K:图相关的最小生成树(MST)
相关介绍:
根据树的特性可知,连通图的生成树是图的极小连通子图,它包含图中的全部顶点,但只有构成一棵树的边;生成树又是图的极大无回路子图,它的边集是关联图中的所有顶点而又没有形成回路的边。
一个有n个顶点的连通图的生成树只有n-1条边。若有n个顶点而少于n-1条边,则是非连通图(将其想成有n个顶点的一条链,则其为连通图的条件是至少有n-1条边);若多于n-1条边,则一定形成回路。值得注意的是,有n-1条边的生成子图,并不一定是生成树。此处,介绍一个概念。网:指的是边带有权值的图。
在一个网的所有生成树中,权值总和最小的生成树,称之为最小代价生成树,也称为最小生成树。
最小生成树:
根据生成树的定义,具有n个顶点的连通图的生成树,有n个顶点和n-1条边。因此,构造最小生成树的准则有以下3条:
- 只能使用图中的边构造最小生成树
- 当且仅当使用n-1条边来连接图中的n个顶点
- 不能使用产生回路的边
需要注意的一点是,尽管最小生成树一定存在,但其并不一定是唯一的。以下介绍求图的最小生成树的两个典型的算法,分别为克鲁斯卡尔算法(kruskal)和普里姆算法(prim)
克鲁斯卡尔(Kruskal)算法:
克鲁斯卡尔算法是根据边的权值递增的方式,依次找出权值最小的边建立的最小生成树,并且规定每次新增的边,不能造成生成树有回路,直到找到n-1条边为止。
基本思想:设图G=(V,E)是一个具有n个顶点的连通无向网,T=(V,TE)是图的最小生成树,其中V是T的顶点集,TE是T的边集,则构造最小生成树的具体步骤如下:
T的初始状态为T=(V,空集),即开始时,最小生成树T是图G的生成零图
将图G中的边按照权值从小到大的顺序依次选取,若选取的边未使生成树T形成回路,则加入TE中,否则舍弃,直至TE中包含了n-1条边为止
下图演示克鲁斯卡尔算法的构造最小生成树的过程:
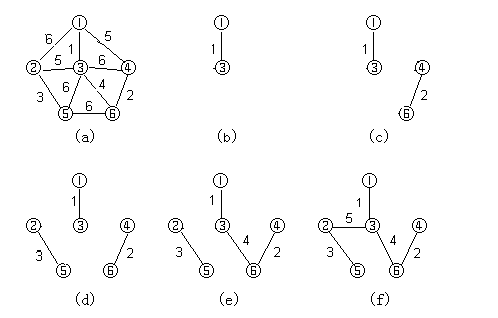
其示意代码如下:
相关代码:
package all_in_tree;
import java.util.Comparator;
import java.util.PriorityQueue;
import java.util.Queue;
import algorithm.PathCompressWeightQuick_Union;
import algorithm.UF;
/**
* 该类用于演示克鲁斯卡尔算法的过程
* @author 学徒
*
*由于每次添加一条边时,需要判断所添加的边是否会产生回路,而回路的产生,当且仅当边上的两个节点处在同一个连通
*分支上,为此,可以使用Union-Find算法来判断边上的两个点是否处在同一个连通分支上
*
*/
public class Kruskal
{
//用于记录节点的数目
private int nodeCount;
//用于判断是否会形成回路
private UF unionFind;
//用优先级队列,每次最先出队的是其权值最小的边
private Queue<Edge> q;
//用于存储图的生成树
private Edge[] tree;
/**
* 初始化一个图的最小生成树所需的数据结构
* @param n 图的节点的数目
*/
public Kruskal(int n)
{
this.nodeCount=n;
tree=new Edge[n-1];
unionFind=new PathCompressWeightQuick_Union(n);
Comparator<Edge> cmp=new Comparator<Edge>()
{
@Override
public int compare(Edge obj1,Edge obj2)
{
int obj1W=obj1.weight;
int obj2W=obj2.weight;
if(obj1W<obj2W)
return -1;
else if(obj1W>obj2W)
return 1;
else
return 0;
}
};
q=new PriorityQueue<Edge>(11,cmp);
}
/**
* 用于添加一条边
* @param edge 所要进行添加的边
*/
public void addEdge(Edge edge)
{
q.add(edge);
}
/**
* 用于生成最小生成树
* @return 最小生成树的边集合
*/
public Edge[] getTree()
{
//用于记录加入图的最小生成树的边的数目
int edgeCount=0;
//用于得到最小生成树
while(!q.isEmpty()&&edgeCount<this.nodeCount-1)
{
//每次取出权值最小的一条边
Edge e=q.poll();
//判断是否产生回路,当其不产生回路时,将其加入到最小生成树中
int index1=unionFind.find(e.node1);
int index2=unionFind.find(e.node2);
if(index1!=index2)
{
tree[edgeCount++]=e;
unionFind.union(e.node1, e.node2);
}
}
return tree;
}
}
/**
* 测试用例所使用的类,该类的测试用例即为上图中中所示的Kruskal算法最小生成树的构造
* 过程的示例图,且其节点编号从0开始,而不从1开始
* @author 学徒
*
*/
class Test
{
public static void main(String[] args)
{
Kruskal k=new Kruskal(6);
k.addEdge(new Edge(0,3,5));
k.addEdge(new Edge(0,1,6));
k.addEdge(new Edge(1,4,3));
k.addEdge(new Edge(4,5,6));
k.addEdge(new Edge(3,5,2));
k.addEdge(new Edge(0,2,1));
k.addEdge(new Edge(1,2,5));
k.addEdge(new Edge(2,4,6));
k.addEdge(new Edge(2,5,4));
k.addEdge(new Edge(2,3,6));
Edge[] tree=k.getTree();
for(Edge e:tree)
{
System.out.println(e.node1+" --> "+e.node2+" : "+e.weight);
}
}
}
/**
* 图的边的数据结构
* @author 学徒
*
*/
class Edge
{
//节点的编号
int node1;
int node2;
//边上的权值
int weight;
public Edge()
{
}
public Edge(int node1,int node2,int weight)
{
this.node1=node1;
this.node2=node2;
this.weight=weight;
}
}
运行结果:
0 --> 2 : 1
3 --> 5 : 2
1 --> 4 : 3
2 --> 5 : 4
1 --> 2 : 5
ps:上述代码中所用到的Union-Find算法的相关代码及解析,请点击 K:Union-Find(并查集)算法 进行查看
分析 :该算法的时间复杂度为O(elge),即克鲁斯卡尔算法的执行时间主要取决于图的边数e,为此,该算法适用于针对稀疏图的操作
普里姆算法(Prim):
为描述的方便,在介绍普里姆算法前,给出如下有关距离的定义:
两个顶点之间的距离:是指将顶点u邻接到v的关联边的权值,即为|u,v|。若两个顶点之间无边相连,则这两个顶点之间的距离为无穷大
顶点到顶点集合之间的距离:顶点u到顶点集合V之间的距离是指顶点u到顶点集合V中所有顶点之间的距离中的最小值,即为|u,V|=\(min|u,v| , v\in V\)
两个顶点集合之间的距离:顶点集合U到顶点集合V的距离是指顶点集合U到顶点集合V中所有顶点之间的距离中的最小值,记为|U,V|=\(min|u,V| , u\in U\)
基本思想:假设G=(V,E)是一个具有n个顶点的连通网,T=(V,TE)是网G的最小生成树。其中,V是R的顶点集,TE是T的边集,则最小生成树的构造过程如下:从U={u0},TE=\(\varnothing\)开始,必存在一条边(u,v),u\(\in U\),v\(\in V-U\),使得|u,v|=|U,V-U|,将(u,v)加入集合TE中,同时将顶点v*加入顶点集U中,直到U=V为止,此时,TE中必有n-1条边(最小生成树存在的情况),最小生成树T构造完毕。下图演示了使用Prim算法构造最小生成树的过程
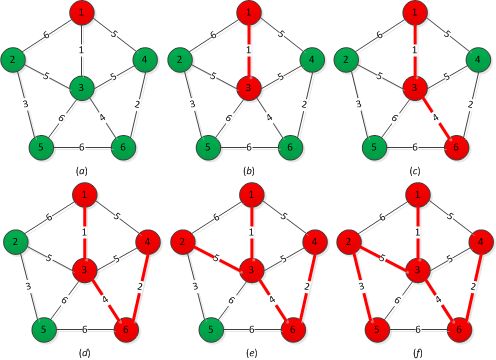
其示意代码如下:
相关代码:
package all_in_tree;
/**
* 该类用于演示Prim算法构造最小生成树的过程
* @author 学徒
*
*/
public class Prim
{
//用于记录图中节点的数目
private int nodeCount;
//用于记录图的领接矩阵,其存储对应边之间的权值
private int[][] graph;
//用于记录其对应节点是否已加入集合U中,若加入了集合U中,则其值为true
private boolean[] inU;
//用于记录其生成的最小生成树的边的情况
private Edge[] tree;
//用于记录其下标所对的节点的编号相对于集合U的最小权值边的权值的情况
private int[] min;
//用于记录其下标所对的节点的最小权值边所对应的集合U中的节点的情况
private int[] close;
/**
* 用于初始化
* @param n 节点的数目
*/
public Prim(int n)
{
this.nodeCount=n;
this.graph=new int[n][n];
//初始化的时候,将各点的权值初始化为最大值
for(int i=0;i<n;i++)
{
for(int j=0;j<n;j++)
{
graph[i][j]=Integer.MAX_VALUE;
}
}
this.inU=new boolean[n];
this.tree=new Edge[n-1];
this.min=new int[n];
this.close=new int[n];
}
/**
*用于为图添加一条边
* @param edge 边的封装类
*/
public void addEdge(Edge edge)
{
int node1=edge.node1;
int node2=edge.node2;
int weight=edge.weight;
graph[node1][node2]=weight;
graph[node2][node1]=weight;
}
/**
* 用于获取其图对应的最小生成树的结果
* @return 由最小生成树组成的边的集合
*/
public Edge[] getTree()
{
//用于将第一个节点加入到集合U中
for(int i=1;i<nodeCount;i++)
{
min[i]=graph[0][i];
close[i]=0;
}
inU[0]=true;
//用于循环n-1次,每次循环添加一条边进最小生成树中
for(int i=0;i<nodeCount-1;i++)
{
//用于记录找到的相对于集合U中的节点的最小权值的节点编号
int node=0;
//用于记录其相对于集合U的节点的最小的权值
int mins=Integer.MAX_VALUE;
//用于寻找其相对于集合U中最小权值的边
for(int j=1;j<nodeCount;j++)
{
if(min[j]<mins&&!inU[j])
{
mins=min[j];
node=j;
}
}
//用于记录其边的情况
tree[i]=new Edge(node,close[node],mins);
//修改相关的状态
inU[node]=true;
//修改其相对于集合U的情况
for(int j=1;j<nodeCount;j++)
{
if(!inU[j]&&graph[node][j]<min[j])
{
min[j]=graph[node][j];
close[j]=node;
}
}
}
return tree;
}
}
class Edge
{
//节点的编号
int node1;
int node2;
//边上的权值
int weight;
public Edge()
{
}
public Edge(int node1,int node2,int weight)
{
this.node1=node1;
this.node2=node2;
this.weight=weight;
}
}
/**
* 测试用例所使用的类,该类的测试用例即为上图中中所示的Prim算法最小生成树的构造
* 过程的示例图,且其节点编号从0开始,而不从1开始
* @author 学徒
*
*/
class Test
{
public static void main(String[] args)
{
Prim k=new Prim(6);
k.addEdge(new Edge(0,3,5));
k.addEdge(new Edge(0,1,6));
k.addEdge(new Edge(1,4,3));
k.addEdge(new Edge(4,5,6));
k.addEdge(new Edge(3,5,2));
k.addEdge(new Edge(0,2,1));
k.addEdge(new Edge(1,2,5));
k.addEdge(new Edge(2,4,6));
k.addEdge(new Edge(2,5,4));
k.addEdge(new Edge(2,3,5));
Edge[] tree=k.getTree();
for(Edge e:tree)
{
System.out.println(e.node1+" --> "+e.node2+" : "+e.weight);
}
}
}
运行结果如下:
2 --> 0 : 1
5 --> 2 : 4
3 --> 5 : 2
1 --> 2 : 5
4 --> 1 : 3
总结:kruskal算法的时间复杂度与求解最小生成树的图中的边数有关,而prim算法的时间复杂度与求解最小生成树的图中的节点的数目有关。为此,Kruskal算法更加适用于稀疏图,而prim算法适用于稠密图。当e>=n2时,kruskal算法比prim算法差,但当e=O(n2)时,kruskal算法却比prim算法好得多。
K:图相关的最小生成树(MST)的更多相关文章
- vue使用tradingview开发K线图相关问题
vue使用tradingview开发K线图相关问题 1.TradingView中文开发文档https://b.aitrade.ga/books/tradingview/CHANGE-LOG.html2 ...
- 图结构练习——最小生成树(prim算法(普里姆))
图结构练习——最小生成树 Time Limit: 1000ms Memory limit: 65536K 有疑问?点这里^_^ 题目描述 有n个城市,其中有些城市之间可以修建公路,修建不同 ...
- c/c++ 图相关的函数(二维数组法)
c/c++ 图相关的函数(二维数组法) 遍历图 插入顶点 添加顶点间的线 删除顶点 删除顶点间的线 摧毁图 取得与v顶点有连线的第一个顶点 取得与v1顶点,v1顶点之后的v2顶点的之后的有连线的第一个 ...
- 最小生成树MST算法(Prim、Kruskal)
最小生成树MST(Minimum Spanning Tree) (1)概念 一个有 n 个结点的连通图的生成树是原图的极小连通子图,且包含原图中的所有 n 个结点,并且有保持图连通的最少的边,所谓一个 ...
- 图结构练习——最小生成树(kruskal算法(克鲁斯卡尔))
图结构练习——最小生成树 Time Limit: 1000ms Memory limit: 65536K 有疑问?点这里^_^ 题目描述 有n个城市,其中有些城市之间可以修建公路,修建不同的公 ...
- 数据可视化:Echart中k图实现动态阈值报警及实时更新数据
1 目标 使用Echart的k图展现上下阈值,并且当真实值超过上阈值或低于下阈值时候,标红报警. 2 实现效果 如下:
- SPSS-Friedman 秩和检验-非参数检验-K个相关样本检验 案例解析
三人行,必有我师,是不是真有我师?三种不同类型的营销手段,最终的营销效果是否一样,随即区组秩和检验带你进入分析世界 今天跟大家讨论和分享一下:spss-Friedman 秩和检验-非参数检验-K个(多 ...
- 【算法与数据结构】图的最小生成树 MST - Prim 算法
Prim 算法属于贪心算法. #include <stdio.h> #define VERTEXNUM 7 #define INF 10000 typedef struct Graph { ...
- 图--生成树和最小生成树.RP
树(自由树).无序树和有根树 自由树就是一个无回路的连通图(没有确定根)(在自由树中选定一顶点做根,则成为一棵通常的树). 从根开始,为每个顶点(在树中通常称作结点)的孩子规定从左到右的次 ...
随机推荐
- webpack+babel项目在IE下报Promise未定义错误引出的思考
低版本浏览器引起的问题 最近开发一个基于webpack+babel+react的项目,一般本地是在chrome浏览上面开发,chrome浏览器开发因为支持大部分新的js特性,所以一般不怎么需要poly ...
- Win32界面 主函数分析
WinMain即(函数运行入口): p { margin-bottom: 0.25cm; line-height: 120% } int WINAPI WinMain (HINSTANCE hinst ...
- XMind常用快捷方式汇总
快捷键(Windows) 快捷键(Mac) 描述 Ctrl+N Command+N 建立新工作簿 Ctrl+O Command+O 开启工作簿 Ctrl+S Command+S 储存目前工作簿 Ctr ...
- mssql查询过去一段时间数据库中执行过的语句及执行效率
SELECT TOP 1000 ST.text AS '执行的SQL语句', QS.execution_count AS '执行次数', QS.total_elapsed_time AS '耗时', ...
- springboot整合redis
springboot-整合redis springboot学习笔记-4 整合Druid数据源和使用@Cache简化redis配置 一.整合Druid数据源 Druid是一个关系型数据库连接池,是阿 ...
- springMVC(4)---生成excel文件并导出
springMVC(4)---生成excel文件并导出 在开发过程中,需要将数据库中的数据以excel表格的方式导出. 首先说明.我这里用的是Apache的POI项目,它是目前比较成熟的HSSF接口, ...
- 第四节:dingo/API 最新版 V2.0 之 Responses (连载)
因为某些某些原因,不能按时更新,唉.我会尽力,加快速度.(这句话不是翻译的哈) 原文地址--> https://github.com/dingo/api/wiki/Responses A fun ...
- 手动安装cloudera manager 5.x(tar包方式)详解
官方共给出了3中安装方式:第一种方法必须要求所有机器都能连网,由于最近各种国外的网站被墙的厉害,我尝试了几次各种超时错误,巨耽误时间不说,一旦失败,重装非常痛苦.第二种方法下载很多包.第三种方法对系统 ...
- Android中style和theme的区别
在学习Xamarin android的过程中,最先开始学习的还是熟练掌握android的六大布局-LinearLayout .RelativeLayout.TableLayout.FrameLayou ...
- ArcGIS 网络分析[1.2] 利用1.1的线shp创建网络数据集/并简单试验最佳路径
上篇已经创建好了线数据(shp文件格式)链接:点我 这篇将基于此shp线数据创建网络数据集. 在此说明:shp数据的网络数据集仅支持单一线数据,也就是说基于shp文件的网络数据集,只能有一个shp线文 ...