吴恩达深度学习第1课第3周编程作业记录(2分类1隐层nn)
2分类1隐层nn, 作业默认设置:
- 1个输出单元, sigmoid激活函数. (因为二分类);
- 4个隐层单元, tanh激活函数. (除作为输出单元且为二分类任务外, 几乎不选用 sigmoid 做激活函数);
- n_x个输入单元, n_x为训练数据维度;
总的来说共三层: 输入层(n_x = X.shape[0]), 隐层(n_h = 4), 输出层(n_y = 1).
import 和预设置
# Package imports
import numpy as np
import matplotlib.pyplot as plt
from testCases import *
import sklearn
import sklearn.datasets
import sklearn.linear_model
from planar_utils import plot_decision_boundary, sigmoid, load_planar_dataset, load_extra_datasets
%matplotlib inline
np.random.seed(1) # set a seed so that the results are consistent
4 - Neural Network model
Here is our model:
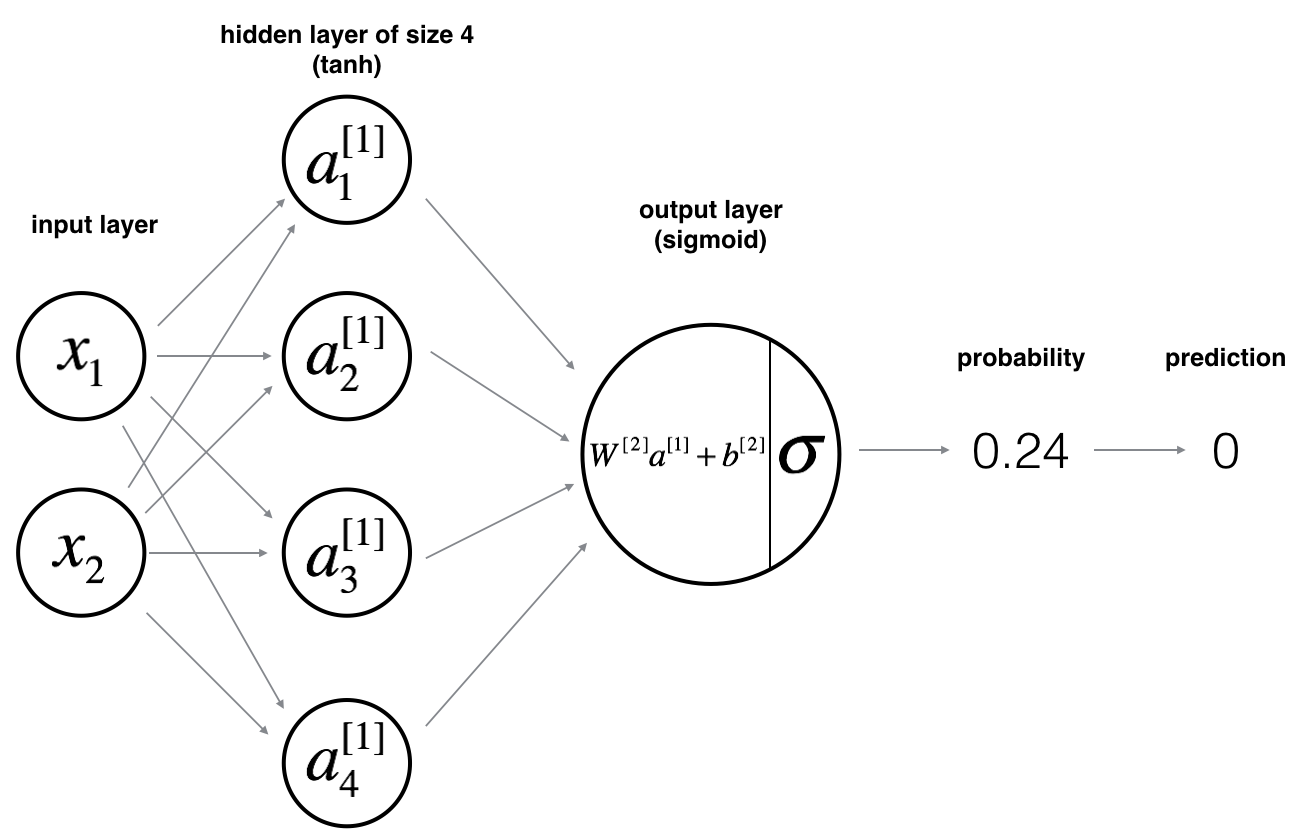
Mathematically:
For one example \(x^{(i)}\):
\]
\]
\]
\]
\]
Given the predictions on all the examples, you can also compute the cost \(J\) as follows:
\]
Reminder: The general methodology to build a Neural Network is to:
1. Define the neural network structure ( # of input units, # of hidden units, etc).
2. Initialize the model's parameters
3. Loop:
- Implement forward propagation
- Compute loss
- Implement backward propagation to get the gradients
- Update parameters (gradient descent)
You often build helper functions to compute steps 1-3 and then merge them into one function we call nn_model(). Once you've built nn_model() and learnt the right parameters, you can make predictions on new data.
4.1 - Defining the neural network structure
# GRADED FUNCTION: layer_sizes
def layer_sizes(X, Y):
"""
Arguments:
X -- input dataset of shape (input size, number of examples)
Y -- labels of shape (output size, number of examples)
Returns:
n_x -- the size of the input layer
n_h -- the size of the hidden layer
n_y -- the size of the output layer
"""
### START CODE HERE ### (≈ 3 lines of code)
n_x = X.shape[0] # size of input layer
n_h = 4
n_y = Y.shape[0] # size of output layer
### END CODE HERE ###
return (n_x, n_h, n_y)
4.2 - Initialize the model's parameters
# GRADED FUNCTION: initialize_parameters
def initialize_parameters(n_x, n_h, n_y):
"""
Argument:
n_x -- size of the input layer
n_h -- size of the hidden layer
n_y -- size of the output layer
Returns:
params -- python dictionary containing your parameters:
W1 -- weight matrix of shape (n_h, n_x)
b1 -- bias vector of shape (n_h, 1)
W2 -- weight matrix of shape (n_y, n_h)
b2 -- bias vector of shape (n_y, 1)
"""
np.random.seed(2) # we set up a seed so that your output matches ours although the initialization is random.
### START CODE HERE ### (≈ 4 lines of code)
W1 = np.random.randn(n_h, n_x) * 0.01
b1 = np.zeros((n_h, 1))
W2 = np.random.randn(n_y, n_h) * 0.01
b2 = np.zeros((n_y, 1))
### END CODE HERE ###
assert (W1.shape == (n_h, n_x))
assert (b1.shape == (n_h, 1))
assert (W2.shape == (n_y, n_h))
assert (b2.shape == (n_y, 1))
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters
4.3 - The Loop
注意, 若换激活函数,有两个地方需要改:
- forward_propagation()中 A1 = np.tanh(Z1)处;
- backward_propagation()中 dZ1中 1 - np.power(A1, 2) 处.
\]
# GRADED FUNCTION: forward_propagation
def forward_propagation(X, parameters):
"""
Argument:
X -- input data of size (n_x, m)
parameters -- python dictionary containing your parameters (output of initialization function)
Returns:
A2 -- The sigmoid output of the second activation
cache -- a dictionary containing "Z1", "A1", "Z2" and "A2"
"""
# Retrieve each parameter from the dictionary "parameters"
### START CODE HERE ### (≈ 4 lines of code)
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
### END CODE HERE ###
# Implement Forward Propagation to calculate A2 (probabilities)
### START CODE HERE ### (≈ 4 lines of code)
Z1 = np.dot(W1, X) + b1
A1 = np.tanh(Z1)
Z2 = np.dot(W2, A1) + b2
A2 = sigmoid(Z2)
### END CODE HERE ###
assert(A2.shape == (1, X.shape[1]))
cache = {"Z1": Z1,
"A1": A1,
"Z2": Z2,
"A2": A2}
return A2, cache
# GRADED FUNCTION: compute_cost
def compute_cost(A2, Y, parameters):
"""
Computes the cross-entropy cost given in equation (13)
Arguments:
A2 -- The sigmoid output of the second activation, of shape (1, number of examples)
Y -- "true" labels vector of shape (1, number of examples)
parameters -- python dictionary containing your parameters W1, b1, W2 and b2
Returns:
cost -- cross-entropy cost given equation (13)
"""
m = Y.shape[1] # number of example
# Compute the cross-entropy cost
### START CODE HERE ### (≈ 2 lines of code)
logprobs = np.multiply(np.log(A2), Y) + np.multiply(np.log(1 - A2), 1 - Y)
cost = -np.sum(logprobs)/m
### END CODE HERE ###
cost = np.squeeze(cost) # makes sure cost is the dimension we expect.
# E.g., turns [[17]] into 17
assert(isinstance(cost, float))
return cost
反向传播时用到的公式:

# GRADED FUNCTION: backward_propagation
def backward_propagation(parameters, cache, X, Y):
"""
Implement the backward propagation using the instructions above.
Arguments:
parameters -- python dictionary containing our parameters
cache -- a dictionary containing "Z1", "A1", "Z2" and "A2".
X -- input data of shape (2, number of examples)
Y -- "true" labels vector of shape (1, number of examples)
Returns:
grads -- python dictionary containing your gradients with respect to different parameters
"""
m = X.shape[1]
# First, retrieve W1 and W2 from the dictionary "parameters".
### START CODE HERE ### (≈ 2 lines of code)
W1 = parameters["W1"]
W2 = parameters["W2"]
### END CODE HERE ###
# Retrieve also A1 and A2 from dictionary "cache".
### START CODE HERE ### (≈ 2 lines of code)
A1 = cache["A1"]
A2 = cache["A2"]
### END CODE HERE ###
# Backward propagation: calculate dW1, db1, dW2, db2.
### START CODE HERE ### (≈ 6 lines of code, corresponding to 6 equations on slide above)
dZ2 = A2 - Y
dW2 = np.dot(dZ2, A1.T)/m
db2 = np.sum(dZ2, axis=1, keepdims=True)/m
# tanh的导数 1-A1^2
# 若换激活函数,有两个地方需要改
# 1. forward_propagation()中 A1 = np.tanh(Z1)处
# 2. 就是这里backward_propagation()中 dZ1中 1 - np.power(A1, 2) 处
dZ1 = np.multiply(np.dot(W2.T, dZ2), 1 - np.power(A1, 2)) # <--
dW1 = np.dot(dZ1, X.T)/m
db1 = np.sum(dZ1, axis=1, keepdims=True)/m
### END CODE HERE ###
grads = {"dW1": dW1,
"db1": db1,
"dW2": dW2,
"db2": db2}
return grads
# GRADED FUNCTION: update_parameters
def update_parameters(parameters, grads, learning_rate = 1.2):
"""
Updates parameters using the gradient descent update rule given above
Arguments:
parameters -- python dictionary containing your parameters
grads -- python dictionary containing your gradients
Returns:
parameters -- python dictionary containing your updated parameters
"""
# Retrieve each parameter from the dictionary "parameters"
### START CODE HERE ### (≈ 4 lines of code)
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
### END CODE HERE ###
# Retrieve each gradient from the dictionary "grads"
### START CODE HERE ### (≈ 4 lines of code)
dW1 = grads["dW1"]
db1 = grads["db1"]
dW2 = grads["dW2"]
db2 = grads["db2"]
## END CODE HERE ###
# Update rule for each parameter
### START CODE HERE ### (≈ 4 lines of code)
W1 -= learning_rate*dW1
b1 -= learning_rate*db1
W2 -= learning_rate*dW2
b2 -= learning_rate*db2
### END CODE HERE ###
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters
4.4 - Integrate parts 4.1, 4.2 and 4.3 in nn_model()
# GRADED FUNCTION: nn_model
def nn_model(X, Y, n_h, num_iterations = 10000, print_cost=False):
"""
Arguments:
X -- dataset of shape (2, number of examples)
Y -- labels of shape (1, number of examples)
n_h -- size of the hidden layer
num_iterations -- Number of iterations in gradient descent loop
print_cost -- if True, print the cost every 1000 iterations
Returns:
parameters -- parameters learnt by the model. They can then be used to predict.
"""
np.random.seed(3)
n_x = layer_sizes(X, Y)[0]
n_y = layer_sizes(X, Y)[2]
# Initialize parameters, then retrieve W1, b1, W2, b2. Inputs: "n_x, n_h, n_y". Outputs = "W1, b1, W2, b2, parameters".
### START CODE HERE ### (≈ 5 lines of code)
parameters = initialize_parameters(n_x, n_h, n_y)
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
### END CODE HERE ###
# Loop (gradient descent)
for i in range(0, num_iterations):
### START CODE HERE ### (≈ 4 lines of code)
# Forward propagation. Inputs: "X, parameters". Outputs: "A2, cache".
A2, cache = forward_propagation(X, parameters)
# Cost function. Inputs: "A2, Y, parameters". Outputs: "cost".
cost = compute_cost(A2, Y, parameters)
# Backpropagation. Inputs: "parameters, cache, X, Y". Outputs: "grads".
grads = backward_propagation(parameters, cache, X, Y)
# Gradient descent parameter update. Inputs: "parameters, grads". Outputs: "parameters".
parameters = update_parameters(parameters, grads)
### END CODE HERE ###
# Print the cost every 1000 iterations
if print_cost and i % 1000 == 0:
print ("Cost after iteration %i: %f" %(i, cost))
return parameters
4.5 Predictions
Reminder: predictions = \(y_{prediction} = \mathbb 1 \text{{activation > 0.5}} = \begin{cases}
1 & \text{if}\ activation > 0.5 \\
0 & \text{otherwise}
\end{cases}\)
As an example, if you would like to set the entries of a matrix X to 0 and 1 based on a threshold you would do: X_new = (X > threshold)
# GRADED FUNCTION: predict
def predict(parameters, X):
"""
Using the learned parameters, predicts a class for each example in X
Arguments:
parameters -- python dictionary containing your parameters
X -- input data of size (n_x, m)
Returns
predictions -- vector of predictions of our model (red: 0 / blue: 1)
"""
# Computes probabilities using forward propagation, and classifies to 0/1 using 0.5 as the threshold.
### START CODE HERE ### (≈ 2 lines of code)
A2, cache = forward_propagation(X, parameters)
predictions = (A2[0] > 0.5) # [ True False True] 而不是 [1 0 1]
### END CODE HERE ###
return predictions
使用模型
# Build a model with a n_h-dimensional hidden layer
# 模型经训练后,最终得到 parameters = W2, b2, W1, b1
parameters = nn_model(X, Y, n_h = 4, num_iterations = 10000, print_cost=True)
# Plot the decision boundary
# 新数据 x 和训练好的参数 parameters 送入 predict() 后, 经过一个前向, 得到A2,
# 再经threshold得到预测结果.
# Print accuracy
predictions = predict(parameters, X)
print ('Accuracy: %d' % float((np.dot(Y,predictions.T) + np.dot(1-Y,1-predictions.T))/float(Y.size)*100) + '%')
4.6 - Tuning hidden layer size (optional/ungraded exercise)
plt.figure(figsize=(16, 32))
hidden_layer_sizes = [1, 2, 3, 4, 5, 10, 20]
for i, n_h in enumerate(hidden_layer_sizes):
plt.subplot(5, 2, i+1)
plt.title('Hidden Layer of size %d' % n_h)
parameters = nn_model(X, Y, n_h, num_iterations = 5000)
plot_decision_boundary(lambda x: predict(parameters, x.T), X, Y)
predictions = predict(parameters, X)
accuracy = float((np.dot(Y,predictions.T) + np.dot(1-Y,1-predictions.T))/float(Y.size)*100)
print ("Accuracy for {} hidden units: {} %".format(n_h, accuracy))
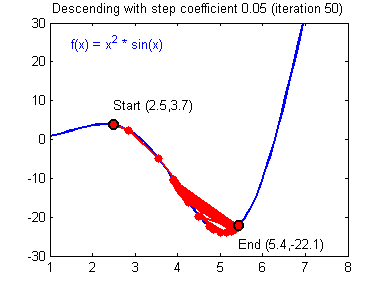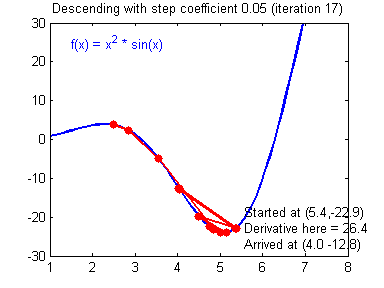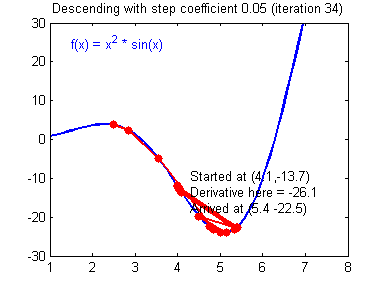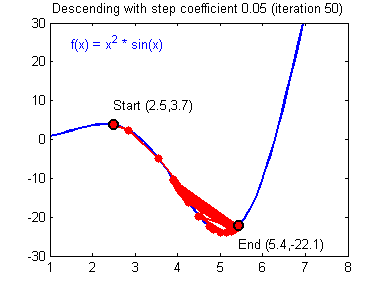
最后顺便把作业里的两个动画(表现学习率设置不合适导致发散,反过来收敛)也弄上来:
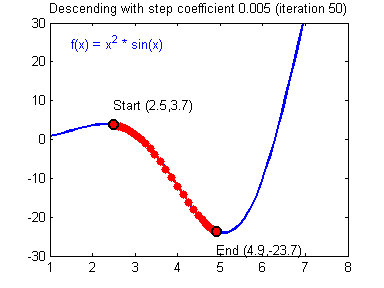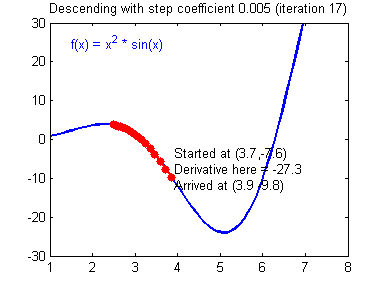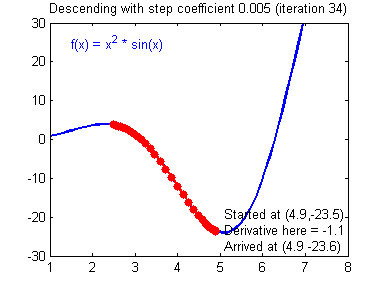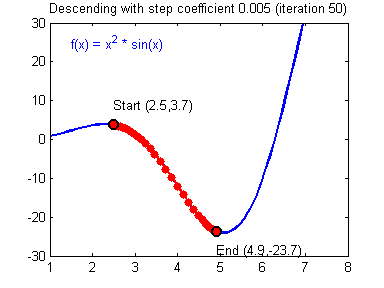
吴恩达深度学习第1课第3周编程作业记录(2分类1隐层nn)的更多相关文章
- 吴恩达深度学习第4课第3周编程作业 + PIL + Python3 + Anaconda环境 + Ubuntu + 导入PIL报错的解决
问题描述: 做吴恩达深度学习第4课第3周编程作业时导入PIL包报错. 我的环境: 已经安装了Tensorflow GPU 版本 Python3 Anaconda 解决办法: 安装pillow模块,而不 ...
- 吴恩达深度学习第2课第2周编程作业 的坑(Optimization Methods)
我python2.7, 做吴恩达深度学习第2课第2周编程作业 Optimization Methods 时有2个坑: 第一坑 需将辅助文件 opt_utils.py 的 nitialize_param ...
- 吴恩达深度学习第2课第3周编程作业 的坑(Tensorflow+Tutorial)
可能因为Andrew Ng用的是python3,而我是python2.7的缘故,我发现了坑.如下: 在辅助文件tf_utils.py中的random_mini_batches(X, Y, mini_b ...
- 吴恩达深度学习第1课第4周-任意层人工神经网络(Artificial Neural Network,即ANN)(向量化)手写推导过程(我觉得已经很详细了)
学习了吴恩达老师深度学习工程师第一门课,受益匪浅,尤其是吴老师所用的符号系统,准确且易区分. 遵循吴老师的符号系统,我对任意层神经网络模型进行了详细的推导,形成笔记. 有人说推导任意层MLP很容易,我 ...
- 【Deeplearning.ai 】吴恩达深度学习笔记及课后作业目录
吴恩达深度学习课程的课堂笔记以及课后作业 代码下载:https://github.com/douzujun/Deep-Learning-Coursera 吴恩达推荐笔记:https://mp.weix ...
- 吴恩达深度学习 反向传播(Back Propagation)公式推导技巧
由于之前看的深度学习的知识都比较零散,补一下吴老师的课程希望能对这块有一个比较完整的认识.课程分为5个部分(粗体部分为已经看过的): 神经网络和深度学习 改善深层神经网络:超参数调试.正则化以及优化 ...
- 深度学习 吴恩达深度学习课程2第三周 tensorflow实践 参数初始化的影响
博主 撸的 该节 代码 地址 :https://github.com/LemonTree1994/machine-learning/blob/master/%E5%90%B4%E6%81%A9%E8 ...
- cousera 吴恩达 深度学习 第一课 第二周 作业 过拟合的表现
上图是课上的编程作业运行10000次迭代后,输出每一百次迭代 训练准确度和测试准确度的走势图,可以看到在600代左右测试准确度为最大的,74%左右, 然后掉到70%左右,再掉到68%左右,然后升到70 ...
- Coursera 吴恩达 深度学习 学习笔记
神经网络和深度学习 Week 1-2 神经网络基础 Week 3 浅层神经网络 Week 4 深层神经网络 改善深层神经网络 Week 1 深度学习的实用层面 Week 2 优化算法 Week 3 超 ...
随机推荐
- HTTP协议的消息头:Content-Type和Accept的作用
一.背景知识 1.概述 Http报头分为通用报头,请求报头,响应报头和实体报头. 请求方的http报头结构:通用报头|请求报头|实体报头 响应方的http报头结构:通用报头|响应报头|实体报头 Acc ...
- ssh整合之五struts和spring整合
1.首先,我们需要先分析一下,我们的spring容器在web环境中,只需要一份就可以了 另外,就是我们的spring容器,要在我们tomcat启动的时候就创建好了(包括其中的spring的对象),怎么 ...
- Apache Flink 分布式执行
Flink 的分布式执行过程包含两个重要的角色,master 和 worker,参与 Flink 程序执行的有多个进程,包括 Job Manager,Task Manager 以及 Job Clien ...
- Ubuntu下安装最新sublime
1. Install the GPG key: wget -qO - https://download.sublimetext.com/sublimehq-pub.gpg | sudo apt-key ...
- beautiful soup
beautiful soup是一个可以从html或者xml文件中提取数据的python库,它能够通过你喜欢的转换器实现惯用的文档导航.查找.修改文档的方式. beautiful soup 会帮你节省数 ...
- PHP多个一维数组合并成二维数组的简易方法
当我们需要进行数组遍历数据的时候,需要将多个一维数组进行二维的转换,方法很简单.如下: <?php $a= array('张三','李四','王五'); $b= array ('23','24' ...
- MSSQL 复制数据 并随机打乱写入
select * into temp from XX order by newid() -- 复制表结构 truncate table XX -- 清空表 SET IDENTITY_INSERT XX ...
- windows汇编环境配置
原文地址 软件下载 需要的软件已经打包,包括dosbox和MASM.如果没有这两个软件可以在下面的地址下载. http://hjwblog.com/game/汇编环境.zip 点击下载 安装dosbo ...
- selenium 设置代理的话,可以使用这种方式,代码是我刚才测试过的,亲测可用
from selenium import webdriver chrome_options = webdriver.ChromeOptions() chrome_options.add_argumen ...
- Java8-Collect收集Stream
Collection, Collections, collect, Collector, Collectos Collection是Java集合的祖先接口. Collections是java.util ...