在Eclipse中开发MapReduce程序
一、Eclipse的安装与设置
1.在Eclipse官网上下载eclipse-jee-oxygen-3a-linux-gtk-x86_64.tar.gz文件并将其拷贝到/home/jun/Resources下,然后再将文件拷贝到/home/jun下并解压。
[jun@master ~]$ cp /home/jun/Resources/eclipse-jee-oxygen-3a-linux-gtk-x86_64.tar.gz /home/jun/
[jun@master ~]$ tar -zxvf /home/jun/eclipse-jee-oxygen-3a-linux-gtk-x86_64.tar.gz
2.执行.eclipse程序即可启动eclipse
[jun@master ~]$ cd eclipse/
[jun@master eclipse]$ ls
artifacts.xml configuration dropins eclipse eclipse.ini features icon.xpm p2 plugins readme
[jun@master eclipse]$ ./eclipse
3.安装hadoop插件
(1)下载:https://github.com/winghc/hadoop2x-eclipse-plugin/blob/master/release/hadoop-eclipse-plugin-2.6.0.jar
(2)将hadoop-eclipse-plugin-2.6.0.jar放到/home/jun/eclipse/plugins下
(3)启动eclipse,选择Window→Preferences→Hadoop Map/Reduce→Hadoop installation directory→选择/home/jun/hadoop
(4)选择Window→Show View→Other→MapReduce Tools→Map/Reduce Locations→OK
(5)在下方Map/Reduce Locations子窗口内空白部分右键-New Hadoop Location
(6)按下图进行配置,点击Finish
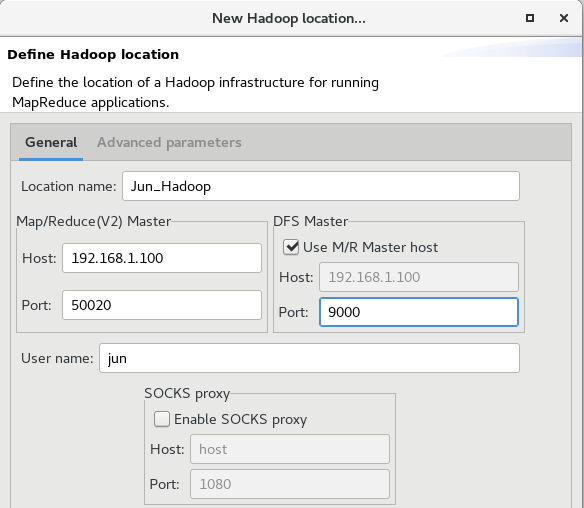
(7)在左边看到下面图即可
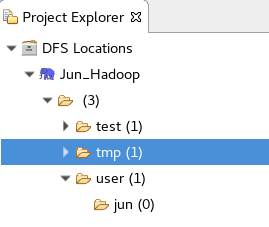
二、在Eclipse上开发MapReduce程序
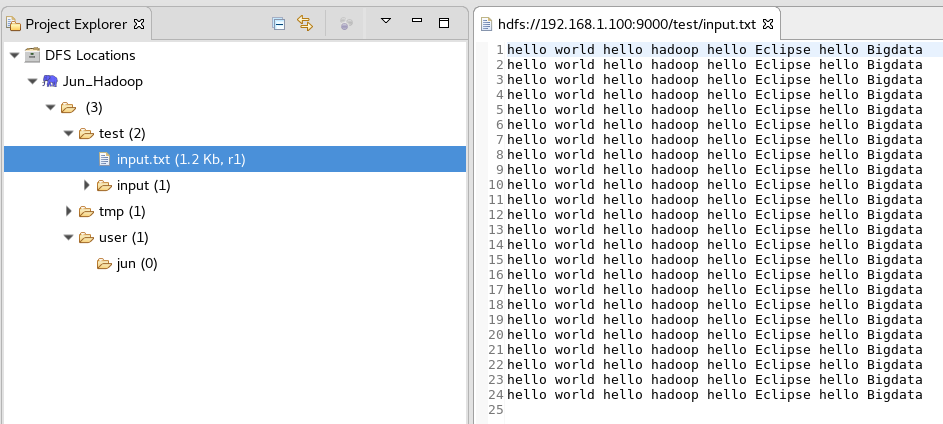
1.新建input.txt并上传到HDFS的/test文件夹中,在eclipse中右键点击Refresh即可看到刚刚上传的文件。在eclipse中可以进行文件目录创建、文件上传、文件下载、文件或文件夹删除等操作,但是不能编辑文件内容。
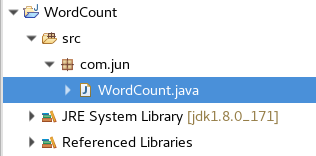
2.新建项目
选择File→New→Other→Map/Reduce Project→Next→Project name{WordCount}→Next→Finish
然后新建包和类
3.获得源码
桌面上进入
选择hadoop-mapreduce-examples-2.8.4-sources.jar并右键Open With Archive Manager,找到WordCount.java用gedit打开即可得到源码
然后将源码复制到eclipse新建的类中
4.运行程序
在java文件上右键点击Run As→Run Configurations→Java Application→Arguments
第一个参数是输入文件,第二个参数是输出目录(必须之前不存在),然后点击Apply

在Java文件上右键Run As→Run on Hadoop
然后在Hadoop的test目录下新增了output子目录,且下面有两个文件,其中part-r-000000包含了计算结果
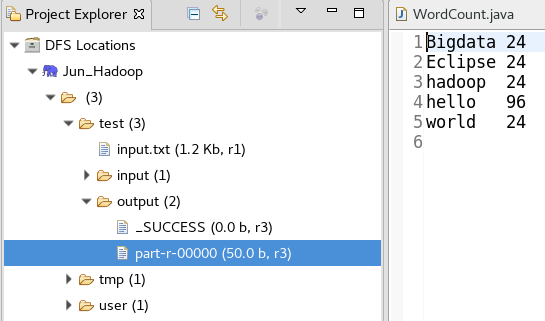
到这里,就完成了第一个在Eclipse上开发并运行MapReduce程序。
在Eclipse中开发MapReduce程序的更多相关文章
- 使用Eclipse编译运行MapReduce程序 Hadoop2.6.0_Ubuntu/CentOS
使用Eclipse编译运行MapReduce程序 Hadoop2.6.0_Ubuntu/CentOS 2014-10-10 (updated: 2016-05-22) 64246 153 本教程介绍 ...
- windows环境下Eclipse开发MapReduce程序遇到的四个问题及解决办法
按此文章<Hadoop集群(第7期)_Eclipse开发环境设置>进行MapReduce开发环境搭建的过程中遇到一些问题,饶了一些弯路,解决办法记录在此: 文档目的: 记录windows环 ...
- [MapReduce_add_1] Windows 下开发 MapReduce 程序部署到集群
0. 说明 Windows 下开发 MapReduce 程序部署到集群 1. 前提 在本地开发的时候保证 resource 中包含以下配置文件,从集群的配置文件中拷贝 在 resource 中新建 ...
- 在Eclipse中开发C/C++项目
摘要:通过本文你将获得如何在Eclipse平台上开发C/C++项目的总体认识.虽然Eclipse主要被用来开发Java项目,但它的框架使得它很容易实现对其他开发语言的支持.在这篇文章里,你将学会如何使 ...
- 本地idea开发mapreduce程序提交到远程hadoop集群执行
https://www.codetd.com/article/664330 https://blog.csdn.net/dream_an/article/details/84342770 通过idea ...
- cygwin,在win中开发linux程序
cygwin,在win中开发linux程序 http://www.cygwin.cn/site/info/show.php?IID=1001 很多用windows的朋友不习惯于用linux的开发环境 ...
- 老李分享:Eclipse中开发性能测试loadrunner脚本
老李分享:Eclipse中开发性能测试loadrunner脚本 前篇我分享了如何用loadrunner搭建javauser的性能测试脚本环境,本次我来告诉大家如何在eclipse开发loadrunne ...
- Ubuntu下Eclipse中运行Hadoop程序的参数问题
需要统一的参数: 当配置好eclipse中hadoop的程序后,几个参数需要统一一下: hadoop安装目录下/etc/core_site.xml中 fs.default.name的端口号一定要与ha ...
- 在Eclipse中运行hadoop程序
1.下载hadoop-eclipse-plugin-1.2.1.jar,并将之复制到eclipse/plugins下. 2.打开map-reduce视图 在eclipse中,打开window--> ...
随机推荐
- NN and the Optical Illusion-光学幻觉 CodeForce1100C 几何
题目链接:NN and the Optical Illusion 题目原文 NN is an experienced internet user and that means he spends a ...
- JMeter 压测Server Agent无法监控资源问题,PerfMon Metrics Collector报Waiting for sample,Error loading results file - see file log, Can't accept UDP connections java.net.BindException: Address already in use 各种疑难杂症
如何安装插件此博主已经说得很详细了. https://www.cnblogs.com/saryli/p/6596647.html 但是需注意几点: 1.修改默认端口,这样可以避免掉一个问题.Serve ...
- phpStudy后门漏洞利用复现
phpStudy后门漏洞利用复现 一.漏洞描述 Phpstudy软件是国内的一款免费的PHP调试环境的程序集成包,通过集成Apache.PHP.MySQL.phpMyAdmin.ZendOptimiz ...
- 十分钟快速学会Matplotlib基本图形操作
在学习Python的各种工具包的时候,看网上的各种教程总是感觉各种方法很多很杂,参数的种类和个数也十分的多,理解起来需要花费不少的时间. 所以我在这里通过几个例子,对方法和每个参数都进行详细的解释,这 ...
- .net core 3.0 Signalr - 07 业务实现-服务端 自定义管理组、用户、连接
Hub的管理 重写OnConnectedAsync 从连接信息中获取UserId.Groups,ConnectId,并实现这三者的关系,存放于redis中 代码请查看 using CTS.Signal ...
- Thinkphp5.0第三篇
批量插入数据 //新增一条数据的方法 public function add() { /*$user =new UserModel(); $user->id=1; $user->name= ...
- KafkaStream简介
Kafka Streams 1 概述 Kafka Streams是一个客户端程序库,用于处理和分析存储在Kafka中的数据,并将得到的数据写回Kafka或发送到外部系统.Kafka Stream基于一 ...
- python编程基础之二十七
列表生成式:[exp for iter_var in iterable] 同样也会有字典生成式,集合生成式,没有元组生成式,元组生成式的语法被占用了 字典生成式,集合生成式,就是外面那个括号换成{} ...
- 基于 WebGL 的 3D 动态柱状图表
发现现在工业SCADA上或者电信网管方面用图表的特别多,虽然绝大部分人在图表制作方面用的是echarts,他确实好用,但是有些时候我们不能调用别的插件,这个时候就得自己写这些美丽的图表了,然而图表轻易 ...
- 常见Failed to load ApplicationContext异常解决方案!!
java.lang.IllegalStateException: Failed to load ApplicationContext at org.springframework.test.conte ...