用go语言爬取珍爱网 | 第一回

我们来用go语言爬取“珍爱网”用户信息。
首先分析到请求url为:
http://www.zhenai.com/zhenghun
接下来用go请求该url,代码如下:
package main
import (
"fmt"
"io/ioutil"
"net/http"
)
func main() {
//返送请求获取返回结果
resp, err := http.Get("http://www.zhenai.com/zhenghun")
if err != nil {
panic(fmt.Errorf("Error: http Get, err is %v\n", err))
}
//关闭response body
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
fmt.Println("Error: statuscode is ", resp.StatusCode)
return
}
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Println("Error read body, error is ", err)
}
//打印返回值
fmt.Println("body is ", string(body))
}
运行后会发现返回体里有很多乱码:
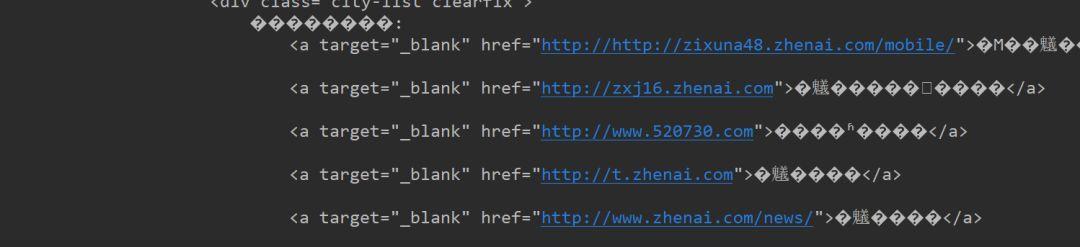
在返回体里可以找到 即编码为gbk,而go默认编码为utf-8,所以就会出现乱码。接下来用第三方库将其编码格式转为utf-8。
由于访问golang.org/x/text需要梯子,不然报错:

所以在github上下载:
mkdir -p $GOPATH/src/golang.org/x
cd $GOPATH/src/golang.org/x
git clone https://github.com/golang/text.git
然后将gbk编码转换为utf-8,需要修改代码如下:
utf8Reader := transform.NewReader(resp.Body, simplifiedchinese.GBK.NewDecoder())
body, err := ioutil.ReadAll(utf8Reader)
考虑到通用性,返回的编码格式不一定是gbk,所以需要对实际编码做判断,然后将判断结果转为utf-8,需要用到第三方库golang.org/x/net/html,同样的在github上下载:
mkdir -p $GOPATH/src/golang.org/x
cd $GOPATH/src/golang.org/x
git clone https://github.com/golang/net
那么代码就变成这样:
package main
import (
"fmt"
"io/ioutil"
"net/http"
"golang.org/x/text/transform"
//"golang.org/x/text/encoding/simplifiedchinese"
"io"
"golang.org/x/text/encoding"
"bufio"
"golang.org/x/net/html/charset"
)
func main() {
//返送请求获取返回结果
resp, err := http.Get("http://www.zhenai.com/zhenghun")
if err != nil {
panic(fmt.Errorf("Error: http Get, err is %v\n", err))
}
//关闭response body
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
fmt.Println("Error: statuscode is ", resp.StatusCode)
return
}
//utf8Reader := transform.NewReader(resp.Body, simplifiedchinese.GBK.NewDecoder())
utf8Reader := transform.NewReader(resp.Body, determinEncoding(resp.Body).NewDecoder())
body, err := ioutil.ReadAll(utf8Reader)
if err != nil {
fmt.Println("Error read body, error is ", err)
}
//打印返回值
fmt.Println("body is ", string(body))
}
func determinEncoding(r io.Reader) encoding.Encoding {
//这里的r读取完得保证resp.Body还可读
body, err := bufio.NewReader(r).Peek(1024)
if err != nil {
fmt.Println("Error: peek 1024 byte of body err is ", err)
}
//这里简化,不取是否确认
e, _, _ := charset.DetermineEncoding(body, "")
return e
}
运行后就看不到乱码了:
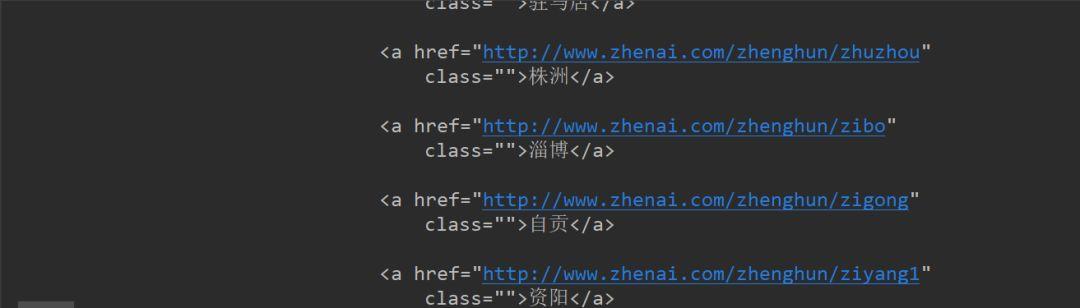
今天先爬到这里,明天将提取返回体中的地址URL和城市,下一节见。
本公众号免费提供csdn下载服务,海量IT学习资源,如果你准备入IT坑,励志成为优秀的程序猿,那么这些资源很适合你,包括但不限于java、go、python、springcloud、elk、嵌入式 、大数据、面试资料、前端 等资源。同时我们组建了一个技术交流群,里面有很多大佬,会不定时分享技术文章,如果你想来一起学习提高,可以公众号后台回复【2】,免费邀请加技术交流群互相学习提高,会不定期分享编程IT相关资源。
扫码关注,精彩内容第一时间推给你

用go语言爬取珍爱网 | 第一回的更多相关文章
- 用go语言爬取珍爱网 | 第三回
前两节我们获取到了城市的URL和城市名,今天我们来解析用户信息. 用go语言爬取珍爱网 | 第一回 用go语言爬取珍爱网 | 第二回 爬虫的算法: 我们要提取返回体中的城市列表,需要用到城市列表解析器 ...
- 用go语言爬取珍爱网 | 第二回
昨天我们一起爬取珍爱网首页,拿到了城市列表页面,接下来在返回体城市列表中提取城市和url,即下图中的a标签里的href的值和innerText值. 提取a标签,可以通过CSS选择器来选择,如下: $( ...
- python爬虫06 | 你的第一个爬虫,爬取当当网 Top 500 本五星好评书籍
来啦,老弟 我们已经知道怎么使用 Requests 进行各种请求骚操作 也知道了对服务器返回的数据如何使用 正则表达式 来过滤我们想要的内容 ... 那么接下来 我们就使用 requests 和 re ...
- 使用python爬取东方财富网机构调研数据
最近有一个需求,需要爬取东方财富网的机构调研数据.数据所在的网页地址为: 机构调研 网页如下所示: 可见数据共有8464页,此处不能直接使用scrapy爬虫进行爬取,因为点击下一页时,浏览器只是发起了 ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- 爬虫入门(四)——Scrapy框架入门:使用Scrapy框架爬取全书网小说数据
为了入门scrapy框架,昨天写了一个爬取静态小说网站的小程序 下面我们尝试爬取全书网中网游动漫类小说的书籍信息. 一.准备阶段 明确一下爬虫页面分析的思路: 对于书籍列表页:我们需要知道打开单本书籍 ...
- [转]使用python爬取东方财富网机构调研数据
最近有一个需求,需要爬取东方财富网的机构调研数据.数据所在的网页地址为: 机构调研 网页如下所示: 可见数据共有8464页,此处不能直接使用scrapy爬虫进行爬取,因为点击下一页时,浏览器只是发起了 ...
- Python爬虫项目--爬取自如网房源信息
本次爬取自如网房源信息所用到的知识点: 1. requests get请求 2. lxml解析html 3. Xpath 4. MongoDB存储 正文 1.分析目标站点 1. url: http:/ ...
- GoLang爬取花瓣网美女图片
由于之前一直想爬取花瓣网(http://huaban.com/partner/uc/aimeinv/pins/) 的图片,又迫于没时间,所以拖了很久. 鉴于最近在学go语言,就刚好用这个练手了. 预览 ...
随机推荐
- 个人IP「Android大强哥」上线啦!
自从入职新公司之后就一直忙得不行,一边熟悉开发的流程,一边熟悉各种网站工具的使用,一边又在熟悉业务代码,好长时间都没有更文了. 不过新公司的 mentor(导师)还是很不错的,教给我很多东西,让我也能 ...
- 策略模式+注解 干掉业务代码中冗余的if else...
前言: 之前写过一个工作中常见升级模式-策略模式 的文章,里面讲了具体是怎样使用策略模式去抽象现实中的业务代码,今天来拿出实际代码来写个demo,这里做个整理来加深自己对策略模式的理解. 一.业务 ...
- Winform中使用FastReport的DesignReport时怎样给通过代码Table添加数据
场景 FastReport安装包下载.安装.去除使用限制以及工具箱中添加控件: https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/10 ...
- Hadoop学习笔记之HBase Shell语法练习
Hadoop学习笔记之HBase Shell语法练习 作者:hugengyong 下面我们看看HBase Shell的一些基本操作命令,我列出了几个常用的HBase Shell命令,如下: 名称 命令 ...
- Vscode for python ide配置
1.文件头添加 自定义代码片段 文件>首选项>用户代码片段 搜索python 添加代码 "HEADER":{ "prefix": "hea ...
- Git客户端下载
链接:http://pan.baidu.com/s/1eRXsITO 密码:4i6e
- PythonI/O进阶学习笔记_6.对象引用,可变性和垃圾回收
前言: 没有前言了- -......这系列是整理的以前的笔记上传的,有些我自己都忘记我当时记笔记的关联关系了. 记住以后 笔记记了就是用来复习的!!!不看不就啥用没了吗!!! content: 1.p ...
- CDH健康检查报DATA_NODE_BLOCK_COUNT告警
告警原文: The health test result for DATA_NODE_BLOCK_COUNT has become concerning: The DataNode has 500,0 ...
- [Spark] 00 - Install Hadoop & Spark
Hadoop安装 Java环境配置 安装课程:安装配置 配置手册:Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04[依照步骤完成配置] jsk安装使用的链接中第 ...
- [STL] Implement "vector", ”deque“ and "list"
vector “可增的”数组 vector是一块连续分配的内存,从数据安排的角度来讲,和数组极其相似. 不同的地方就是: (1) 数组是静态分配空间,一旦分配了空间的大小,就不可再改变了: (2) v ...