[深度应用]·DC竞赛轴承故障检测开源Baseline(基于Keras 1D卷积 val_acc:0.99780)
[深度应用]·DC竞赛轴承故障检测开源Baseline(基于Keras1D卷积 val_acc:0.99780)
个人网站--> http://www.yansongsong.cn/
Github项目地址--> https://github.com/xiaosongshine/bearing_detection_by_conv1d
大赛简介
轴承是在机械设备中具有广泛应用的关键部件之一。由于过载,疲劳,磨损,腐蚀等原因,轴承在机器操作过程中容易损坏。事实上,超过50%的旋转机器故障与轴承故障有关。实际上,滚动轴承故障可能导致设备剧烈摇晃,设备停机,停止生产,甚至造成人员伤亡。一般来说,早期的轴承弱故障是复杂的,难以检测。因此,轴承状态的监测和分析非常重要,它可以发现轴承的早期弱故障,防止故障造成损失。 最近,轴承的故障检测和诊断一直备受关注。在所有类型的轴承故障诊断方法中,振动信号分析是最主要和有用的工具之一。 在这次比赛中,我们提供一个真实的轴承振动信号数据集,选手需要使用机器学习技术判断轴承的工作状态。
数据介绍
轴承有3种故障:外圈故障,内圈故障,滚珠故障,外加正常的工作状态。如表1所示,结合轴承的3种直径(直径1,直径2,直径3),轴承的工作状态有10类:
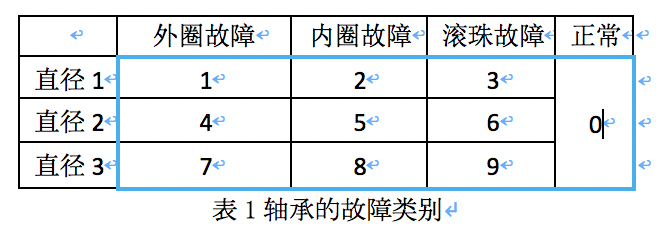

参赛选手需要设计模型根据轴承运行中的振动信号对轴承的工作状态进行分类。
1.train.csv,训练集数据,1到6000为按时间序列连续采样的振动信号数值,每行数据是一个样本,共792条数据,第一列id字段为样本编号,最后一列label字段为标签数据,即轴承的工作状态,用数字0到9表示。
2.test_data.csv,测试集数据,共528条数据,除无label字段外,其他字段同训练集。 总的来说,每行数据除去id和label后是轴承一段时间的振动信号数据,选手需要用这些振动信号去判定轴承的工作状态label。
注意:同一列的数据不一定是同一个时间点的采样数据,即不要把每一列当作一个特征
*数据下载具体操作:
ps:注册登陆后方可下载
评分标准
评分算法
binary-classification
采用各个品类F1指标的算术平均值,它是Precision 和 Recall 的调和平均数。
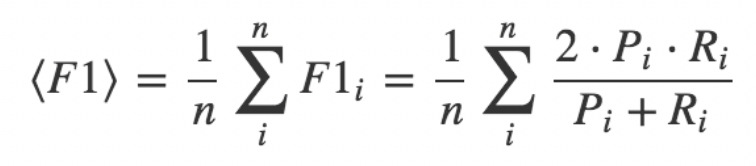
其中,Pi是表示第i个种类对应的Precision, Ri是表示第i个种类对应Recall。
赛题分析
简单分析一下,这个比赛大家可以简单的理解为一个10分类的问题,输入的形状为(-1,6000),网络输出的结果为(-1,10)(此处采用onehot形式)
赛题就是一个十分类预测问题,解题思路应该包括以下内容
- 数据读取与处理
- 网络模型搭建
- 模型的训练
- 模型应用与提交预测结果
实战应用
经过对赛题的分析,我们把任务分成四个小任务,首先第一步是:
1.数据读取与处理
数据是CSV文件,1到6000为按时间序列连续采样的振动信号数值,每行数据是一个样本,共792条数据,第一列id字段为样本编号,最后一列label字段为标签数据,即轴承的工作状态,用数字0到9表示。
数据处理函数定义:
import keras
from scipy.io import loadmat
import matplotlib.pyplot as plt
import glob
import numpy as np
import pandas as pd
import math
import os
from keras.layers import *
from keras.models import *
from keras.optimizers import *
import numpy as np
MANIFEST_DIR = "Bear_data/train.csv"
Batch_size = 20
Long = 792
Lens = 640
#把标签转成oneHot
def convert2oneHot(index,Lens):
hot = np.zeros((Lens,))
hot[int(index)] = 1
return(hot)
def xs_gen(path=MANIFEST_DIR,batch_size = Batch_size,train=True,Lens=Lens):
img_list = pd.read_csv(path)
if train:
img_list = np.array(img_list)[:Lens]
print("Found %s train items."%len(img_list))
print("list 1 is",img_list[0,-1])
steps = math.ceil(len(img_list) / batch_size) # 确定每轮有多少个batch
else:
img_list = np.array(img_list)[Lens:]
print("Found %s test items."%len(img_list))
print("list 1 is",img_list[0,-1])
steps = math.ceil(len(img_list) / batch_size) # 确定每轮有多少个batch
while True:
for i in range(steps):
batch_list = img_list[i * batch_size : i * batch_size + batch_size]
np.random.shuffle(batch_list)
batch_x = np.array([file for file in batch_list[:,1:-1]])
batch_y = np.array([convert2oneHot(label,10) for label in batch_list[:,-1]])
yield batch_x, batch_y
TEST_MANIFEST_DIR = "Bear_data/test_data.csv"
def ts_gen(path=TEST_MANIFEST_DIR,batch_size = Batch_size):
img_list = pd.read_csv(path)
img_list = np.array(img_list)[:Lens]
print("Found %s train items."%len(img_list))
print("list 1 is",img_list[0,-1])
steps = math.ceil(len(img_list) / batch_size) # 确定每轮有多少个batch
while True:
for i in range(steps):
batch_list = img_list[i * batch_size : i * batch_size + batch_size]
#np.random.shuffle(batch_list)
batch_x = np.array([file for file in batch_list[:,1:]])
#batch_y = np.array([convert2oneHot(label,10) for label in batch_list[:,-1]])
yield batch_x
读取一条数据进行显示
if __name__ == "__main__":
if Show_one == True:
show_iter = xs_gen()
for x,y in show_iter:
x1 = x[0]
y1 = y[0]
break
print(y)
print(x1.shape)
plt.plot(x1)
plt.show()
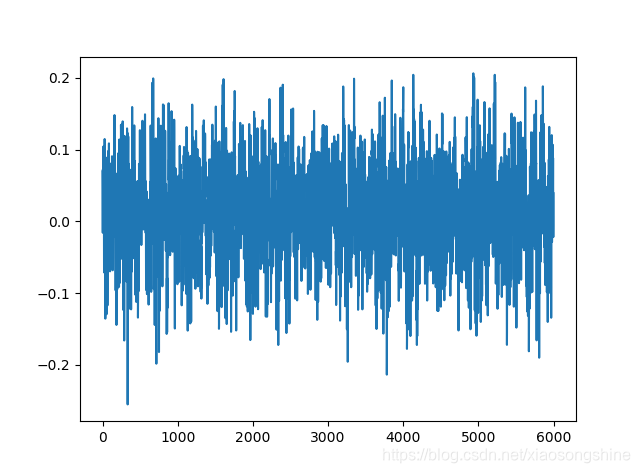
我们由上述信息可以看出每种导联都是由6000个点组成的列表,大家可以理解为mnist展开为一维后的形状
标签处理方式
def create_csv(TXT_DIR=TXT_DIR):
lists = pd.read_csv(TXT_DIR,sep=r"\t",header=None)
lists = lists.sample(frac=1)
lists.to_csv(MANIFEST_DIR,index=None)
print("Finish save csv")
数据读取的方式我采用的是生成器的方式,这样可以按batch读取,加快训练速度,大家也可以采用一下全部读取,看个人的习惯了。关于生成器介绍,大家可以参考我的这篇博文
[开发技巧]·深度学习使用生成器加速数据读取与训练简明教程(TensorFlow,pytorch,keras)
2.网络模型搭建
数据我们处理好了,后面就是模型的搭建了,我使用keras搭建的,操作简单便捷,tf,pytorch,sklearn大家可以按照自己喜好来。
网络模型可以选择CNN,RNN,Attention结构,或者多模型的融合,抛砖引玉,此Baseline采用的一维CNN方式,一维CNN学习地址
模型搭建
TIME_PERIODS = 6000
def build_model(input_shape=(TIME_PERIODS,),num_classes=10):
model = Sequential()
model.add(Reshape((TIME_PERIODS, 1), input_shape=input_shape))
model.add(Conv1D(16, 8,strides=2, activation='relu',input_shape=(TIME_PERIODS,1)))
model.add(Conv1D(16, 8,strides=2, activation='relu',padding="same"))
model.add(MaxPooling1D(2))
model.add(Conv1D(64, 4,strides=2, activation='relu',padding="same"))
model.add(Conv1D(64, 4,strides=2, activation='relu',padding="same"))
model.add(MaxPooling1D(2))
model.add(Conv1D(256, 4,strides=2, activation='relu',padding="same"))
model.add(Conv1D(256, 4,strides=2, activation='relu',padding="same"))
model.add(MaxPooling1D(2))
model.add(Conv1D(512, 2,strides=1, activation='relu',padding="same"))
model.add(Conv1D(512, 2,strides=1, activation='relu',padding="same"))
model.add(MaxPooling1D(2))
model.add(GlobalAveragePooling1D())
model.add(Dropout(0.3))
model.add(Dense(num_classes, activation='softmax'))
return(model)
用model.summary()输出的网络模型为
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
reshape_1 (Reshape) (None, 6000, 1) 0
_________________________________________________________________
conv1d_1 (Conv1D) (None, 2997, 16) 144
_________________________________________________________________
conv1d_2 (Conv1D) (None, 1499, 16) 2064
_________________________________________________________________
max_pooling1d_1 (MaxPooling1 (None, 749, 16) 0
_________________________________________________________________
conv1d_3 (Conv1D) (None, 375, 64) 4160
_________________________________________________________________
conv1d_4 (Conv1D) (None, 188, 64) 16448
_________________________________________________________________
max_pooling1d_2 (MaxPooling1 (None, 94, 64) 0
_________________________________________________________________
conv1d_5 (Conv1D) (None, 47, 256) 65792
_________________________________________________________________
conv1d_6 (Conv1D) (None, 24, 256) 262400
_________________________________________________________________
max_pooling1d_3 (MaxPooling1 (None, 12, 256) 0
_________________________________________________________________
conv1d_7 (Conv1D) (None, 12, 512) 262656
_________________________________________________________________
conv1d_8 (Conv1D) (None, 12, 512) 524800
_________________________________________________________________
max_pooling1d_4 (MaxPooling1 (None, 6, 512) 0
_________________________________________________________________
global_average_pooling1d_1 ( (None, 512) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 512) 0
_________________________________________________________________
dense_1 (Dense) (None, 10) 5130
=================================================================
Total params: 1,143,594
Trainable params: 1,143,594
Non-trainable params: 0
_________________________________________________________________
None
训练参数比较少,大家可以根据自己想法更改。
3.网络模型训练
模型训练
Show_one = True
Train = True
if __name__ == "__main__":
if Show_one == True:
show_iter = xs_gen()
for x,y in show_iter:
x1 = x[0]
y1 = y[0]
break
print(y)
print(x1.shape)
plt.plot(x1)
plt.show()
if Train == True:
train_iter = xs_gen()
val_iter = xs_gen(train=False)
ckpt = keras.callbacks.ModelCheckpoint(
filepath='best_model.{epoch:02d}-{val_loss:.4f}.h5',
monitor='val_loss', save_best_only=True,verbose=1)
model = build_model()
opt = Adam(0.0002)
model.compile(loss='categorical_crossentropy',
optimizer=opt, metrics=['accuracy'])
print(model.summary())
model.fit_generator(
generator=train_iter,
steps_per_epoch=Lens//Batch_size,
epochs=50,
initial_epoch=0,
validation_data = val_iter,
nb_val_samples = (Long - Lens)//Batch_size,
callbacks=[ckpt],
)
model.save("finishModel.h5")
else:
test_iter = ts_gen()
model = load_model("best_model.49-0.00.h5")
pres = model.predict_generator(generator=test_iter,steps=math.ceil(528/Batch_size),verbose=1)
print(pres.shape)
ohpres = np.argmax(pres,axis=1)
print(ohpres.shape)
#img_list = pd.read_csv(TEST_MANIFEST_DIR)
df = pd.DataFrame()
df["id"] = np.arange(1,len(ohpres)+1)
df["label"] = ohpres
df.to_csv("submmit.csv",index=None)
训练过程输出(最优结果:32/32 [==============================] - 1s 33ms/step - loss: 0.0098 - acc: 0.9969 - val_loss: 0.0172 - val_acc: 0.9924)
Epoch 46/50
32/32 [==============================] - 1s 33ms/step - loss: 0.0638 - acc: 0.9766 - val_loss: 0.2460 - val_acc: 0.9242
Epoch 00046: val_loss did not improve from 0.00354
Epoch 47/50
32/32 [==============================] - 1s 33ms/step - loss: 0.0426 - acc: 0.9859 - val_loss: 0.0641 - val_acc: 0.9848
Epoch 00047: val_loss did not improve from 0.00354
Epoch 48/50
32/32 [==============================] - 1s 33ms/step - loss: 0.0148 - acc: 0.9969 - val_loss: 0.0072 - val_acc: 1.0000
Epoch 00048: val_loss did not improve from 0.00354
Epoch 49/50
32/32 [==============================] - 1s 34ms/step - loss: 0.0061 - acc: 0.9984 - val_loss: 0.0404 - val_acc: 0.9857
Epoch 00049: val_loss did not improve from 0.00354
Epoch 50/50
32/32 [==============================] - 1s 33ms/step - loss: 0.0098 - acc: 0.9969 - val_loss: 0.0172 - val_acc: 0.9924
最后是进行预测与提交,代码在上面大家可以自己运行一下。
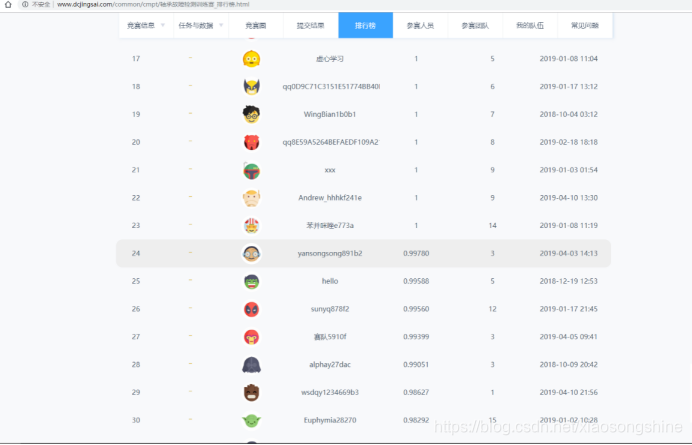
预测结果
排行榜:第24名
展望
此Baseline采用最简单的一维卷积达到了99.8%测试准确率,这体现了一维卷积在一维时序序列的应用效果。
hope this helps
个人网站--> http://www.yansongsong.cn/
Github项目地址--> https://github.com/xiaosongshine/bearing_detection_by_conv1d
欢迎Fork+Star,觉得有用的话,麻烦小小鼓励一下 ><
[深度应用]·DC竞赛轴承故障检测开源Baseline(基于Keras 1D卷积 val_acc:0.99780)的更多相关文章
- 『深度应用』一小时教你上手MaskRCNN·Keras开源实战(Windows&Linux)
0. 前言介绍 开源地址:https://github.com/matterport/Mask_RCNN 个人主页:http://www.yansongsong.cn/ MaskRCNN是何凯明基于以 ...
- [深度应用]·首届中国心电智能大赛初赛开源Baseline(基于Keras val_acc: 0.88)
[深度应用]·首届中国心电智能大赛初赛开源Baseline(基于Keras val_acc: 0.88) 个人主页--> https://xiaosongshine.github.io/ 项目g ...
- 深度学习中的Data Augmentation方法(转)基于keras
在深度学习中,当数据量不够大时候,常常采用下面4中方法: 1. 人工增加训练集的大小. 通过平移, 翻转, 加噪声等方法从已有数据中创造出一批"新"的数据.也就是Data Augm ...
- 开源:基于Android的室内定位WiFi,iBeacon数据采集和定位脚本
最近有同学联系我,也在一些群里看到有新手同学挣扎在怎么获取定位数据,不知从何下手.所以整理并开源这个基于Android的数据采集软件和基于python的KNN定位demo,算是为新手同学建立一个Bas ...
- 一个技术汪的开源梦 —— 基于 .Net Core 的公共组件之 Http 请求客户端
一个技术汪的开源梦 —— 目录 想必大家在项目开发的时候应该都在程序中调用过自己内部的接口或者使用过第三方提供的接口,咱今天不讨论 REST ,最常用的请求应该就是 GET 和 POST 了,那下面开 ...
- gRPC:Google开源的基于HTTP/2和ProtoBuf的通用RPC框架
gRPC:Google开源的基于HTTP/2和ProtoBuf的通用RPC框架 gRPC:Google开源的基于HTTP/2和ProtoBuf的通用RPC框架 Google Guava官方教程(中文版 ...
- DoNet开源项目-基于jQuery EasyUI的后台管理系统
博主在业余时间开发了一个简单的后台管理系统,其中用到了 jQuery EasyUI 框架,上次分享过系统布局,参考文章:jQuery EasyUI 后台管理系统布局分享,目前已完成系统的整体框架的搭建 ...
- DoNet开源项目-基于Amaze UI的点餐系统
帮朋友做的点餐系统,主要是为了让顾客在餐桌上,使用微信扫描二维码,就可以直接点菜,吃完使用微信付款. 系统演示地址,账户名和密码均为:admin.(请不要删除admin用户) GitHub Clone ...
- [AI开发]centOS7.5上基于keras/tensorflow深度学习环境搭建
这篇文章详细介绍在centOS7.5上搭建基于keras/tensorflow的深度学习环境,该环境可用于实际生产.本人现在非常熟练linux(Ubuntu/centOS/openSUSE).wind ...
随机推荐
- bzoj5342 CTSC2018 Day1T3 青蕈领主
首先显然的是,题中所给出的n个区间要么互相包含,要么相离,否则一定不合法. 然后我们可以对于直接包含的关系建出一棵树,于是现在的问题就是给n个节点分配权值,使其去掉最后一个点后不存在非平凡(长度大于1 ...
- uoj123 【NOI2013】小Q的修炼
搞了一下午+半晚上.其实不是很难. 提答题重要的是要发现数据的特殊性质,然后根据不同数据写出不同的算法获得其对应的分数. 首先前两个测试点我们发现可以直接暴搜通过,事实上对于每个数据都暴搜加上一定的次 ...
- Dubbo原理和源码解析之标签解析
一.Dubbo 配置方式 Dubbo 支持多种配置方式: XML 配置:基于 Spring 的 Schema 和 XML 扩展机制实现 属性配置:加载 classpath 根目录下的 dubbo.pr ...
- window 7 安装Jmeter并配置https录制脚本
安装与环境配置: http://blog.csdn.net/hhuangdanfeng/article/details/51564765 http://blog.csdn.net/u010573212 ...
- kubernetes 微服务西游记(持续更新中...)
随着微服务架构的流行,迈向云原生的趋势,容器化微服务就成为了持续集成最好的手段,镜像成为了持续交付最好的产物,容器成为了镜像运行最好的环境,kubernetes成了部署容器最好的生态系统和规范.实践出 ...
- Java编程思想 - 并发
前言 Q: 为什么学习并发? A: 到目前为止,你学到的都是有关顺序编程的知识,即程序中的所有事物在任意时刻都只能执行一个步骤. A: 编程问题中相当大的一部分都可以通过使用顺序编程来解决,然而,对于 ...
- go语言调度器源代码情景分析之二:CPU寄存器
本文是<go调度器源代码情景分析>系列 第一章 预备知识的第1小节. 寄存器是CPU内部的存储单元,用于存放从内存读取而来的数据(包括指令)和CPU运算的中间结果,之所以要使用寄存器来临时 ...
- asp.net core系列 43 Web应用 Session分布式存储(in memory与Redis)
一.概述 HTTP 是无状态的协议. 默认情况下,HTTP 请求是不保留用户值或应用状态的独立消息. 本文介绍了几种保留请求间用户数据和应用状态的方法.下面以表格形式列出这些存储方式,本篇专讲Sess ...
- PostgreSQL:安装及中文显示
一.PostgreSQL PostgreSQL (也称为Post-gress-Q-L)是一个跨平台的功能强大的开源对象关系数据库管理系统,由 PostgreSQL 全球开发集团(全球志愿者团队)开发. ...
- 【原】使用less实现随机下雪动画
元旦在公司撸码,想起圣诞节的摇摇乐项目有段代码挺有意思的,借着空闲的时间把代码抽出来,沉淀下经验.冬天来了,设计师说摇摇乐的场景需要随机下落的雪花动画,第一时间就想到的方法是canvas比较好,项目非 ...