【新手必学】Python爬虫之多线程实战

1.先附上没有用多线程的包图网爬虫的代码
import requests
from lxml import etree
import os
import time start_time = time.time()#记录开始时间
for i in range(1,7):
#1.请求包图网拿到整体数据
response = requests.get("https://ibaotu.com/shipin/7-0-0-0-0-%s.html" %str(i)) #2.抽取 视频标题、视频链接
html = etree.HTML(response.text)
tit_list = html.xpath('//span[@class="video-title"]/text()')#获取视频标题
src_list = html.xpath('//div[@class="video-play"]/video/@src')#获取视频链接
for tit,src in zip(tit_list,src_list):
#3.下载视频
response = requests.get("http:" + src)
#给视频链接头加上http头,http快但是不一定安全,https安全但是慢 #4.保存视频
if os.path.exists("video1") == False:#判断是否有video这个文件夹
os.mkdir("video1")#没有的话创建video文件夹
fileName = "video1\\" + tit + ".mp4"#保存在video文件夹下,用自己的标题命名,文件格式是mp4
#有特殊字符的话需要用\来注释它,\是特殊字符所以这里要用2个\\
print("正在保存视频文件: " +fileName)#打印出来正在保存哪个文件
with open (fileName,"wb") as f:#将视频写入fileName命名的文件中
f.write(response.content)end_time = time.time()#记录结束时间
print("耗时%d秒"%(end_time-start_time))#输出用了多少时间
2.将上述代码套用多线程,先创建多线程
data_list = []#设置一个全局变量的列表
# 创建多线程
class MyThread(threading.Thread):
def __init__(self, q):
threading.Thread.__init__(self)
self.q = q
#调用get_index()
def run(self) -> None:
self.get_index()
#拿到网址后获取所需要的数据并存入全局变量data_list中
def get_index(self):
url = self.q.get()
try:
resp = requests.get(url)# 访问网址
# 将返回的数据转成lxml格式,之后使用xpath进行抓取
html = etree.HTML(resp.content)
tit_list = html.xpath('//span[@class="video-title"]/text()') # 获取视频标题
src_list = html.xpath('//div[@class="video-play"]/video/@src') # 获取视频链接
for tit, src in zip(tit_list, src_list):
data_dict = {}#设置一个存放数据的字典
data_dict['title'] = tit#往字典里添加视频标题
data_dict['src'] = src#往字典里添加视频链接
# print(data_dict)
data_list.append(data_dict)#将这个字典添加到全局变量的列表中
except Exception as e:
# 如果访问超时就打印错误信息,并将该条url放入队列,防止出错的url没有爬取
self.q.put(url)
print(e)3.用队列queue,queue模块主要是多线程,保证线程安全使用的
def main():
# 创建队列存储url
q = queue.Queue()
for i in range(1,6):
# 将url的参数进行编码后拼接到url
url = 'https://ibaotu.com/shipin/7-0-0-0-0-%s.html'%str(i)
# 将拼接好的url放入队列中
q.put(url)
# 如果队列不为空,就继续爬
while not q.empty():
# 创建3个线程
ts = []
for count in range(1,4):
t = MyThread(q)
ts.append(t)
for t in ts:
t.start()
for t in ts:
t.join()
4.创建存储方法,如果你学习遇到问题找不到人解答,可以点我进裙,里面大佬解决问题及Python教.程下载和一群上进的人一起交流!
#提取data_list的数据并保存
def save_index(data_list):
if data_list:
for i in data_list:
# 下载视频
response = requests.get("http:" + i['src'])
# 给视频链接头加上http头,http快但是不安全,https安全但是慢
# 保存视频
if os.path.exists("video") == False: # 判断是否有video这个文件夹
os.mkdir("video") # 没有的话创建video文件夹
fileName = "video\\" + i['title'] + ".mp4" # 保存在video文件夹下,用自己的标题命名,文件格式是mp4
# 有特殊字符的话需要用\来注释它,\是特殊字符所以这里要用2个\\
print("正在保存视频文件: " + fileName) # 打印出来正在保存哪个文件
with open(fileName, "wb") as f: # 将视频写入fileName命名的文件中
f.write(response.content)5.最后就是调用函数了
if __name__ == '__main__':
start_time = time.time()
# 启动爬虫
main()
save_index(data_list)
end_time = time.time()
print("耗时%d"%(end_time-start_time))6.附上完整的多线程代码
import requests
from lxml import etree
import os
import queue
import threading
import time
data_list = []#设置一个全局变量的列表
# 创建多线程
class MyThread(threading.Thread):
def __init__(self, q):
threading.Thread.__init__(self)
self.q = q
#调用get_index()
def run(self) -> None:
self.get_index()
#拿到网址后获取所需要的数据并存入全局变量data_list中
def get_index(self):
url = self.q.get()
try:
resp = requests.get(url)# 访问网址
# 将返回的数据转成lxml格式,之后使用xpath进行抓取
html = etree.HTML(resp.content)
tit_list = html.xpath('//span[@class="video-title"]/text()') # 获取视频标题
src_list = html.xpath('//div[@class="video-play"]/video/@src') # 获取视频链接
for tit, src in zip(tit_list, src_list):
data_dict = {}#设置一个存放数据的字典
data_dict['title'] = tit#往字典里添加视频标题
data_dict['src'] = src#往字典里添加视频链接
# print(data_dict)
data_list.append(data_dict)#将这个字典添加到全局变量的列表中
except Exception as e:
# 如果访问超时就打印错误信息,并将该条url放入队列,防止出错的url没有爬取
self.q.put(url)
print(e)
def main():
# 创建队列存储url
q = queue.Queue()
for i in range(1,7):
# 将url的参数进行编码后拼接到url
url = 'https://ibaotu.com/shipin/7-0-0-0-0-%s.html'%str(i)
# 将拼接好的url放入队列中
q.put(url)
# 如果队列不为空,就继续爬
while not q.empty():
# 创建3个线程
ts = []
for count in range(1,4):
t = MyThread(q)
ts.append(t)
for t in ts:
t.start()
for t in ts:
t.join()
#提取data_list的数据并保存
def save_index(data_list):
if data_list:
for i in data_list:
# 下载视频
response = requests.get("http:" + i['src'])
# 给视频链接头加上http头,http快但是不安全,https安全但是慢
# 保存视频
if os.path.exists("video") == False: # 判断是否有video这个文件夹
os.mkdir("video") # 没有的话创建video文件夹
fileName = "video\\" + i['title'] + ".mp4" # 保存在video文件夹下,用自己的标题命名,文件格式是mp4
# 有特殊字符的话需要用\来注释它,\是特殊字符所以这里要用2个\\
print("正在保存视频文件: " + fileName) # 打印出来正在保存哪个文件
with open(fileName, "wb") as f: # 将视频写入fileName命名的文件中
f.write(response.content)
if __name__ == '__main__':
start_time = time.time()
# 启动爬虫
main()
save_index(data_list)
end_time = time.time()
print("耗时%d"%(end_time-start_time))
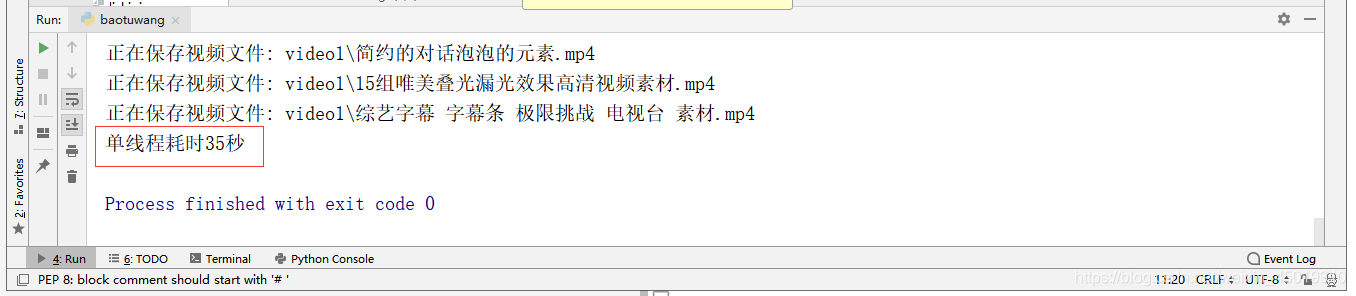
7.这2个爬虫我都设置了开始时间和结束时间,可以用(结束时间-开始时间)来计算比较两者的效率。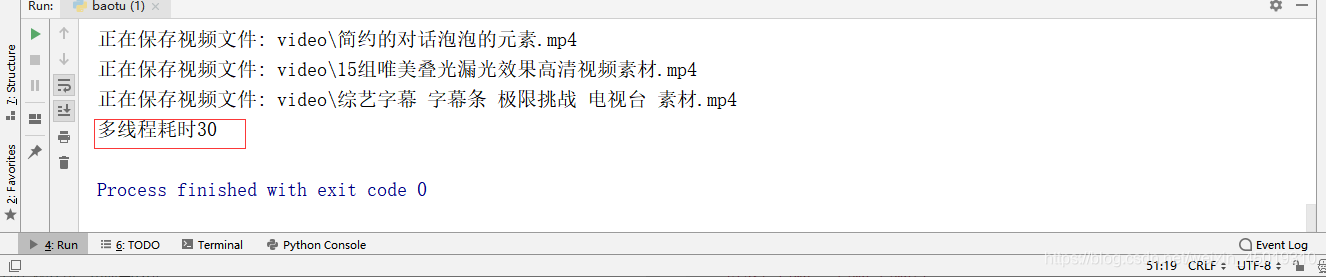
【新手必学】Python爬虫之多线程实战的更多相关文章
- Python爬虫工程师必学——App数据抓取实战 ✌✌
Python爬虫工程师必学——App数据抓取实战 (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 爬虫分为几大方向,WEB网页数据抓取.APP数据抓取.软件系统 ...
- Python爬虫工程师必学APP数据抓取实战✍✍✍
Python爬虫工程师必学APP数据抓取实战 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身没问题,大 ...
- Python爬虫工程师必学——App数据抓取实战
Python爬虫工程师必学 App数据抓取实战 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身没问题,大 ...
- 小白学 Python 爬虫(16):urllib 实战之爬取妹子图
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(40):爬虫框架 Scrapy 入门基础(七)对接 Selenium 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(41):爬虫框架 Scrapy 入门基础(八)对接 Splash 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(23):解析库 pyquery 入门
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(4):前置准备(三)Docker基础入门
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(11):urllib 基础使用(一)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- 正则表达式 解决python2升python3的语法问题
2019.9.12 更新 今天偶然看到 python 官网中,还介绍了一个专门的工具,用于 python2 升级 python3,以后有机会使用下看看 https://docs.python. ...
- cocos creator 3D | 蚂蚁庄园运动会星星球
上一篇文章写了一个简易版的蚂蚁庄园登山赛,有小伙伴留言说想要看星星球的,那么就写起来吧! 效果预览 配置环境 cocos creator 3d 1.0.0 小球点击 3d里节点无法用 cc.Node. ...
- linux运维与实践
1.容器云计算节点负载值高,通过top可以看到Load Average:70.1 71.3 70.8,虚拟机有8个cpu: cpu使用率高导致(R状态)? 同时在top中观察一段时间,消耗cpu最 ...
- Promise.all()
Promise.all(iterable) 方法返回一个 Promise 实例,此实例在 iterable 参数内所有的 promise 都“完成(resolved)”或参数中不包含 promise ...
- 一个HTML5培训班毕业生的找工作随笔
昨天刚参加完一个面试,通过了.写个随笔记录一下. 先介绍一下背景. 我是今年十月份的时候从某个培训机构的HTML5 Web前端培训班毕业的,是一个刚进入IT行业的新人. 本人毕业于某三流学校,在参加培 ...
- at、crontab、anacron的基本使用
Linux的任务调度机制主要分为两种: 1. 执行一次:将在某个特定的时间执行的任务调度 at 2. 执行多次: crontab 3.关机后恢复尚未执行的程序 anacron. ①at at命令用于在 ...
- Android Studio 2.2 NDK开发环境搭建
转载请标明出处:http://blog.csdn.net/shensky711/article/details/52763192 本文出自: [HansChen的博客] Android应用程序使用ND ...
- kube-nginx 和 keepalived 部署安装
目录 简介 nginx 安装配置 下载编译nginx 配置Nginx文件,开启4层透明转发 配置Nginx启动文件 keepalived 安装配置 安装keeplive服务 配置keeplive服务 ...
- HTML表格中各元素之间属性之间的相互影响
开发了一个动态表格制作程序,用的是谷歌浏览器.发现几个现象,记录如下: 1.按照技术文档的说法,正规的表格样式如下: <table> <caption>标题</capti ...
- 原生js删除增加修改class属性
其实html5已经扩展了class操作的相关API,其中classList属性就以及实现了class的增删和判断. HTML DOM classList 属性 classList属性的方法有: add ...