MongoDB for OPS 04:备份恢复
写在前面的话
和 MySQL 一样,mongodb 也是需要将数据进行备份的,毕竟天有不测风云,谁也不知道哪天机器就炸了。
备份恢复
mongodb 提供了两种备份恢复手段:mongoexport / mongoimport 和 mongodump / mongorestore
先看看应用场景:
mongoexport / mongoimport 导出的数据为 json / csv 文本。这意味着我们可以将 MySQL 中的数据按照一定的规律导出然后导入到 mongodb 中。
同时,它适用于跨大版本的版本升级这样的情景。
mongodump / mongorestore 则和 mysqldump 有点像,一般用于日常的备份恢复。
这里以一个单节点的 mongodb 为例:
mkdir /data/backup/mongodb-demo
mongo --port 27000
创建用户并增加验证:
use admin
db.createUser({user: "root",pwd: "",roles: [{role:"root",db:"admin"}]})
配置文件添加验证配置:
# 安全验证有关配置
security:
# 是否打开用户名密码验证
authorization: enabled
重启 mongodb 登录:
mongo -uroot -p123456 --port 27000
初始化数据库:
use hello
for(i=0;i<10000;i++){db.t1.insert({"uid":i,"name":"mongo","date":new Date()})} use world
for(i=0;i<10000;i++){db.t1.insert({"uid":i,"name":"zhangsan","date":new Date()})}
mongoexport:
1. 备份指定库下面指定表到 json 文件:
mongoexport -uroot -p123456 --port 27000 --authenticationDatabase admin -d hello -c t1 -o /data/backup/mongodb-demo/hello-t1.json
参数说明:
-u:用户名
-p:密码
--port:端口
--authenticationDatabase:认证数据库
-d:指定数据库
-c:指定表
-f:指定要导出的列
-o:指定到要导出到哪个文件
-q:指明导出数据的过滤条件
此时可以查看:
cat /data/backup/mongodb-demo/hello-t1.json
结果如图:

2. 单表备份到 csv 文件中:
mongoexport -uroot -p123456 --port 27000 --authenticationDatabase admin -d hello -c t1 --type csv -f uid,name,date -o /data/backup/mongodb-demo/hello-t1.csv
新增了--type 指明导出类型,-f 指明要导出的字段,导出后使用 excel 打开:

mongoimport:
1. 恢复 json 文件到 hello 下面 t3:
mongoimport -uroot -p123456 --port 27000 --authenticationDatabase admin -d hello -c t3 /data/backup/mongodb-demo/hello-t1.json
结果如图:

2. 恢复 csv 文件到 hello 下面的 t4:
mongoimport -uroot -p123456 --port 27000 --authenticationDatabase admin -d hello -c t4 --type csv --headerline --file /data/backup/mongodb-demo/hello-t1.csv
注意,由于导出的 csv 包含了标题栏,所以需要 --headerline 说明。同时通过 --file 指定文件。
当 csv 文件中不包含第一行标题的时候,则需要使用 -f 手动指定标题。

由于 csv 和 json 文件是我们明确可以知道它的格式是怎样的,所以可以将其它数据库的数据按照这个格式导出,然后导入我们的 mongodb。
如 MySQL 导出:
select * from city into outfile '/tmp/city.csv' fields terminated by ',';
我们这样就能将查询的数据导出到 csv 文件,而且由于 mongodb 的 csv 文件时以逗号分隔,所以需要指定一下。
mongodump:
1. 全库备份:
mongodump -uroot -p123456 --port 27000 --authenticationDatabase admin -o /data/backup/mongodb-demo/all-backup
结果如图:
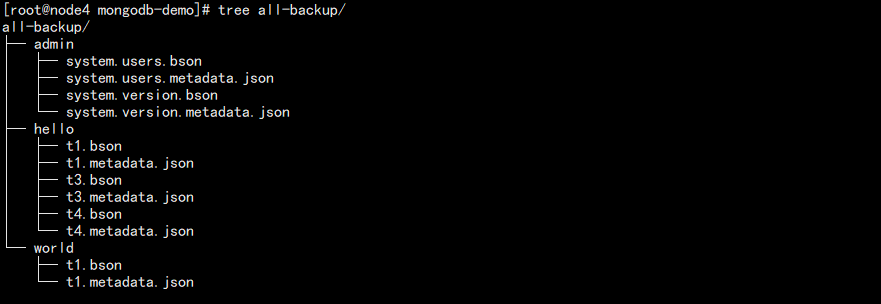
可以看到,其实就是将所有的库导出成 json 和 bson 的形式。
2. 备份 hello 库:
mongodump -uroot -p123456 --port 27000 --authenticationDatabase admin -d hello -o /data/backup/mongodb-demo/hello
3. 备份指定表:
mongodump -uroot -p123456 --port 27000 --authenticationDatabase admin -d hello -c t1 -o /data/backup/mongodb-demo/hello-t1
4. 压缩备份:
mongodump -uroot -p123456 --port 27000 --authenticationDatabase admin -o /data/backup/mongodb-demo/all-zip --gzip
结果如图:
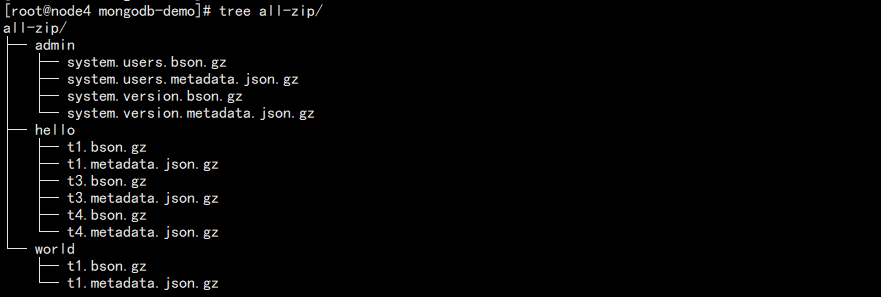
mongorestore:
1. 恢复 hello 库:
mongorestore -uroot -p123456 --port 27000 --authenticationDatabase admin -d hello /data/backup/mongodb-demo/hello/hello
注意目录层级,且恢复只能是该库不存在的情况下!
2. 同理,恢复单独的表只需要 -c 指定,恢复压缩则需要使用 --gzip 说明。
3. 注意:当我们恢复的时候,库或者表存在是无法写入的,所有我们需要先删除它。此时只需要加入 --drop 就会自动先删除再恢复。但是很危险!!!
oplog
在 MySQL 中有 binlog 能够保证我们在故障之后最大可能性的恢复数据,当然,在 mongodb 也同样有这种类似的东西,这就是 oplog。
但是注意,oplog 只能在 rs 复制集或者主从模式中使用。
oplog 默认占用磁盘为磁盘总大小的 5%,所以在配置文件中我们使用了 oplogSizeMB 来规定日志文件大小。
当达到指定大小时,新的日志会覆盖旧的日志。
我们准备了一个 rs 集群:192.168.200.104:27001 - 27003
查看当前的 oplog:
use local
show collections
db.oplog.rs.find().pretty()
内容如下:

在 oplog 中,默认包含多种操作类型:
i:insert
u:update
d:delete
c:db command(对数据库的操作)
同时,我们在配置配置文件的时间,增加了 oplogSizeMB,但是当时我们是直接给的大小,不一定合适自己的系统。
该大小的设计规则肯定是越接近 MySQL 那样每次备份那一刻开始重新记录这样是最好的。
所以,对于 mongodb,我们只能通过:
rs.printReplicationInfo()
结果如图:

通过这样的预估来判断我们这个 log 能够坚持写多久。这里因为我刚刚生成了 1万数据,所以预估只能写 0.18 小时。
在我们备份的时候,可以通过相关的参数来记录备份过程中的数据变更,并将他另外保存为 oplog.bson 中。
mongodump --port 27001 --oplog -o /data/backup/mongodb
查看:

此时恢复则需要加入另外的参数:--oplogReplay
mongorestore --port=27001 --oplogReplay /data/backup/mongodb
当然,我这里数据以及存在,mongodb 会自己校验数据是否存在而选择是否执行。
模拟删库故障
注意事项:
1. 在生产中,恢复应该在新机器上面执行,避免因为恢复失败造成数据永久性顺坏。
2. 恢复应该停掉其它应用,避免新数据写入。
具体操作:
1. 先执行一次备份模拟晚上的全备:
mongodump --port 27001 --oplog -o /data/backup/mongodb
2. 新增操作:
use hello
db.t2.insert({name:"zhangsan"})
db.t3.insert({name:"lisi"})
db.t3.insert({name:"wangwu"}) # 删表
db.t1.drop()
3. 备份 local 库的 oplog.rs 表:
mongodump --port 27001 -d local -c oplog.rs -o /data/backup/local
4. 登录库查看删除的时间戳:
db.oplog.rs.find({op:"c"}).pretty()
结果如图:
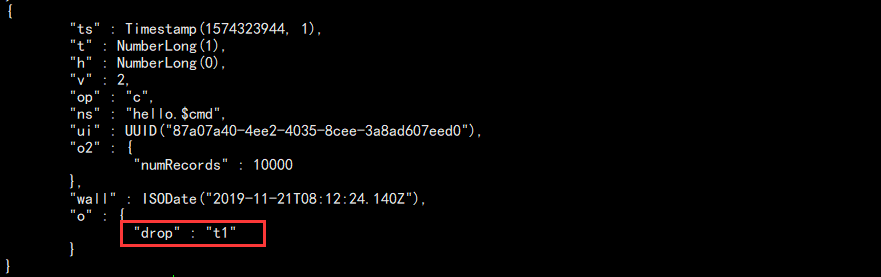
最后一个就是 drop 操作,我们记录它的 ts 为:1574323944, 1
5. 将 local 备份下的 oplog.rs.bson 拷贝到之前全备下面,替换掉 oplog.bson
cp oplog.rs.bson /data/backup/mongodb/oplog.bson
6. 执行恢复:
mongorestore --port 27001 --oplogReplay --oplogLimit "1574323944:1" --drop /data/backup/mongodb/
注意,这里时间戳需要和后面的操作使用冒号隔开。而不是默认的逗号。
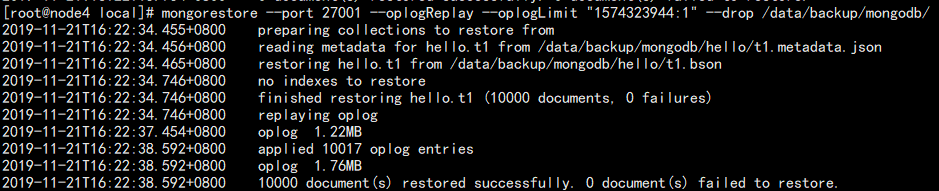
7. 查看恢复结果:

最后,关于分片集群的备份其实是一个很复杂的过程,需要另外进行好好规划。
当然,官方的 Ops manager 非常牛逼,但是不免费。
MongoDB for OPS 04:备份恢复的更多相关文章
- mongodb的副本集|备份|恢复备份
复制(副本集) 什么是复制 复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性,并可以保证数据的安全性 复制还允许从硬件故障和服务中断中恢复数据 为什么要复制 数据备份 数据灾 ...
- mongodb 的备份恢复导入与导出
导入导出 use hndb; db.s.save({name:'李四',age:18,score:80,address:'郑州'}); db.s.save({name:'李三',age:8,score ...
- MongoDB学习(三)数据导入导出及备份恢复
这几天想着公司要用MongoDB,自然就要用到数据导入导出,就自己学习了一下. 在Mongo学习(二)中就讲到了在bin目录下有一些工具,本篇就是使用这些工具进行数据的导入导出及备份恢复. 注意:以下 ...
- mongodb数据库备份恢复
MongoDB数据文件备份与恢复 备份与恢复数据对于管理任何数据存储系统来说都是非常重要的. 1.冷备份与恢复——创建数据文件的副本(前提是要停止MongoDB服务器),也就是直接copy ...
- Mongodb数据备份恢复
Mongodb数据备份恢复 一.MongoDB数据库导入导出操作 1.导出数据库 twangback为备份的文件夹 命令: mongodump -h 127.0.0.1[服务器IP] -d advie ...
- mongodb集群配置及备份恢复
Mongodb安装: 编辑/etc/yum.repos.d/mongodb.repo,添加以下: [MongoDB] name=MongoDB Repository baseurl=https://r ...
- MongoDB学习笔记(三)--权限 && 导出导入备份恢复 && fsync和锁
权限 绑定内网I ...
- mongodb数据库备份恢复-windows系统
备份语法: mongodump命令脚本语法如下: >mongodump -h dbhost -d dbname -o dbdirectory -h: MongDB所在服务器地址,例如:127.0 ...
- 010.MongoDB备份恢复
一 MongoDB备份 1.1 备份概述 mongodb数据备份和还原主要分为二种,一种是针对于库的mongodump和mongorestore,一种是针对库中表的mongoexport和mongoi ...
随机推荐
- git版本对比
1.git diff版本比对 (未添加到暂存区间之前的区别对比) 未进行修改,则显示为空 进行文件修改,再执行git diff 当执行git add . 之后,再次git diff则为空 缓存和提交 ...
- <挑战程序设计竞赛> poj 3320 Jessica's Reading Problem 双指针
地址 http://poj.org/problem?id=3320 解答 使用双指针 在指针范围内是否达到要求 若不足要求则从右进行拓展 若满足要求则从左缩减区域 代码如下 正确性调整了几次 然后 ...
- 【转载】algorithm、numeric、functional
reference url:http://www.cplusplus.com/reference/algorithm reference url:https://blog.csdn.net/Swust ...
- 解决“var/log/sysstat/sa21: 没有那个文件或目录 请检查是否允许数据收集”
想使用sar查看一些系统的一些活动信息,发现报错.记录一下 使用apt install sysstat后第一次 报错 /var/log/sysstat/sa21: 没有那个文件或目录 请检查是否允许数 ...
- SpringCloud微服务(02):Ribbon和Feign组件,实现服务调用的负载均衡
本文源码:GitHub·点这里 || GitEE·点这里 一.Ribbon简介 1.基本概念 Ribbon是一个客户端的负载均衡(Load Balancer,简称LB)器,它提供对大量的HTTP和TC ...
- NetCore的Docker部署
NetCore的Docker部署 一.NetCore与Docker Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Linux或 ...
- 数据结构javascript实现
电脑配置 CPU:AMD X4 640 内存: 宏想 DDR3 1600MHz 8g 主板:华擎 980DE3/U3S3 R2.0 浏览器:chrome 79.0.3945.88(正式版本) (64 ...
- git clone克隆项目太慢,或者直接导致克不下来的解决办法(转载请注明出处)
从github下载项目下来,由于项目提交历史过多等各种原因导致文件太大,clone的时候非常的慢,或者直接出现 error: RPC failed; curl 18 transfer closed w ...
- 微信两种签名算法MD5和HMAC-SHA256
在做微信接口开发的过程中, 有时候发现会提示签名校验失败, 一模一样的签名逻辑就是有些接口跑步通, 找了一圈发现挺坑的; 原来是有些接口的signType签名类型有区别, 有些接口signType要求 ...
- linux学习(七)Shell编程中的变量
目录 shell编程的建立 shell的hello world! Shell的环境变量 使用和设置环境变量 Shell的系统变量 用户自定义变量 @(Shell编程) shell编程的建立 [root ...