B树和B+树详解
一 B树
1.B树的定义:B树(B-tree)是一种树状数据结构,它能够存储数据、对其进行排序并允许以O(log n)的时间复杂度运行进行查找、顺序读取、插入和删除的数据结构。B树,概括来说是一个节点可以拥有多于2个子节点的二叉查找树。
2.B树的特征:
- 根节点至少有两个子节点
- 每个中间节点都包含k-1个元素和k个孩子,其中 m/2 ≤ k ≤ m (m为树的阶)
- 每个叶子节点都包含k-1个元素,其中 m/2 ≤ k ≤ m (m为树的阶)
- 每个节点中的元素从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域划分(一个结点有k个孩子时,必有k-1个元素才能将子树中所有元素划分为k个子集)
3.B树的操作
3.1 B树的查找:如下图,查询元素8
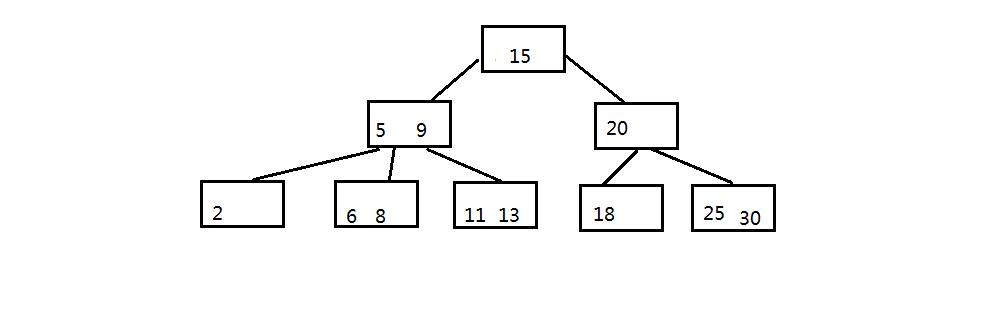
第一次磁盘IO:把15所在节点读到内存中,然后与8做比较,小于15,找到下一个节点(5和9对应的节点)
第二次磁盘IO:把5和9所在的节点读到内存中,然后与8做比较,5<8<9,找到下一个节点(6和8对应的节点)
第三次磁盘IO:把6和8所在节点读到内存中,然后与8做比较,找到了元素8
3.1 B树的插入: 将元素7插入下图中的B树
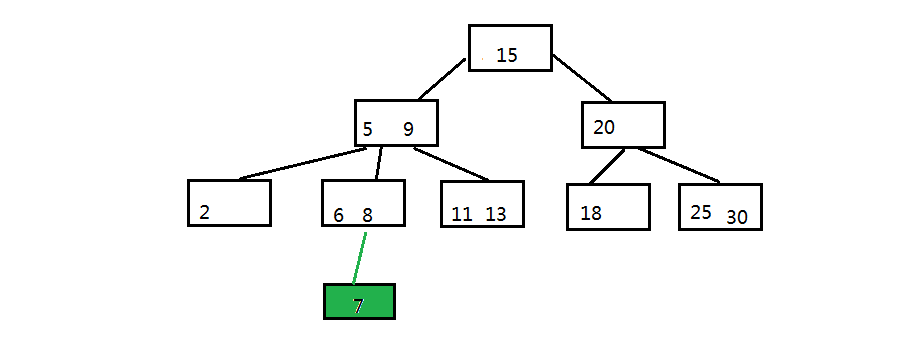
步骤一:自顶向下查找元素7应该在的位置,即在6和8之间
步骤二:三阶B树中的节点最多有两个元素,把6 7 8里面的中间元素上移(中间元素上移是插入操作的关键)
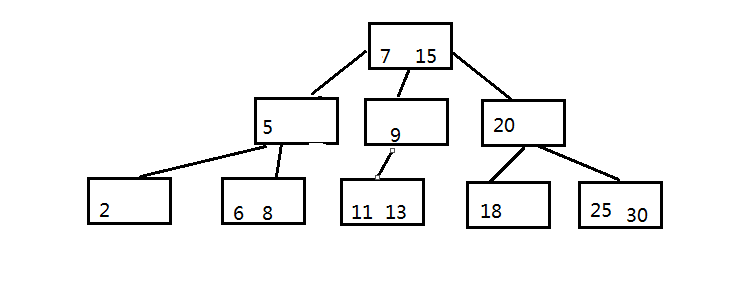
步骤三:上移之后,上一层节点元素也超载了,5 7 9中间元素上移,现在根节点变为了 7 15
步骤四:要对B树进行调整,使其满足B树的特性,最终如下图:
二 B+树
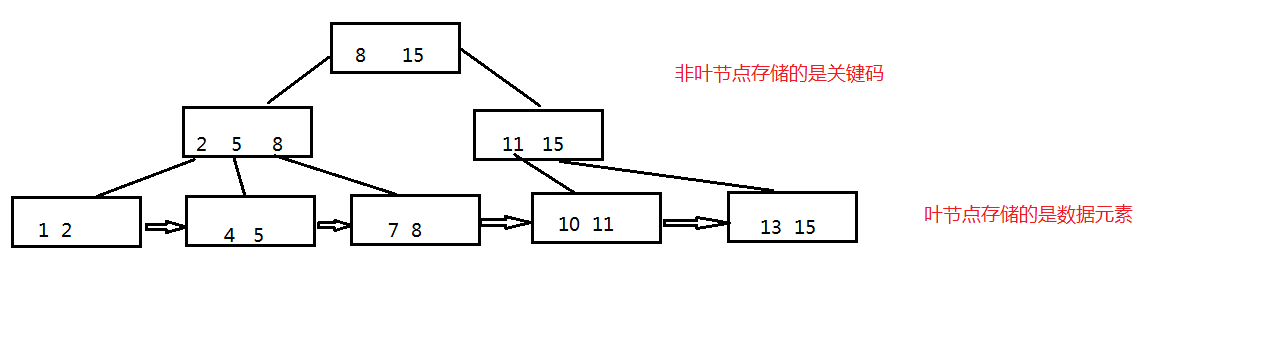
B+树是B树的一种变形体,它与B树的差异在于:
- 有K个子节点的节点必然有K个关键码
- 非叶节点仅具有索引作用,元素信息均存放在叶节点中
- 树的所有叶节点构成一个有序链表,可以按照关键码排序的次序遍历全部记录
B+树的优势:
- 由于B+树在内部节点上不包含数据信息,因此在内存页中能够存放更多的key。 数据存放的更加紧密,具有更好的空间局部性。因此访问叶子节点上关联的数据也具有更好的缓存命中率。
- B+树的叶子节点都是相连的,因此对整棵树的遍历只需要一次线性遍历叶子节点即可。而且由于数据顺序排列并且相连,所以便于区间查找和搜索。而B树则需要进行每一层的递归遍历。相邻的元素可能在内存中不相邻,所以缓存命中性没有B+树好。
总结:我们知道二叉查找树的时间复杂度是O(logN),效率已经足够高。为什么出现B树和B+树呢?当大量数据存储在磁盘上,进行查询操作时,需要先将数据加载到内存中(磁盘IO操作),而数据并不能一次性全部加载到内存中,只能逐一加载每个磁盘页(对应树的一个节点),并且磁盘IO操作很慢,平衡二叉树由于树深度过大而造成磁盘IO读写过于频繁,进而导致效率低下。为了减少磁盘IO的次数,就需要降低树的深度,那么就引出了B树和B+树:每个节点存储多个元素,采用多叉树结构。这样就提高了效率,比如数据库索引,就是存储在磁盘上,采用的就是B+树的数据结构。
B树和B+树详解的更多相关文章
- 哈夫曼树(三)之 Java详解
前面分别通过C和C++实现了哈夫曼树,本章给出哈夫曼树的java版本. 目录 1. 哈夫曼树的介绍 2. 哈夫曼树的图文解析 3. 哈夫曼树的基本操作 4. 哈夫曼树的完整源码 转载请注明出处:htt ...
- 哈夫曼树(二)之 C++详解
上一章介绍了哈夫曼树的基本概念,并通过C语言实现了哈夫曼树.本章是哈夫曼树的C++实现. 目录 1. 哈夫曼树的介绍 2. 哈夫曼树的图文解析 3. 哈夫曼树的基本操作 4. 哈夫曼树的完整源码 转载 ...
- B树、B+树、B*树三者的对比详解
转载至:https://www.2cto.com/database/201805/745822.html 对比 B+树是B树的变体,B*树又是B+树的变体,是一脉相承法治国拉的,不断解决新一阶段的问题 ...
- AVL树的旋转操作详解
[0]README 0.0) 本文部分idea 转自:http://blog.csdn.net/collonn/article/details/20128205 0.1) 本文仅针对性地分析AVL树的 ...
- 有趣的 zkw 线段树(超全详解)
zkw segment-tree 真是太棒了(真的重口味)!写篇博客纪念入门 emmm...首先我们来介绍一下 zkw 线段树这个东西(俗称 "重口味" ,与 KMP 类似,咳咳. ...
- BZOJ 1912: [Apio2010]patrol 巡逻 (树的直径)(详解)
题目: https://www.lydsy.com/JudgeOnline/problem.php?id=1912 题解: 首先,显然当不加边的时候,遍历一棵树每条边都要经过两次.那么现在考虑k==1 ...
- 可持久化线段树(主席树)(图文并茂详解)【poj2104】【区间第k大】
[pixiv] https://www.pixiv.net/member_illust.php?mode=medium&illust_id=63740442 向大(hei)佬(e)实力学(di ...
- AVL树(二叉平衡树)详解与实现
AVL树概念 前面学习二叉查找树和二叉树的各种遍历,但是其查找效率不稳定(斜树),而二叉平衡树的用途更多.查找相比稳定很多.(欢迎关注数据结构专栏) AVL树是带有平衡条件的二叉查找树.这个平衡条件必 ...
- 决策树--CART树详解
1.CART简介 CART是一棵二叉树,每一次分裂会产生两个子节点.CART树分为分类树和回归树. 分类树主要针对目标标量为分类变量,比如预测一个动物是否是哺乳动物. 回归树针对目标变量为连续值的情况 ...
- 从Trie树(字典树)谈到后缀树
转:http://blog.csdn.net/v_july_v/article/details/6897097 引言 常关注本blog的读者朋友想必看过此篇文章:从B树.B+树.B*树谈到R 树,这次 ...
随机推荐
- springboot~maven制作底层公用库
把一些公用方法,类型抽象到一个项目里,让其它项目依赖它,这种设计是一种解耦的体现,其实像springboot就是我们的一种依赖,他里面有很多子模块,用到哪个就添加哪个依赖即可,像redis,mongo ...
- Hadoop3.2.0使用详解
1.概述 Hadoop3已经发布很久了,迭代集成的一些新特性也是很有用的.截止本篇博客书写为止,Hadoop发布了3.2.0.接下来,笔者就为大家分享一下在使用Hadoop3中遇到到一些问题,以及解决 ...
- 生产线平衡问题的+Leapms线性规划方法
知识点 第一类生产线平衡问题,第二类生产线平衡问题 整数线性规划模型,+Leapms模型,直接求解,CPLEX求解 装配生产线平衡问题 (The Assembly Line Balancing Pro ...
- 极光推送经验之谈-Java后台服务器实现极光推送的两种实现方式
原创作品,可以转载,但是请标注出处地址http://www.cnblogs.com/V1haoge/p/6439313.html Java后台实现极光推送有两种方式,一种是使用极光推送官方提供的推送请 ...
- JMeter主要组件介绍
JMeter主要组件介绍 转自https://www.cnblogs.com/linbo3168/p/6023962.html 作者:linbo.yang 1.测试计划(Test Plan)是使用 ...
- vue学习记录②(hello world!)
接着上篇vue-cli脚手架构建项目结构建好项目之后,就开始写个“hello world!”吧~~~ vue玩的都是组件,所以开发的也是组件. 1.新建helloworld.vue.(删除Hello. ...
- vue 单文件组件中样式加载
在写单文件组件时,一般都是把标签.脚本.样式写到一起,这样写个人感觉有点不够简洁,所以就想着把样式分离出去. 采用import加载样式 在局部作用域(scoped)采用@import加载进来的样式文件 ...
- elementUi的时间选择器在IE浏览器的赋值问题--前端
项目技术:vue+elementUi,组件化 出现的问题:在IE浏览器(IE10+),唤醒组件加载赋值,表单中el-input等框赋值正确,el-date-picker选择器没有显示所附的值(或显示p ...
- flex 增长与收缩
flex:auto 将增长值与收缩值设置为1,基本大小为 auto . flex:none. 将增长值与收缩值设置为0,基本大小为 auto .也就是固定大小. 增长: 基本大小 + 额外空间 *( ...
- hadoop集群的搭建
hadoop集群的搭建 1.ubuntu 14.04更换成阿里云源 刚刚开始我选择了nat模式,所有可以连通网络,但是不能ping通,我就是想安装一下mysql,因为安装手动安装mysql太麻烦了,然 ...