop家族的一款高性能的分布式协作的产品.在单机中,系统协作大都是进程级的 ...
- 菜鸟玩云计算之十八:Hadoop 2.5.0 HA 集群安装第1章
菜鸟玩云计算之十八:Hadoop 2.5.0 HA 集群安装第1章 cheungmine, 2014-10-25 0 引言 在生产环境上安装Hadoop高可用集群一直是一个需要极度耐心和体力的细致工作 ...
- HBase 1.2.6 完全分布式集群安装部署详细过程
Apache HBase 是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,是NoSQL数据库,基于Google Bigtable思想的开源实现,可在廉价的PC Server上搭建大规模结构化存 ...
- 一张图讲解最少机器搭建FastDFS高可用分布式集群安装说明
很幸运参与零售云快消平台的公有云搭建及孵化项目.零售云快消平台源于零售云家电3C平台私有项目,是与公司业务强耦合的.为了适用于全场景全品类平台,集团要求项目平台化,我们抢先并承担了此任务.并由我来主 ...
- ZooKeeper伪分布式集群安装及使用
ZooKeeper伪分布式集群安装及使用 让Hadoop跑在云端系列文章,介绍了如何整合虚拟化和Hadoop,让Hadoop集群跑在VPS虚拟主机上,通过云向用户提供存储和计算的服务. 现在硬件越来越 ...
- hadoop学习之hadoop完全分布式集群安装
注:本文的主要目的是为了记录自己的学习过程,也方便与大家做交流.转载请注明来自: http://blog.csdn.net/ab198604/article/details/8250461 要想深入的 ...
随机推荐
- 笔记之《用python写网络爬虫》
1 .3 背景调研 robots. txt Robots协议(也称为爬虫协议.机器人协议等)的全称是"网络爬虫排除标准"(Robots Exclusion Protocol),网站 ...
- Cassandra 学习笔记 - 1 - 关于Cassandra
摘要 - Cassandra 的历史 Cassandra能做什么 Apache Cassandra最早是Facebook为了改进他们的Inbox搜索功能,由Avanash Lakshman和Prash ...
- iOS异步处理
有过编程经验的人,基本都会接触到多线程这块. 在java中以及Android开发中,大量的后台运行,异步消息队列,基本都是运用了多线程来实现. 同样在,在ios移动开发和Android基本是很类似的一 ...
- Ubuntu Hash Sum mismatch 解决方法
有时候通过校园网对Ubuntu14.04进行更新时,会出现以下问题: W: Failed to fetch http://xxxxxxx Hash Sum mismatch 解决方法:打开搜索 → ...
- Entity Framework+SQLite+DataBaseFirst
Entity Framework+Sqlite+DataBaseFirst 本篇主要是说明在vs中配置Sqlite,及使用Entity Framework DataBaseFirst模式. 如果没有下 ...
- ftp服务搭建
文件传输服务 主配置文件目录/etc/vsftpd/vsftpd.conf 首先安装ftp服务器 yum install vsftpd 默认存放文件的目录 /var/ftp/pub 匿名登陆 创建一 ...
- tcp粘包和拆包的处理方案
随着智能硬件越来越流行,很多后端开发人员都有可能接触到socket编程.而很多情况下,服务器与端上需要保证数据的有序,稳定到达,自然而然就会选择基于tcp/ip协议的socekt开发.开发过程中,经常 ...
- MySQL学习分享--数值类型
数值类型 MySQL的数值类型包括整数类型.浮点数类型.定点数类型.位类型. 整数类型 MySQL支持的整数类型有tinyint.smallint.mediumint.int.bigint(范围从小到 ...
- CSS中@import与link的具体区别
我们知道在网页中引用外部CSS有两种方式:@import和link 我们也经常听到有人说要使用link来引入CSS更好,但是你知道为什么吗? 继续往下看 link:link就是把外部CSS与网页连接起 ...
- Java并发之任务的描述和执行
简单概念 <Java编程思想>对并发概念的重要性阐述: Java是一种多线程语言,并且提出了并发问题,不管你是否意识到了.因此,有很多使用中的Java程序,要么只是偶尔工作,要么是在大多数 ...