Python爬虫实践 -- 记录我的第二只爬虫
1、爬虫基本原理
我们爬取中国电影最受欢迎的影片《红海行动》的相关信息。其实,爬虫获取网页信息和人工获取信息,原理基本是一致的。

人工操作步骤:
1. 获取电影信息的页面
2. 定位(找到)到评分信息的位置
3. 复制、保存我们想要的评分数据
爬虫操作步骤:
1. 请求并下载电影页面信息
2. 解析并定位评分信息
3. 保存评分数据
综合言之,原理图如下:
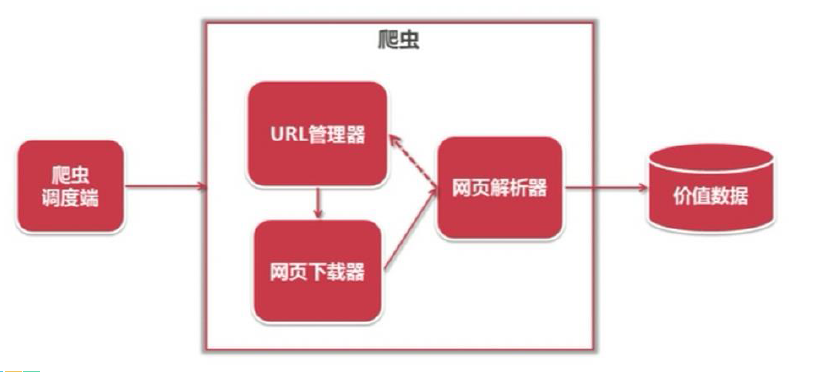
2、爬虫的基本流程
简单来说,我们向服务器发送请求后,会得到返回的页面;通过解析页面之后,我们可以抽取我们想要的那部分信息,并存储在指定的文档或数据库中。这样,我们想要的信息就被我们“爬”下来啦~

3、安装python依赖包 Requests+Xpath
Python 中爬虫相关的包很多:Urllib、requsts、bs4……我们从简单 requests+xpath 上手!更高级的 BeautifulSoup 还是有点难的。
然后我们安装 requests+xpath 的应用包以爬取豆瓣电影:
在Windows 终端分别输入以下两行代码:
pip install requestspip install lxml
4、代码整理--获取豆瓣电影目标网页并解析
我们要爬取豆瓣电影《红海行动》相关信息,目标地址是:https://movie.douban.com/subject/26861685/
给定 url 并用 requests.get() 方法来获取页面的text,用 etree.HTML() 来解析下载的页面数据“data”。
url = 'https://movie.douban.com/subject/26861685/' data = requests.get(url).text s=etree.HTML(data)
5、获取电影名称
获取元素的Xpath信息并获得文本:
file=s.xpath('元素的Xpath信息/text()')
这里的“元素的Xpath信息”是需要我们手动获取的,获取方式为:定位目标元素,在网站上依次点击:右键 > 检查
快捷键“shift+ctrl+c”,移动鼠标到对应的元素时即可看到对应网页代码:
在电影标题对应的代码上依次点击 右键 > Copy > Copy XPath,获取电影名称的Xpath:
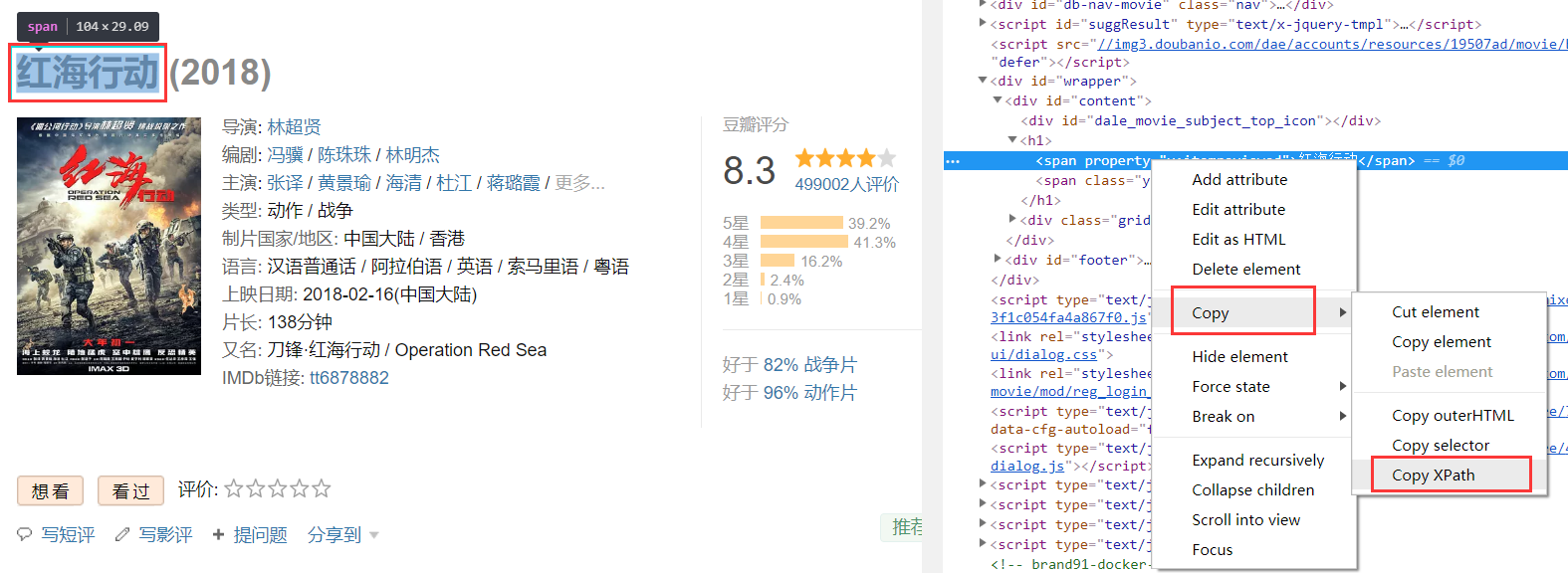
这样我们就把元素中的Xpath信息复制下来了:
//*[@id="content"]/h1/span[1]
放到代码中并打印信息:
film=s.xpath('//*[@id="content"]/h1/span[1]/text()')
print(film)
6、 代码以及运行结果
以上完整代码如下:
import requests from lxml
import etree url = 'https://movie.douban.com/subject/26861685/'
data = requests.get(url).text
s=etree.HTML(data)
film=s.xpath('//*[@id="content"]/h1/span[1]/text()') print (film)
在 Pycharm 中运行完整代码及结果如下:

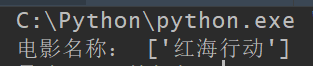
至此,我们完成了爬取豆瓣电影《红海行动》中“电影名称”信息的代码编写,可以在 Pycharm 中运行。
7、 获取其它元素信息
除了电影的名字,我们还可以获取导演、主演、电影片长等信息,获取的方式是类似的。代码如下:
director=s.xpath('//*[@id="info"]/span[1]/span[2]/a/text()') #导演
actor1=s.xpath('//*[@id="info"]/span[3]/span[2]/span[1]/a/text()') #主演1
actor2=s.xpath('//*[@id="info"]/span[3]/span[2]/span[2]/a/text()') #主演2
actor3=s.xpath('//*[@id="info"]/span[3]/span[2]/span[3]/a/text()') #主演3
time=s.xpath(‘//*[@id="info"]/span[12]/text()') #电影片长
观察上面的代码,发现获取不同“主演”信息时,区别只在于“span[x]”中“x”的数字大小不同。实际上,要一次性获取所有“主演”的信息时,用不加数字的“a”表示即可。代码如下:
actor=s.xpath('//*[@id="info"]/span[3]/span[2]/a/text()') #主演完整代码如下:
import requests
from lxml import etree
url = 'https://movie.douban.com/subject/26861685/'
data = requests.get(url).text
s=etree.HTML(data)
film=s.xpath('//*[@id="content"]/h1/span[1]/text()') #导演
director=s.xpath('//*[@id="info"]/span[1]/span[2]/a/text()') #导演
actor=s.xpath('//*[@id="info"]/span[3]/span[2]/a/text()') #主演
time=s.xpath('//*[@id="info"]/span[12]/text()') #电影片长
print('电影名称:',film)
print('导演:',director)
print('主演:',actor)
print('片长:',time)
在 Pycharm 中运行完整代码结果如下:

8、 关于解析神器 Xpath
Xpath 即为 XML 路径语言(XML Path Language),它是一种用来确定 XML 文档中某部分位置的语言。
Xpath 基于 XML 的树状结构,提供在数据结构树中找寻节点的能力。起初 Xpath 的提出的初衷是将其作为一个通用的、介于 Xpointer 与 XSL 间的语法模型。但是Xpath 很快的被开发者采用来当作小型查询语言。
Xpath解析网页的流程:
1. 首先通过Requests库获取网页数据
2. 通过网页解析,得到想要的数据或者新的链接
3. 网页解析可以通过 Xpath 或者其它解析工具进行,Xpath 在是一个非常好用的网页解析工具

常见的网页解析方法比较

- 正则表达式使用比较困难,学习成本较高
- BeautifulSoup 性能较慢,相对于 Xpath 较难,在某些特定场景下有用
- Xpath 使用简单,速度快(Xpath是lxml里面的一种),是入门最好的选择
Python爬虫实践 -- 记录我的第二只爬虫的更多相关文章
- Python爬虫实践 -- 记录我的第一只爬虫
一.环境配置 1. 下载安装 python3 .(或者安装 Anaconda) 2. 安装requests和lxml 进入到 pip 目录,CMD --> C:\Python\Scripts,输 ...
- Python爬虫个人记录(三)爬取妹子图
这此教程可能会比较简洁,具体细节可参考我的第一篇教程: Python爬虫个人记录(一)豆瓣250 Python爬虫个人记录(二)fishc爬虫 一.目的分析 获取煎蛋妹子图并下载 http://jan ...
- Python爬虫学习记录【内附代码、详细步骤】
引言: 昨天在网易云课堂自学了<Python网络爬虫实战>,视频链接 老师讲的很清晰,跟着实践一遍就能掌握爬虫基础了,强烈推荐! 另外,在网上看到一位学友整理的课程记录,非常详细,可以优先 ...
- Python爬虫个人记录(二) 获取fishc 课件下载链接
参考: Python爬虫个人记录(一)豆瓣250 (2017.9.6更新,通过cookie模拟登陆方法,已成功实现下载文件功能!!) 一.目的分析 获取http://bbs.fishc.com/for ...
- python爬虫实践
模拟登陆与文件下载 爬取http://moodle.tipdm.com上面的视频并下载 模拟登陆 由于泰迪杯网站问题,测试之后发现无法用正常的账号密码登陆,这里会使用访客账号登陆. 我们先打开泰迪杯的 ...
- # Python 3 & 爬虫一些记录
目录 Python 3 & 爬虫一些记录 交互模式和命令行模式 函数积累 语法积累 列表和元组 输入 交互模式下输入多行 爬虫 HTTP报文请求头User-Agent信息 解析库pyquery ...
- 路飞学城—Python爬虫实战密训班 第二章
路飞学城—Python爬虫实战密训班 第二章 一.Selenium基础 Selenium是一个第三方模块,可以完全模拟用户在浏览器上操作(相当于在浏览器上点点点). 1.安装 - pip instal ...
- python编写知乎爬虫实践
爬虫的基本流程 网络爬虫的基本工作流程如下: 首先选取一部分精心挑选的种子URL 将种子URL加入任务队列 从待抓取URL队列中取出待抓取的URL,解析DNS,并且得到主机的ip,并将URL对应的网页 ...
- powershell中的两只爬虫
--------------------序-------------------- (PowerShell中的)两只爬虫,两只爬虫,跑地快,爬网页不赖~~~ 一只基于com版的ie,一只基于.net中 ...
随机推荐
- Android两级导航菜单栏的实现--FragmentTabHost结合ViewPager与Android 开源项目PagerSlidingTabStrip
http://www.cnblogs.com/aademeng/articles/6119737.html 转载注:简单总结一下,外层Tab用TabHost,类层Tab用Viepager+Framen ...
- sqlite db数据的导出
sqlite的db数据一般是filename.db的格式,用普通文本编辑器打开是乱码,用sqlite名令操作比较麻烦,有时版本格式问题还会起阻扰,有一个GUI工具可以对sqlite db格式数据进行管 ...
- Linux下高并发socket最大连接数
http://soft.chinabyte.com/os/285/12349285.shtml (转载时原文内容做个修改) 1.修改用户进程可打开文件数限制 在Linux平台上,无论编写客户端程序还是 ...
- openresty + lua-resty-weedfs + weedfs + graphicsmagick动态生成缩略图(类似淘宝方案)
openresty + lua-resty-weedfs + weedfs + graphicsmagick动态生成缩略图(类似淘宝方案) --大部分的网站都要涉及到图片缩略图的处理,比如新闻配图,电 ...
- FatMouse' Trade -HZNU寒假集训
FatMouse' Trade FatMouse prepared M pounds of cat food, ready to trade with the cats guarding the wa ...
- springboot中使用分页,文件上传,jquery的具体步骤(持续更新)
分页: pom.xml 加依赖 <dependency> <groupId>com.github.pagehelper</groupId> <arti ...
- C 上传文件到服务器(含接收端源码)
本文demo下载地址:http://www.wisdomdd.cn/Wisdom/resource/articleDetail.htm?resourceId=1067 实例向大家展示了如何用Visua ...
- 【热身】github的使用
GitHub 可以托管各种Git版本库,并提供一个web界面,但与其它像 SourceForge或Google Code这样的服务不同,GitHub的独特卖点在于从另外一个项目进行分支的简易性.为一个 ...
- 用ECMAScript4 ( ActionScript3) 实现Unity的热更新 -- 使用FairyGUI (二)
上次讲解了FairyGUI的最简单的热更新办法,并对其中一个Demo进行了修改并做成了热更新的方式. 这次我们来一个更加复杂一些的情况:Emoji. FairyGUI的 Example 04 - ...
- 原生 JavaScript 实现扫雷
学习了这么长时间的 JS,不能光看不练,于是就写了个小游戏练习一下.因为自己还是个菜鸟,所以有错误的话还请各位大佬多多指点,谢谢啦~ 如果感兴趣的话可以试试:Demo 项目地址:game-mineSw ...