MLlib--PIC算法
转载请标明出处http://www.cnblogs.com/haozhengfei/p/82c3ef86303321055eb10f7e100eb84b.html
PIC算法 幂迭代聚类
1.谱聚类
2.谱聚类分割方法


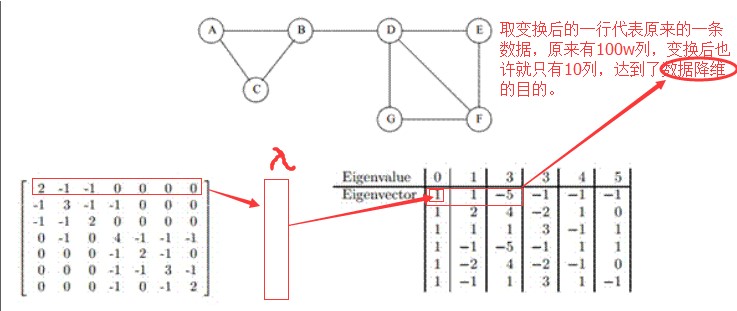
3.PIC算法VS谱聚类
4谱聚类code
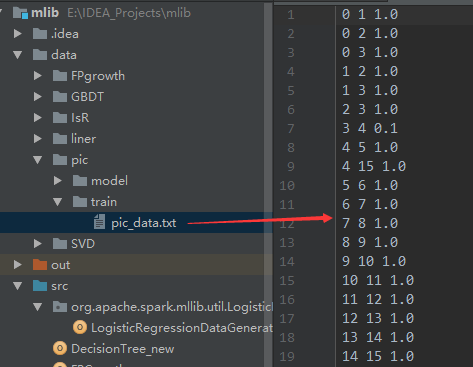
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.mllib.clustering.PowerIterationClustering
/**
* Created by hzf
*/
object PowerIterationClustering_new {
// E:\IDEA_Projects\mlib\data\pic\train\pic_data.txt E:\IDEA_Projects\mlib\data\pic\model 3 20 local
def main(args: Array[String]) {
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
if (args.length < 5) {
System.err.println("Usage: PIC <inputPath> <modelPath> <K> <iterations> <master> [<AppName>]")
System.exit(1)
}
val appName = if (args.length > 5) args(5) else "PIC"
val conf = new SparkConf().setAppName(appName).setMaster(args(4))
val sc = new SparkContext(conf)
val data: RDD[(Long, Long, Double)] = sc.textFile(args(0)).map(line => {
val parts = line.split(" ").map(_.toDouble)
(parts(0).toLong, parts(1).toLong, parts(2))
})
val pic = new PowerIterationClustering()
.setK(args(2).toInt)
.setMaxIterations(args(3).toInt)
val model = pic.run(data)
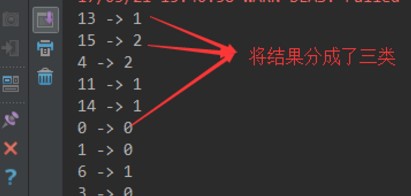
model.assignments.foreach { a =>
println(s"${a.id} -> ${a.cluster}")
}
model.save(sc, args(1))
}
}
E:\IDEA_Projects\mlib\data\pic\train\pic_data.txt E:\IDEA_Projects\mlib\data\pic\model 320 local
MLlib--PIC算法的更多相关文章
- Spark MLlib回归算法------线性回归、逻辑回归、SVM和ALS
Spark MLlib回归算法------线性回归.逻辑回归.SVM和ALS 1.线性回归: (1)模型的建立: 回归正则化方法(Lasso,Ridge和ElasticNet)在高维和数据集变量之间多 ...
- spark mllib k-means算法实现
package iie.udps.example.spark.mllib; import java.util.regex.Pattern; import org.apache.spark.SparkC ...
- Spark MLlib回归算法LinearRegression
算法说明 线性回归是利用称为线性回归方程的函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析方法,只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归,在实际情况中大多数都是多 ...
- Spark MLlib基本算法【相关性分析、卡方检验、总结器】
一.相关性分析 1.简介 计算两个系列数据之间的相关性是统计中的常见操作.在spark.ml中提供了很多算法用来计算两两的相关性.目前支持的相关性算法是Pearson和Spearman.Correla ...
- Spark MLlib架构解析(含分类算法、回归算法、聚类算法和协同过滤)
Spark MLlib架构解析 MLlib的底层基础解析 MLlib的算法库分析 分类算法 回归算法 聚类算法 协同过滤 MLlib的实用程序分析 从架构图可以看出MLlib主要包含三个部分: 底层基 ...
- Spark2.0机器学习系列之11: 聚类(幂迭代聚类, power iteration clustering, PIC)
在Spark2.0版本中(不是基于RDD API的MLlib),共有四种聚类方法: (1)K-means (2)Latent Dirichlet all ...
- 转载:Databricks孟祥瑞:ALS 在 Spark MLlib 中的实现
Databricks孟祥瑞:ALS 在 Spark MLlib 中的实现 发表于2015-05-07 21:58| 10255次阅读| 来源<程序员>电子刊| 9 条评论| 作者孟祥瑞 大 ...
- Spark入门实战系列--8.Spark MLlib(上)--机器学习及SparkMLlib简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .机器学习概念 1.1 机器学习的定义 在维基百科上对机器学习提出以下几种定义: l“机器学 ...
- 使用 Spark MLlib 做 K-means 聚类分析[转]
原文地址:https://www.ibm.com/developerworks/cn/opensource/os-cn-spark-practice4/ 引言 提起机器学习 (Machine Lear ...
随机推荐
- 自动化测试辅助工具(Selenium IDE等)
本随表目录 Selenium IDE安装和使用 FireBug安装和使用 FirePath安装和使用 Selenium IDE安装 方式一:打开Firefox-->添加组件-->搜索出 ...
- Javascript高级程序设计笔记 <第五章> 引用类型
一.object类型 创建object实例的方式有两种: //第一种使用new操作符跟构造函数 var person= new Object(); person.name="小王" ...
- 一起学Linux04之Linux文件基本属性
Linux系统是一种典型的多用户系统,不同的用户处于不同的地位,拥有不同的权限.为了保护系统的安全性,Linux系统对不同的用户访问同一文件(包括目录文件)的权限做了不同的规定. 为了介绍文件属性,首 ...
- PHP重要知识点
1 获取文件名或目录路径 getcwd() :显示是 在哪个文件里调用此文件 的目录 __DIR__ :当前内容写在哪个文件就显示这个文件目录 __FILE__ : 当前内容写在哪个文件就显示这个文件 ...
- 正则表达过滤表单隐藏元素,组装post数据
<form name="form1" action="'.$serverUrl.'" method="post" > <i ...
- S2 深入.NET和C#编程 三:使用集合组织相关数据
三:使用集合组织相关数据 集合概念: ArrayList:非常类似于数组,也有人称他为数组的列表.ArrayList可以动态维护,数组的容量是固定的 和数组类似,ArrayList中存储的是数据成为元 ...
- Java笔记:开发环境
Java开发环境 Java是由Sun Microsystems公司于1995年5月推出的Java面向对象程序设计语言和Java平台的总称.由James Gosling和同事们共同研发,并在1995年正 ...
- Linux下查找文件的方法
在Linux环境下查找一个文件的方法:find 路径 -name 'filename',filename不清楚全名的话可以用*号进行匹配,如“tomcat.*”.如果不清楚路径的话可以用"/ ...
- 安卓电量优化之AlarmManager使用全部解析
版权声明:本文出自汪磊的博客,转载请务必注明出处. 一.AlarmManager概述 AlarmManager是安卓系统中一种系统级别的提示服务,可以在我们设定时间或者周期性的执行一个intent,这 ...
- File System 之本地文件系统
上一篇文章提到了,最近做一个基于 File System/IndexedDB的应用,上一篇是定额和使用的查询. 因为LocalFileSystem只有chrome支持,有点尴尬,如果按需加载又何来尴尬 ...