机器学习中 K近邻法(knn)与k-means的区别
简介
K近邻法(knn)是一种基本的分类与回归方法。k-means是一种简单而有效的聚类方法。虽然两者用途不同、解决的问题不同,但是在算法上有很多相似性,于是将二者放在一起,这样能够更好地对比二者的异同。
算法描述
knn
算法思路:
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
k近邻模型的三个基本要素:
- k值的选择:k值的选择会对结果产生重大影响。较小的k值可以减少近似误差,但是会增加估计误差;较大的k值可以减小估计误差,但是会增加近似误差。一般而言,通常采用交叉验证法来选取最优的k值。
- 距离度量:距离反映了特征空间中两个实例的相似程度。可以采用欧氏距离、曼哈顿距离等。
- 分类决策规则:往往采用多数表决。
k-means
算法步骤:
1. 从n个数据中随机选择 k 个对象作为初始聚类中心;
2. 根据每个聚类对象的均值(中心对象),计算每个数据点与这些中心对象的距离;并根据最小距离准则,重新对数据进行划分;
3. 重新计算每个有变化的聚类簇的均值,选择与均值距离最小的数据作为中心对象;
4. 循环步骤2和3,直到每个聚类簇不再发生变化为止。
k-means方法的基本要素:
- k值的选择:也就是类别的确定,与K近邻中k值的确定方法类似。
- 距离度量:可以采用欧氏距离、曼哈顿距离等。
应用实例
问题描述
已知若干人的性别、身高和体重,给定身高和体重判断性别。考虑使用k近邻算法实现性别的分类,使用k-means实现性别的聚类。
数据
数据集合:https://github.com/shuaijiang/FemaleMaleDatabase
该数据集包含了训练数据集和测试数据集,考虑在该数据集上利用k近邻算法和k-means方法分别实现性别的分类和聚类。
将训练数据展示到图中,可以更加直观地观察到数据样本之间的联系和差异,以及不同性别之间的差异。
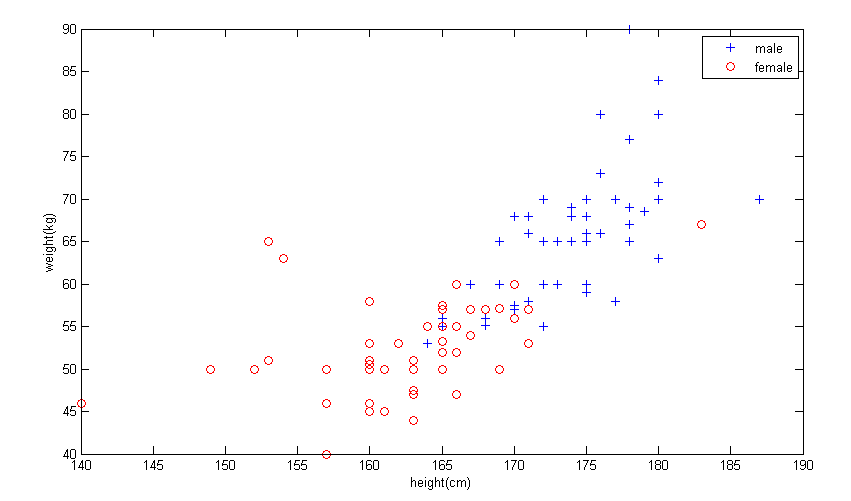 数据展示
数据展示
KNN的分类结果
KNN算法中的基本设置
- k=5
- 距离度量:欧氏距离
- 分类决策规则:多数投票
- 测试集:https://github.com/shuaijiang/FemaleMaleDatabase/blob/master/test0.txt
利用KNN算法,在测试集上的结果如下混淆矩阵表所示。从表中可以看出,测试集中的男性全部分类正确,测试集中的女性有一个被错误分类,其他都分类正确。
混淆矩阵 Test:male Test:female Result:male 20 1 Result:female 0 14
(表注:Test:male、Test:female分别表示测试集中的男性和女性,Result:male和Result:female分别表示结果中的男性和女性。表格中第一个元素:即Test:male列、Result:male行,表示测试集中为男性、并且结果中也为男性的数目。表格中其他元素所代表的含义以此类推)
由上表可以计算分类的正确率:(20+14)/(20+14+1) = 97.14%
K-means的聚类结果
K-means算法的基本设置
- k=2
- 距离度量:欧氏距离
- 最大聚类次数:200
- 类别决策规则:根据每个聚类簇中的多数决定类别
- 测试集:https://github.com/shuaijiang/FemaleMaleDatabase/blob/master/test0.txt
混淆矩阵 Test:male Test:female Result:male 20 1 Result:female 0 14
(表注:该表与上表内容一致)
由于选择初始中心点是随机的,所以每次的聚类结果都不相同,最好的情况下能够完全聚类正确,最差的情况下两个聚类簇没有分开,根据多数投票决定类别时,被标记为同一个类别。
KNN VS K-means
二者的相同点:
- k的选择类似
- 思路类似:根据最近的样本来判断某个样本的属性
二者的不同点:
- 应用场景不同:前者是分类或者回归问题,后者是聚类问题;
- 算法复杂度: 前者O(n^2),后者O(kmn);(k是聚类类别数,m是聚类次数)
- 稳定性:前者稳定,后者不稳定。
总结
本文概括地描述了K近邻算法和K-means算法,具体比较了二者的算法步骤。在此基础上,通过将两种方法应用到实际问题中,更深入地比较二者的异同,以及各自的优劣。本文作者还分别实现了K近邻算法和K-means算法,并且应用到了具体问题上,最后得到了结果。
以上内容难免有所纰漏和错误,欢迎指正。
机器学习中 K近邻法(knn)与k-means的区别的更多相关文章
- K近邻法(KNN)原理小结
K近邻法(k-nearst neighbors,KNN)是一种很基本的机器学习方法了,在我们平常的生活中也会不自主的应用.比如,我们判断一个人的人品,只需要观察他来往最密切的几个人的人品好坏就可以得出 ...
- k近邻法(KNN)和KMeans算法
k近邻算法(KNN): 三要素:k值的选择,距离的度量和分类决策规则 KMeans算法,是一种无监督学习聚类方法: 通过上述过程可以看出,和EM算法非常类似.一个简单例子, k=2: 畸变函数(dis ...
- scikit-learn K近邻法类库使用小结
在K近邻法(KNN)原理小结这篇文章,我们讨论了KNN的原理和优缺点,这里我们就从实践出发,对scikit-learn 中KNN相关的类库使用做一个小结.主要关注于类库调参时的一个经验总结. 1. s ...
- 机器学习--K近邻 (KNN)算法的原理及优缺点
一.KNN算法原理 K近邻法(k-nearst neighbors,KNN)是一种很基本的机器学习方法. 它的基本思想是: 在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对 ...
- 机器学习PR:k近邻法分类
k近邻法是一种基本分类与回归方法.本章只讨论k近邻分类,回归方法将在随后专题中进行. 它可以进行多类分类,分类时根据在样本集合中其k个最近邻点的类别,通过多数表决等方式进行预测,因此不具有显式的学习过 ...
- k近邻法(kNN)
<统计学习方法>(第二版)第3章 3 分类问题中的k近邻法 k近邻法不具有显式的学习过程. 3.1 算法(k近邻法) 根据给定的距离度量,在训练集\(T\)中找出与\(x\)最邻近的\(k ...
- k近邻法
k近邻法(k nearest neighbor algorithm,k-NN)是机器学习中最基本的分类算法,在训练数据集中找到k个最近邻的实例,类别由这k个近邻中占最多的实例的类别来决定,当k=1时, ...
- 学习笔记——k近邻法
对新的输入实例,在训练数据集中找到与该实例最邻近的\(k\)个实例,这\(k\)个实例的多数属于某个类,就把该输入实例分给这个类. \(k\) 近邻法(\(k\)-nearest neighbor, ...
- 机器学习笔记(十)---- KNN(K Nearst Neighbor)
KNN是一种常见的监督学习算法,工作机制很好理解:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这k个"邻居"的信息来进行预测.总结一句话就是&quo ...
随机推荐
- java设计模式-----11、代理模式
Proxy模式又叫做代理模式,是构造型的设计模式之一,它可以为其他对象提供一种代理(Proxy)以控制对这个对象的访问. 所谓代理,是指具有与代理元(被代理的对象)具有相同的接口的类,客户端必须通过代 ...
- Git常用命令手册
github 的使用教程(非常详细的小白视频)链接如下: http://yun.itheima.com/course/209.html Git 详细使用手册链接如下: https://git-scm. ...
- Linux shell 脚本(一)
一.初识脚本 shell:一类介于系统内核与用户之间的解释程序.脚本:一类使用特定语言,按预设顺序执行的文件批处理.宏.解释型程序创建shell脚本:理清任务过程--整理执行语句--完善文件结构1.任 ...
- Hadoop的Archive归档命令使用指南
hadoop不适合小文件的存储,小文件本省就占用了很多的metadata,就会造成namenode越来越大.Hadoop Archives的出现视为了缓解大量小文件消耗namenode内存的问题. 采 ...
- win8.1下无法运行vc++6.0的解决方法
参考网址: http://wenku.baidu.com/link?url=A6mzeCDLNW1vCV7Vm5p83jqSzguiOFlH5FX-7kdN9NJXS_ORXYuaVDn1Prnz_F ...
- NEO从入门到开窗(1) - 一个智能合约的诞生
一.啰嗦两句 最近一直都在研究区块链,BitCoin,Etherenum, Hyper Ledger Fabric还有今天的主角小蚂蚁,当然出名以后改了一个艺名叫NEO.区块链大部分都是用Golang ...
- Java日志框架:slf4j作用及其实现原理
简单回顾门面模式 slf4j是门面模式的典型应用,因此在讲slf4j前,我们先简单回顾一下门面模式, 门面模式,其核心为外部与一个子系统的通信必须通过一个统一的外观对象进行,使得子系统更易于使用.用一 ...
- spring cloud 专题一 (spring cloud 入门搭建 之 Eureka注册中心搭建)
一.前言 本文为spring cloud 微服务框架专题的第一篇,主要讲解如何快速搭建spring cloud微服务及Eureka 注册中心 以及常用开发方式等. 本文理论不多,主要是傻瓜式的环境搭建 ...
- RxJS速成 (上)
What is RxJS? RxJS是ReactiveX编程理念的JavaScript版本.ReactiveX是一种针对异步数据流的编程.简单来说,它将一切数据,包括HTTP请求,DOM事件或者普通数 ...
- 笔记:Maven Web项目
生成Web项目模块 生成Web项目模板和生成其他项目的模板一致,差别是指定模板的类型,执行命令如下: mvn archetype:generate -DarchetypeArtifactId=mave ...