使用numpy实现批量梯度下降的感知机模型
生成多维高斯分布随机样本
生成多维高斯分布所需要的均值向量和方差矩阵
这里使用numpy中的多变量正太分布随机样本生成函数,按照要求设置均值向量和协方差矩阵。以下设置两个辅助函数,用于指定随机变量维度,生成相应的均值向量和协方差矩阵。
import numpy as np
from numpy.random import multivariate_normal
from math import sqrt
均值向量生成函数
输入:
n:指定随机样本的维度
输出:
m1,m2:正类样本和负类样本的均值向量
def generate_mean_vector(n):
m1=1/np.sqrt(np.arange(1,n+1))
m2=-1/np.sqrt(np.arange(1,n+1))
return m1,m2
协方差矩阵生成函数
输入:
n:指定随机样本的维度
输出:
cov:协方差矩阵,特殊化为对角阵
def generate_cov_matrix(n):
cov=np.eye(n)
return cov/n
测试协方差矩阵生成函数
cov=generate_cov_matrix(3)
print(cov)
print(cov.shape)
[[ 0.33333333 0. 0. ]
[ 0. 0.33333333 0. ]
[ 0. 0. 0.33333333]]
(3, 3)
测试正负样本的均值矩阵生成函数
mean1,mean2=generate_mean_vector(3)
print(mean1)
print(mean2)
len(mean1)
[ 1. 0.70710678 0.57735027]
[-1. -0.70710678 -0.57735027]
3
生成多维高斯分布的数据点
这里之间调用numpy中的函数
def generate_data(m1,m2,n):
mean1,mean2=generate_mean_vector(n)
cov=generate_cov_matrix(n)
dataSet1=multivariate_normal(mean1,cov,m1)
dataSet2=multivariate_normal(mean2,cov,m2)
return dataSet1,dataSet2
测试数据点生成函数
generate_data(5,5,2)
(array([[ 1.22594293, 0.63712588],
[ 2.5778577 , 1.01123791],
[ 1.16177917, 0.26111813],
[ 0.27808353, 3.47596707],
[ 1.07724333, 1.72858977]]), array([[-1.62291142, -1.19754211],
[-1.0161682 , 0.9159203 ],
[-0.98557188, -2.15175781],
[-0.62078416, -1.11943163],
[-1.9053243 , -1.36074614]]))
二维数据分布的可视化
from matplotlib import pyplot
class1,class2=generate_data(10,10,2)
class1=np.transpose(class1)
class2=np.transpose(class2)
pyplot.plot(class1[0],class1[1],'ro')
pyplot.plot(class2[0],class2[1],'bo')
pyplot.show()
三维数据分布的可视化
#import matplotlib as mpl
#mpl.use('Agg')
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
class0,class1=generate_data(50,50,3)
class0=np.transpose(class0)
class1=np.transpose(class1)
fig=plt.figure()
ax=fig.add_subplot(111,projection='3d')
ax.scatter(class0[0],class0[1],class0[2],'ro')
ax.scatter(class1[0],class1[1],class1[2],'ro')
#fig.show()
pyplot.show()
感知机模型类
此模型的接口尽量与sklearn的模型接口保持一致
属性:
lr:learning rate,学习率
dim:样本空间的维度
weight:感知机模型的权重向量,包括偏置(在向量的最后一位)
方法:
init
输入:
lr:感知机模型的学习率
fit
输入:
X_train:训练样本的属性
y_train:训练样本的类别
epochs:算法迭代的最多次数
输出:模型的权重参数
predict
输入:
X:需要预测类别的样本集合
data_extend:布尔型变量,指示输入矩阵X是否经过了扩展预处理
输出:
result:预测结果向量
evaluate
输入:
X_test:测试集的样本属性
y_test:测试集的样本类别
data_extend:测试机样本矩阵是否经过了拓展
输出:
result:一个布尔向量,指示预测是否正确
get_weight
输出:
weight:模型的权重
class Perceptron():
def __init__(self,lr=0.01):
self.lr=lr
def fit(self,X_train,y_train,epochs=10):
#获取样本空间的维度
self.dim=X_train.shape[1]
#初始化权重为零,将最后一个权重作为偏置
self.weight=np.zeros((1,self.dim+1))
#拓展样本的维度,将偏置作为权重统一处理
X_train=np.hstack((X_train,np.ones((X_train.shape[0],1))))
epoch=0
while epoch < epochs:
epoch+=1
isCorrect=self.evaluate(X_train,y_train,data_extend=True)
#完全分类正确则停止迭代
if np.sum(isCorrect)==isCorrect.shape[0]:
break
X_error=X_train[np.logical_not(isCorrect)]
y_error=y_train[np.logical_not(isCorrect)]
self.weight=self.weight+self.lr*np.dot(y_error,X_error)
#返回预测结果向量
def predict(self,X,data_extend=False):
if data_extend==False:
X=np.hstack((X,np.ones((X.shape[0],1))))
p=np.dot(X,np.transpose(self.weight))
#注意:在这里p是二维数组,要将其转化为一维的
p=p.ravel()
p[p>0]=1;p[p<=0]=-1
return p
#返回布尔向量,如果预测为真则返回一,否则返回零
def evaluate(self,X_test,y_test,data_extend=False):
y_pred=self.predict(X_test,data_extend)
#注意这里是对应位置相乘(只有相乘的两个向量都为一维数组时才成立)
result=y_pred*y_test
return result==1
#返回模型参数,最后一个为偏置
def getweight(self):
return self.weight
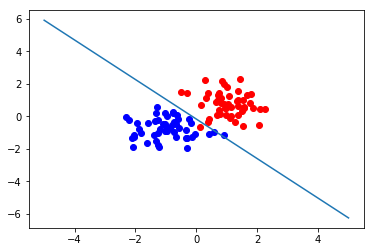
二维样本分类测试与可视化
def test_2d(m1=5,m2=5,epochs=10,lr=0.01):
X1,X2=generate_data(m1,m2,2)
X=np.vstack((X1,X2))
y=np.concatenate(([1]*m1,[-1]*m2))
model=Perceptron(lr)
model.fit(X,y,epochs)
np.transpose(np.matrix([1,2,3]))*3
c1=np.transpose(X1)
c2=np.transpose(X2)
pyplot.plot(c1[0],c1[1],'ro')
pyplot.plot(c2[0],c2[1],'bo')
w=model.getweight()
pyplot.plot([-5,5],[-1*w[0,2]/w[0,1]-w[0,0]/w[0,1]*-5,-1*w[0,2]/w[0,1]-w[0,0]/w[0,1]*5])
pyplot.show()
test_2d(50,50,1000,lr=0.01)

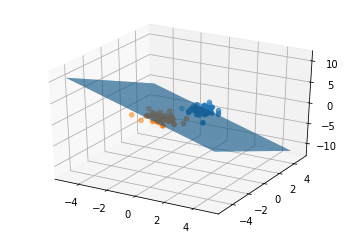
三维样本分类测试与可视化
def test_3d(m1=5,m2=5,epochs=10,lr=0.01):
X1,X2=generate_data(m1,m2,3)
X=np.vstack((X1,X2))
y=np.concatenate(([1]*m1,[-1]*m2))
model=Perceptron(lr)
model.fit(X,y,epochs)
#from matplotlib import pyplot
c0=np.transpose(X1)
c1=np.transpose(X2)
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
fig3=plt.figure()
ax=fig3.add_subplot(111,projection='3d')
ax.scatter(c0[0],c0[1],c0[2],'ro')
ax.scatter(c1[0],c1[1],c1[2],'ro')
w=model.getweight()
X=np.arange(-5,5,0.05);Y=np.arange(-5,5,0.05)
X,Y=np.meshgrid(X,Y)
Z=(w[0,0]*X+w[0,1]*Y+w[0,3])/(-1*w[0,2])
ax.plot_surface(X,Y,Z,rstride=1,cstride=1)
ax.set_facecolor('white')
ax.set_alpha(0.01)
#fig3.show()
pyplot.show()
test_3d(50,50,100)
使用numpy实现批量梯度下降的感知机模型的更多相关文章
- 【Python】机器学习之单变量线性回归 利用批量梯度下降找到合适的参数值
[Python]机器学习之单变量线性回归 利用批量梯度下降找到合适的参数值 本题目来自吴恩达机器学习视频. 题目: 你是一个餐厅的老板,你想在其他城市开分店,所以你得到了一些数据(数据在本文最下方), ...
- 随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )的公式对比、实现对比[转]
梯度下降(GD)是最小化风险函数.损失函数的一种常用方法,随机梯度下降和批量梯度下降是两种迭代求解思路,下面从公式和实现的角度对两者进行分析,如有哪个方面写的不对,希望网友纠正. 下面的h(x)是要拟 ...
- 【转】 随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )的公式对比、实现对比
梯度下降(GD)是最小化风险函数.损失函数的一种常用方法,随机梯度下降和批量梯度下降是两种迭代求解思路,下面从公式和实现的角度对两者进行分析,如有哪个方面写的不对,希望网友纠正. 下面的h(x)是要拟 ...
- batch gradient descent(批量梯度下降) 和 stochastic gradient descent(随机梯度下降)
批量梯度下降是一种对参数的update进行累积,然后批量更新的一种方式.用于在已知整个训练集时的一种训练方式,但对于大规模数据并不合适. 随机梯度下降是一种对参数随着样本训练,一个一个的及时updat ...
- 批量梯度下降(BGD)、随机梯度下降(SGD)以及小批量梯度下降(MBGD)的理解
梯度下降法作为机器学习中较常使用的优化算法,其有着三种不同的形式:批量梯度下降(Batch Gradient Descent).随机梯度下降(Stochastic Gradient Descent ...
- online learning,batch learning&批量梯度下降,随机梯度下降
以上几个概念之前没有完全弄清其含义及区别,容易混淆概念,在本文浅析一下: 一.online learning vs batch learning online learning强调的是学习是实时的,流 ...
- NN优化方法对照:梯度下降、随机梯度下降和批量梯度下降
1.前言 这几种方法呢都是在求最优解中常常出现的方法,主要是应用迭代的思想来逼近.在梯度下降算法中.都是环绕下面这个式子展开: 当中在上面的式子中hθ(x)代表.输入为x的时候的其当时θ參数下的输出值 ...
- 机器学习-随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )
梯度下降(GD)是最小化风险函数.损失函数的一种常用方法,随机梯度下降和批量梯度下降是两种迭代求解思路,下面从公式和实现的角度对两者进行分析,如有哪个方面写的不对,希望网友纠正. 下面的h(x)是要拟 ...
- Tensorflow细节-P84-梯度下降与批量梯度下降
1.批量梯度下降 批量梯度下降法是最原始的形式,它是指在每一次迭代时使用所有样本来进行梯度的更新.从数学上理解如下: 对应的目标函数(代价函数)即为: (1)对目标函数求偏导: (2)每次迭代对参数进 ...
随机推荐
- Java集合源码分析(一)ArrayList
前言 在前面的学习集合中只是介绍了集合的相关用法,我们想要更深入的去了解集合那就要通过我们去分析它的源码来了解它.希望对集合有一个更进一步的理解! 既然是看源码那我们要怎么看一个类的源码呢?这里我推荐 ...
- vue-cli 自定义指令directive 添加验证滑块
vue项目注册登录页面遇到了一个需要滑块的功能,网上看了很多插件发现都不太好用,于是自己写了一个插件供大家参考: 用的是vue的自定义指令direcive,只需要在需要的组件里放入对应的标签嵌套即可: ...
- AspxGridView控件的使用
在网上找到的不错的资料: http://www.lmwlove.com/ai/SubjectID6 以下是自我总结: 要实现的功能:使用AspxGridView显示Scott数据库中emp与dept两 ...
- layer.msg 添加在Ajax之前 显示进度条。
一.使用方法:1)必须先引入jQuery1.8或以上版本 <script src="jQuery的路径"></script> <script src= ...
- jemalloc 快速上手攻略
引言 - 赠送个 Cygwin (加精) Cygwin 有它存在的合理性. 至少比 wine 好太多了. 它主要功能是在winds上面简易的模拟出linux环境, 比虚拟机 轻量一点点. 坑也不少, ...
- python学习之第三课时--基本数据类型及区别,变量
基本数据类型及区别 1. 数字类型(int) 数字型--变量值直接是数字,没有双引号"" 整数 2. 浮点数(float) 肤浅理解小数点后有有效数字 1.55 0.22 ...
- Spring源码情操陶冶-AOP之ConfigBeanDefinitionParser解析器
aop-Aspect Oriented Programming,面向切面编程.根据百度百科的解释,其通过预编译方式和运行期动态代理实现程序功能的一种技术.主要目的是为了程序间的解耦,常用于日志记录.事 ...
- Linux.根据进程名关键字杀进程
先看例子, 假设系统中有以下2个进程 USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root ...
- Vue源码后记-其余内置指令(1)
把其余的内置指令也搞完吧,来一个全家桶. 案例如下: <body> <div id='app'> <div v-if="vIfIter" v-bind ...
- Element ui表格展示多张图片问题
显示一张图片的方法: <el-table-column label="头像" width="100"> <template scope=&qu ...