Spark机器学习(9):FPGrowth算法
关联规则挖掘最典型的例子是购物篮分析,通过分析可以知道哪些商品经常被一起购买,从而可以改进商品货架的布局。
1. 基本概念
首先,介绍一些基本概念。
(1) 关联规则:用于表示数据内隐含的关联性,一般用X表示先决条件,Y表示关联结果。
(2) 支持度(Support):所有项集中{X,Y}出现的可能性。
(3) 置信度(Confidence):先决条件X发生的条件下,关联结果Y发生的概率。
2. Apriori算法
Apriori算法是常用的关联规则挖掘算法,基本思想是:
(1) 先搜索出1项集及其对应的支持度,删除低于支持度的项集,得到频繁1项集L1;
(2) 对L1中的项集进行连接,得到一个候选集,删除其中低于支持度的项集,得到频繁1项集L2;
...
迭代下去,一直到无法找到L(k+1)为止,对应的频繁k项集集合就是最后的结果。
Apriori算法的缺点是对于候选项集里面的每一项都要扫描一次数据,从而需要多次扫描数据,I/O操作多,效率低。为了提高效率,提出了一些基于Apriori的算法,比如FPGrowth算法。
3. FPGrowth算法
FPGrowth算法为了减少I/O操作,提高效率,引入了一些数据结构存储数据,主要包括项头表、FP-Tree和节点链表。
3.1 项头表
项头表(Header Table)即找出频繁1项集,删除低于支持度的项集,并按照出现的次数降序排序,这是第一次扫描数据。然后从数据中删除非频繁1项集,并按照项头表的顺序排序,这是第二次也是最后一次扫描数据。
下面的例子,支持度=0.4,阈值=0.4*10=4,因为D、F、G出现次数小于4次,小于阈值,所以被删除,项头表按照各一项集出现的次数重新排序。如ABCE=>EABC。

3.2 FP-Tree
3.2.1 FP-Tree的建立
FP-Tree(Frequent Pattern Tree)初始时只有一个根节点Null,将每一条数据里的每一项,按照排序后的顺序插入FP-Tree,节点的计数为1,如果有共用的祖先,则共用祖先的节点计数+1。
首先,插入第1条数据E:

插入第2条数据ABC:

插入第3条数据EABC:
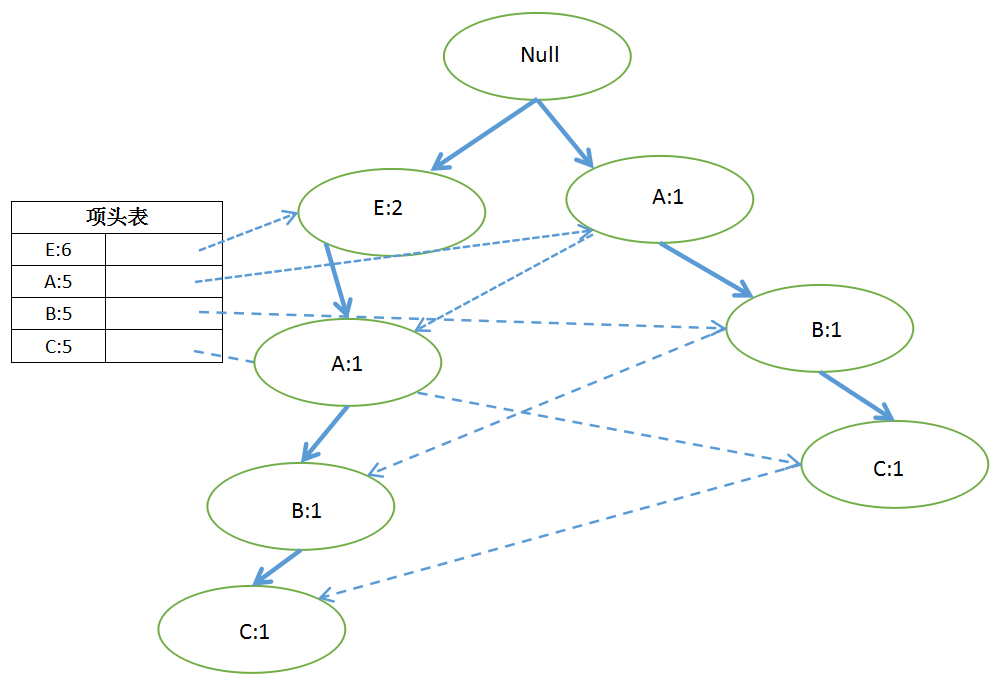
以此类推,所有数据都插入以后:

3.2.2 FP-Tree的挖掘过程
FP-Tree的挖掘过程如下,从长度为1的频繁模式开始挖掘。可以分为3个步骤:
(1) 构造它的条件模式基(CPB, Conditional Pattern Base),条件模式基(CPB)就是我们要挖掘的Item的前缀路径;
(2) 然后构造它的条件FP-Tree(Conditional FP-tree);
(3) 递归的在条件FP Tree上进行挖掘。
从项头表的最下面一项(也就是C)开始,包含C的3个CPB分别是EAB、E、AB,其计数分别为2、1、2,可以表示为CPB{<EAB:2>,<E:1>,<AB:2>}。累加每个CPB上的Item计数,低于阈值的删除,得到条件FP Tree(Conditional FP-tree)。如CPB{<EAB:2>,<E:1>,<AB:2>},得到E:3,A:4,B:4,E的计数小于阈值4,所以删除,得到C的条件FP Tree如下:

在条件FP Tree上使用如下的算法进行挖掘:
procedure FP_growth(Tree, α){
if Tree 含单个路径P {
for 路径 P 中结点的每个组合(记作β){
产生模式β ∪ α,其支持度support = β中结点的最小支持度;
}
}
else {
for each a i 在 Tree 的头部 {
产生一个模式β = ai ∪ α,其支持度support = ai.support;
构造β的条件模式基,然后构造β的条件FP Tree Treeβ;
if Treeβ ≠ ∅ then
调用FP_growth (Treeβ, β);}
}
}
对于上面的条件FP Tree,可知是单个路径,可以得到以下的频繁模式:<AC:4>、<BC:4>、<ABC:4>。
4. MLlib的FPGrowth算法
直接上代码:
import org.apache.log4j.{ Level, Logger }
import org.apache.spark.{ SparkConf, SparkContext }
import org.apache.spark.rdd.RDD
import org.apache.spark.mllib.fpm.{ FPGrowth, FPGrowthModel }
/**
* Created by Administrator on 2017/7/16.
*/
object FPGrowth {
def main(args:Array[String]) ={
// 设置运行环境
val conf = new SparkConf().setAppName("FPGrowth")
.setMaster("spark://master:7077").setJars(Seq("E:\\Intellij\\Projects\\MachineLearning\\MachineLearning.jar"))
val sc = new SparkContext(conf)
Logger.getRootLogger.setLevel(Level.WARN)
// 读取样本数据并解析
val dataRDD = sc.textFile("hdfs://master:9000/ml/data/sample_fpgrowth.txt")
val exampleRDD = dataRDD.map(_.split(" ")).cache()
// 建立FPGrowth模型,最小支持度为0.4
val minSupport = 0.4
val numPartition = 10
val model = new FPGrowth().
setMinSupport(minSupport).
setNumPartitions(numPartition).
run(exampleRDD)
// 输出结果
println(s"Number of frequent itemsets: ${model.freqItemsets.count()}")
model.freqItemsets.collect().foreach { itemset =>
println(itemset.items.mkString("[", ",", "]") + ":" + itemset.freq)
}
}
}
样本数据:
D E
A B C
A B C E
B E
C D E
A B C
A B C E
B E
F G
D F
运行结果:

参考文献:《数据挖掘概念与技术》。
Spark机器学习(9):FPGrowth算法的更多相关文章
- 机器学习实战 - 读书笔记(12) - 使用FP-growth算法来高效发现频繁项集
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第12章 - 使用FP-growth算法来高效发现频繁项集. 基本概念 FP-growt ...
- Spark机器学习之协同过滤算法
Spark机器学习之协同过滤算法 一).协同过滤 1.1 概念 协同过滤是一种借助"集体计算"的途径.它利用大量已有的用户偏好来估计用户对其未接触过的物品的喜好程度.其内在思想是相 ...
- 机器学习实战(Machine Learning in Action)学习笔记————08.使用FPgrowth算法来高效发现频繁项集
机器学习实战(Machine Learning in Action)学习笔记————08.使用FPgrowth算法来高效发现频繁项集 关键字:FPgrowth.频繁项集.条件FP树.非监督学习作者:米 ...
- 基于Spark的FPGrowth算法的运用
一.FPGrowth算法理解 Spark.mllib 提供并行FP-growth算法,这个算法属于关联规则算法[关联规则:两不相交的非空集合A.B,如果A=>B,就说A=>B是一条关联规则 ...
- 【机器学习实战】第12章 使用FP-growth算法来高效发现频繁项集
第12章 使用FP-growth算法来高效发现频繁项集 前言 在 第11章 时我们已经介绍了用 Apriori 算法发现 频繁项集 与 关联规则.本章将继续关注发现 频繁项集 这一任务,并使用 FP- ...
- Spark机器学习(8):LDA主题模型算法
1. LDA基础知识 LDA(Latent Dirichlet Allocation)是一种主题模型.LDA一个三层贝叶斯概率模型,包含词.主题和文档三层结构. LDA是一个生成模型,可以用来生成一篇 ...
- 机器学习之Apriori算法和FP-growth算法
1 关联分析 无监督机器学习方法中的关联分析问题.关联分析可以用于回答"哪些商品经常被同时购买?"之类的问题. 2 Apriori算法 频繁项集即出现次数多的数据集 支持度 ...
- 机器学习(九)—FP-growth算法
本来老师是想让我学Hadoop的,也装了Ubuntu,配置了Hadoop,一时间却不知从何学起,加之自己还是想先看点自己喜欢的算法,学习Hadoop也就暂且搁置了,不过还是想问一下园子里的朋友有什么学 ...
- 《机器学习实战》学习笔记第十二章 —— FP-growth算法
主要内容: 一. FP-growth算法简介 二.构建FP树 三.从一颗FP树中挖掘频繁项集 一. FP-growth算法简介 1.上次提到可以用Apriori算法来提取频繁项集,但是Aprior ...
随机推荐
- [转] Java中public,private,final,static等概念的解读
作为刚入门Java的小白,对于public,private,final,static等概念总是搞不清楚,到底都代表着什么,这里做一个简单的梳理,和大家分享,若有错误请指正,谢谢~ 访问权限修饰符 pu ...
- Linux使用netstat命令查看并发连接数
我们的网站部署在linux的服务器上,特别是web服务器,我们可能有时候做为运维人员,肯定是要查看网站的并发连接数是不是达到瓶颈等,所以在linux下,我们如何查看服务器的并发连接数呢?使用以下命令即 ...
- 075 importSTV的使用,与bulkload的使用
一:由HDFS将数据直接导入到HBase中 1.生成TSV文件 2.内容 3.上传到HDFS 4.运行 export HBASE_HOME=/etc/opt/modules/hbase-0.98.6- ...
- Unity 之 中文乱码
更改 C#脚本的编码格式: 文件 -> 高级保存选项 -> Unicode
- [OpenCV-Python] OpenCV 中的 Gui特性 部分 II
部分 IIOpenCV 中的 Gui 特性 OpenCV-Python 中文教程(搬运)目录 4 图片 目标 • 在这里你将学会怎样读入一幅图像,怎样显示一幅图像,以及如何保存一幅图像 • 你将要学习 ...
- linux 重要笔记
nginx 服务器重启命令,关闭 nginx -s reload :修改配置后重新加载生效 nginx -s reopen :重新打开日志文件nginx -t -c /path/to/ngin ...
- JDBC fetch size
make your java run faster A blog on java performance and optimization. On JDBC, Hibernate, caching, ...
- BZOJ.1016.[JSOI2008]最小生成树计数(Matrix Tree定理 Kruskal)
题目链接 最小生成树有两个性质: 1.在不同的MST中某种权值的边出现的次数是一定的. 2.在不同的MST中,连接完某种权值的边后,形成的连通块的状态是一样的. \(Solution1\) 由这两个性 ...
- C++学习笔记40:进程应用
进程创建 system()函数:用于在程序中执行一条命令 如果shell不能运行,返回127,如果发生其他错误返回-1: 例子:int ret_val = system(“ls -l /”); for ...
- python 字符串的一些方法
总结:# split 分割 ********# strip 脱 默认脱头尾的空格 ********# replace 替换 ********# join 插入 拼接 ********# format ...