用go语言爬取珍爱网 | 第一回

我们来用go语言爬取“珍爱网”用户信息。
首先分析到请求url为:
http://www.zhenai.com/zhenghun
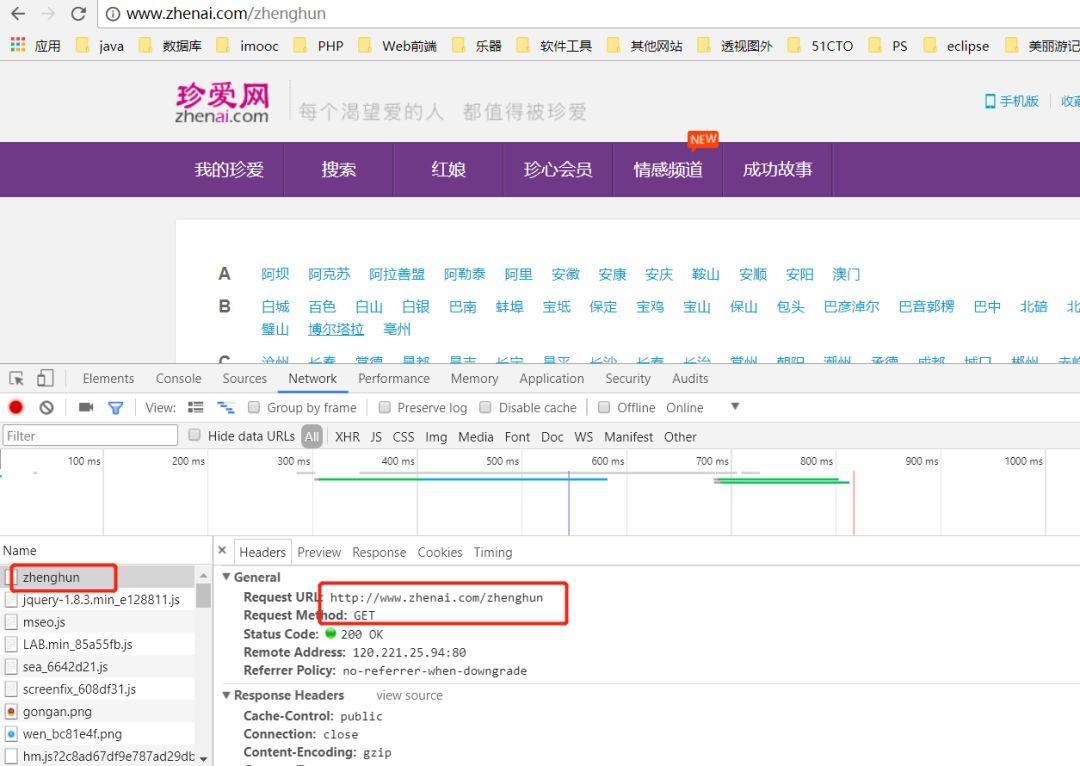
接下来用go请求该url,代码如下:
package main
import (
"fmt"
"io/ioutil"
"net/http"
)
func main() {
//返送请求获取返回结果
resp, err := http.Get("http://www.zhenai.com/zhenghun")
if err != nil {
panic(fmt.Errorf("Error: http Get, err is %v\n", err))
}
//关闭response body
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
fmt.Println("Error: statuscode is ", resp.StatusCode)
return
}
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Println("Error read body, error is ", err)
}
//打印返回值
fmt.Println("body is ", string(body))
}
运行后会发现返回体里有很多乱码:
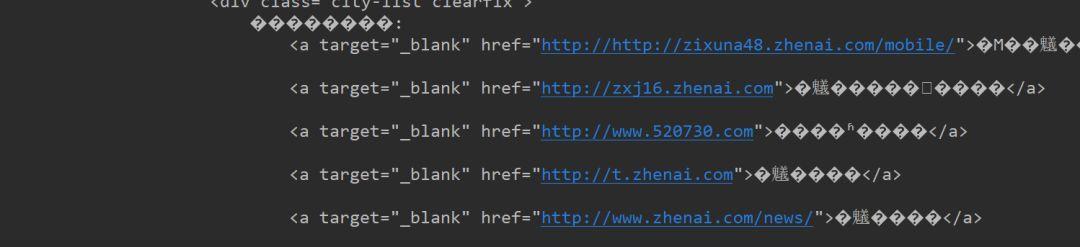
在返回体里可以找到 即编码为gbk,而go默认编码为utf-8,所以就会出现乱码。接下来用第三方库将其编码格式转为utf-8。
由于访问golang.org/x/text需要梯子,不然报错:

所以在github上下载:
mkdir -p $GOPATH/src/golang.org/x
cd $GOPATH/src/golang.org/x
git clone https://github.com/golang/text.git
然后将gbk编码转换为utf-8,需要修改代码如下:
utf8Reader := transform.NewReader(resp.Body, simplifiedchinese.GBK.NewDecoder())
body, err := ioutil.ReadAll(utf8Reader)
考虑到通用性,返回的编码格式不一定是gbk,所以需要对实际编码做判断,然后将判断结果转为utf-8,需要用到第三方库golang.org/x/net/html,同样的在github上下载:
mkdir -p $GOPATH/src/golang.org/x
cd $GOPATH/src/golang.org/x
git clone https://github.com/golang/net
那么代码就变成这样:
package main
import (
"fmt"
"io/ioutil"
"net/http"
"golang.org/x/text/transform"
//"golang.org/x/text/encoding/simplifiedchinese"
"io"
"golang.org/x/text/encoding"
"bufio"
"golang.org/x/net/html/charset"
)
func main() {
//返送请求获取返回结果
resp, err := http.Get("http://www.zhenai.com/zhenghun")
if err != nil {
panic(fmt.Errorf("Error: http Get, err is %v\n", err))
}
//关闭response body
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
fmt.Println("Error: statuscode is ", resp.StatusCode)
return
}
//utf8Reader := transform.NewReader(resp.Body, simplifiedchinese.GBK.NewDecoder())
utf8Reader := transform.NewReader(resp.Body, determinEncoding(resp.Body).NewDecoder())
body, err := ioutil.ReadAll(utf8Reader)
if err != nil {
fmt.Println("Error read body, error is ", err)
}
//打印返回值
fmt.Println("body is ", string(body))
}
func determinEncoding(r io.Reader) encoding.Encoding {
//这里的r读取完得保证resp.Body还可读
body, err := bufio.NewReader(r).Peek(1024)
if err != nil {
fmt.Println("Error: peek 1024 byte of body err is ", err)
}
//这里简化,不取是否确认
e, _, _ := charset.DetermineEncoding(body, "")
return e
}
运行后就看不到乱码了:
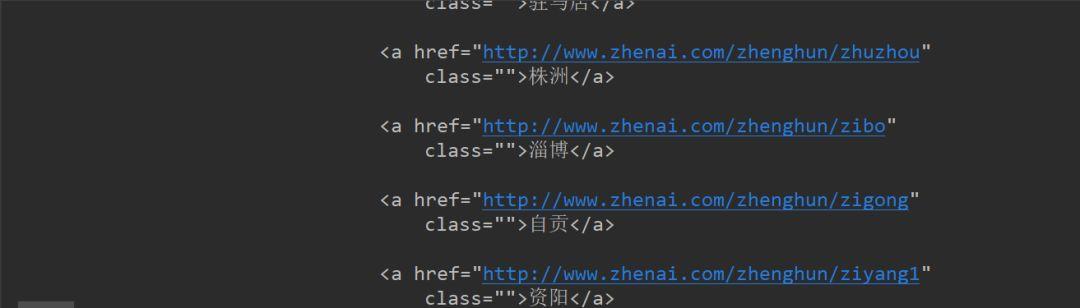
今天先爬到这里,明天将提取返回体中的地址URL和城市,下一节见。
本公众号免费提供csdn下载服务,海量IT学习资源,如果你准备入IT坑,励志成为优秀的程序猿,那么这些资源很适合你,包括但不限于java、go、python、springcloud、elk、嵌入式 、大数据、面试资料、前端 等资源。同时我们组建了一个技术交流群,里面有很多大佬,会不定时分享技术文章,如果你想来一起学习提高,可以公众号后台回复【2】,免费邀请加技术交流群互相学习提高,会不定期分享编程IT相关资源。
扫码关注,精彩内容第一时间推给你

用go语言爬取珍爱网 | 第一回的更多相关文章
- 用go语言爬取珍爱网 | 第三回
前两节我们获取到了城市的URL和城市名,今天我们来解析用户信息. 用go语言爬取珍爱网 | 第一回 用go语言爬取珍爱网 | 第二回 爬虫的算法: 我们要提取返回体中的城市列表,需要用到城市列表解析器 ...
- 用go语言爬取珍爱网 | 第二回
昨天我们一起爬取珍爱网首页,拿到了城市列表页面,接下来在返回体城市列表中提取城市和url,即下图中的a标签里的href的值和innerText值. 提取a标签,可以通过CSS选择器来选择,如下: $( ...
- python爬虫06 | 你的第一个爬虫,爬取当当网 Top 500 本五星好评书籍
来啦,老弟 我们已经知道怎么使用 Requests 进行各种请求骚操作 也知道了对服务器返回的数据如何使用 正则表达式 来过滤我们想要的内容 ... 那么接下来 我们就使用 requests 和 re ...
- 使用python爬取东方财富网机构调研数据
最近有一个需求,需要爬取东方财富网的机构调研数据.数据所在的网页地址为: 机构调研 网页如下所示: 可见数据共有8464页,此处不能直接使用scrapy爬虫进行爬取,因为点击下一页时,浏览器只是发起了 ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- 爬虫入门(四)——Scrapy框架入门:使用Scrapy框架爬取全书网小说数据
为了入门scrapy框架,昨天写了一个爬取静态小说网站的小程序 下面我们尝试爬取全书网中网游动漫类小说的书籍信息. 一.准备阶段 明确一下爬虫页面分析的思路: 对于书籍列表页:我们需要知道打开单本书籍 ...
- [转]使用python爬取东方财富网机构调研数据
最近有一个需求,需要爬取东方财富网的机构调研数据.数据所在的网页地址为: 机构调研 网页如下所示: 可见数据共有8464页,此处不能直接使用scrapy爬虫进行爬取,因为点击下一页时,浏览器只是发起了 ...
- Python爬虫项目--爬取自如网房源信息
本次爬取自如网房源信息所用到的知识点: 1. requests get请求 2. lxml解析html 3. Xpath 4. MongoDB存储 正文 1.分析目标站点 1. url: http:/ ...
- GoLang爬取花瓣网美女图片
由于之前一直想爬取花瓣网(http://huaban.com/partner/uc/aimeinv/pins/) 的图片,又迫于没时间,所以拖了很久. 鉴于最近在学go语言,就刚好用这个练手了. 预览 ...
随机推荐
- Winform中对ZedGraph的RadioGroup进行数据源绑定,即通过代码添加选项
场景 在寻找设置RadioGroup的选项时没有找到相关博客,在DevExpress的官网找到 怎样给其添加选项. DevExpress官网教程: https://documentation.deve ...
- 阿里云Centos 7安装MongoDB 4.2.0
背景:最近公司项目需要将后台接口优化到100ms内.因此需要对接口逻辑,数据优化做处理, 正好使用到了Redis缓存,mysql,mongoDB的优化,今天记录一下在阿里云centos上安装mongo ...
- AppScan工具介绍与安装
本文仅供个人参考学习,如做商业用途,请购买正版,谢谢! 介绍 AppScan是IBM公司出的一款Web应用安全测试工具,采用黑盒测试的方式,可以扫描常见的web应用安全漏洞.其工作原理,首先是根据起始 ...
- 【linux】【docker】docker私服安装
前言 系统环境:Centos7.jdk1.8 docker私服:可以把项目通过dockerfile文件build成docker镜像,供其他环境拉取.部署在本地,私有化. 安装 dockerHUB私服 ...
- Redis数据库安装与配置调试
主要培养自我对Redis数据库安装能力, 并且进行个性化的数据库配置.掌握本实验的重点,即在于数据库的安装与启动参数的配置.同时,理解NOSQL数据库的体系结构. ①下载Redis安装包进行数据库平台 ...
- Player的跟踪狂 -- Camera
P.S.很多游戏里的Player都会设置的被跟踪,是人性的扭曲,还是XXX,正在解密. 第三人称视角 camera紧跟player背后(角度随player改变) using System.Collec ...
- FILETIME类型到LARGE_INTEGER类型的转换
核心编程第5版 245页到247页的讲到SetWaitableTimer函数的使用 其中提到 FILETIME类型到LARGE_INTEGER类型的转换问题,如下代码 //我们声明的局部变量 HAND ...
- mybatis <=或这个>=提示错误Tag name expecte问题解决
解决方案: 1.将<号或者>号进行转义 DATE_SUB(CURDATE(), INTERVAL 31 DAY) <= DATE(created) 2.使用<![CDATA[ ...
- Java静态代理&动态代理&Cglib代理详解
一.静态代理 根据被代理的类的时机的不同,如果在编译阶段就能确定下来的被代理的类是哪一个,那么,就可以使用静态代理的方式. 申明一个接口: /** * @author jiaqing.xu@hand- ...
- java通过代理创建Conncection对象与自定义JDBC连接池
最近学习了一下代理发现,代理其实一个蛮有用的,主要是用在动态的实现接口中的某一个方法而不去继承这个接口所用的一种技巧,首先是自定义的一个连接池 代码如下 import java.lang.reflec ...