php 通过header下载中文文件名 压缩包损坏或文件不存在的问题
开发中大家都是使用的utf8编码,昨天遇到一个奇坑,本是一件很小的问题,解决也浪费了个吧小时。废话不多说,植入正题:
文件下载方式:通过header二进制流文件下载
需求: 文件上传保留文件名不变
数据字段file_url值:/public/upload/files/2019/04-29/中文测试包.rar
linux(Ubuntu 18.04.2 LTS )文件目录:/home/wwwroot/web/public/upload/files/2019/04-29
windows10文件目录:D:\web\public\upload\files\2019\04-29\中文测试包.rar
我们先看下,windows下的文件下载:
<?php
$file_name = '/public/upload/files/2019/04-29/中文测试包.rar';
//$file_name = iconv("utf-8","gbk//IGNORE",$file_name); // 特别注意!特别注意!特别注意这里,windows下必须开转码,不然直接文件不存 $file_path = $_SERVER['DOCUMENT_ROOT'] . $file_name;// 比如windows下这里我的是 "D:/web/public/upload/files/2019/04-29/中文测试包.rar"
//判断如果文件存在,则跳转到下载路径
if (!file_exists($file_path)) {
die("文件不存在!");
} $fp = fopen($file_path, "r+") or die('打开文件错误'); //下载文件必须要将文件先打开。写入内存
$file_size = filesize($file_path);
//返回的文件流
Header("Content-type:application/octet-stream");
//按照字节格式返回
Header("Accept-Ranges:bytes");
//返回文件大小
Header("Accept-Length:" . $file_size);
//弹出客户端对话框,对应的文件名
Header("Content-Disposition:attachment;filename=" . substr($file_name, strrpos($file_name, '/') + 1));
//防止服务器瞬间压力增大,分段读取
$buffer = 1024;
while (!feof($fp)) {
$file_data = fread($fp, $buffer);
echo $file_data;
}
fclose($fp); die("下载成功!"); ?>

文件不存在?神马玩意?。同样的代码ubutun生产环境下:
文件下载成功。神马情况?
原因:windows 系统默认字符集是gbk,项目采用的是uft8编码,中文文件名必须转码才能使用file_exists检测文件,不然报找不到文件:
windows下的解决方式就是上面注释的那一段开启:
$file_name = iconv("utf-8","gbk//IGNORE",$file_name); // 特别注意!特别注意!特别注意这里,windows下必须开转码,不然直接文件不存
windows下再次执行后发现下载成功:

那么问题来了。开启后的代码是这样的:
<?php
$file_name = '/public/upload/files/2019/04-29/中文测试包.rar';
$file_name = iconv("utf-8","gbk//IGNORE",$file_name); // 特别注意!特别注意!特别注意这里,windows下必须开转码,不然直接文件不存
$file_path = $_SERVER['DOCUMENT_ROOT'] . $file_name;// 比如windows下这里我的是 "D:/web/public/upload/files/2019/04-29/中文测试包.rar"
//判断如果文件存在,则跳转到下载路径
if (!file_exists($file_path)) {
die("文件不存在!");
} $fp = fopen($file_path, "r+") or die('打开文件错误'); //下载文件必须要将文件先打开。写入内存
$file_size = filesize($file_path);
//返回的文件流
Header("Content-type:application/octet-stream");
//按照字节格式返回
Header("Accept-Ranges:bytes");
//返回文件大小
Header("Accept-Length:" . $file_size);
//弹出客户端对话框,对应的文件名
Header("Content-Disposition:attachment;filename=" . substr($file_name, strrpos($file_name, '/') + 1));
//防止服务器瞬间压力增大,分段读取
$buffer = 1024;
while (!feof($fp)) {
$file_data = fread($fp, $buffer);
echo $file_data;
}
fclose($fp); die("下载成功!");
?>
在ubutun 服务器上我们执行: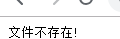
是不是仿佛解决东墙补西墙。ubutun 下字符集可以通过:
cat /usr/share/i18n/SUPPORTED
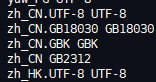
说明系统支持中文字符,不然上传的压缩包怎么会显示:“中文测试包.rar”。
问题描述:linux系统下验证中文文件file_exists不能是中文,所以不能在上面转码成gbk.
那么问题来了: 如何做到兼容性?
我们知道PHP_OS是 php自带的一个内置常量,返回的是服务器端的操作系统标示,值为(WINNT,WIN32等),比如这样:
echo strtoupper(substr(PHP_OS,0,3))==='WIN'?'windows 服务器':'不是 widnows 服务器';
另外一种通过系统分隔符DIRECTORY_SEPARATOR ,这个也是php自带的一个内置常量,用来显示系统分隔符的命令,
不需要任何定义与包含即可直接使用。在windows下路径分隔符是\(当然/在部分系统上也是可以正常运行的),在linux上路径的分隔符是/,
DIRECTORY_SEPARATOR 这个常量存在的意义就是会根据不同的操作系统来显示不同的分隔符。
使用 DIRECTORY_SEPARATOR 判断操作系统类型比如这样:
echo DIRECTORY_SEPARATOR=='\\'?'windows 服务器':'不是 widnows 服务器';
还有一种方式:
PATH_SEPARATOR 也是一个常量,在linux系统中是一个" : "号,Windows上是一个";"号。
使用 PATH_SEPARATOR 判断操作系统类型比如这样:
echo PATH_SEPARATOR==';'?'windows 服务器':'不是 widnows 服务器';
代码兼容性我们可以验证系统类型,对windows下做判断再决定是否转码操作。
这里重点说哈关于下载后文件打开提示“文件损坏”的问题,期初我也遇到。猜测肯定是在读取文件字节流存在数据丢失,也就是没读取完整:
下面看下这段有问题的代码:有兴趣的朋友可以自己思考哈,问题在哪里?这里我就不说了,相信很多朋友也能找到问题点:
<?php
$http_type = ((isset($_SERVER['HTTPS']) && $_SERVER['HTTPS'] == 'on') || (isset($_SERVER['HTTP_X_FORWARDED_PROTO']) && $_SERVER['HTTP_X_FORWARDED_PROTO'] == 'https')) ? 'https://' : 'http://'; $file_name = '/public/upload/files/2019/04-29/中文测试包.rar'; //检测文件是否存在,并且可读
if (!is_file($file_name) && is_readable($file_name)) {
die("文件不存在或不可读!");
} //判断如果文件存在,则跳转到下载路径
$file_path = $_SERVER['DOCUMENT_ROOT'] . $file_name;// 比如windows下这里我的是 "D:/web/public/upload/files/2019/04-29/中文测试包.rar"
//判断如果文件存在,则跳转到下载路径
if (!file_exists($file_path)) {
die("文件不存在!");
} //设置脚本的最大执行时间,设置为0则无时间限制
set_time_limit(0);
ini_set('max_execution_time', '0');
//通过header()发送头信息
//因为不知道文件是什么类型的,告诉浏览器输出的是字节流
header('content-type:application/octet-stream');
//告诉浏览器返回的文件大小类型是字节
header('Accept-Ranges:bytes'); //获得文件大小
//$filesize = filesize($filename);//此方法无法获取到远程文件大小 $header_array = get_headers($http_type . $_SERVER['HTTP_HOST'] . $file_name, true);
$filesize = $header_array['Content-Length'];
//告诉浏览器返回的文件大小
header('Accept-Length:' . $filesize); //告诉浏览器文件作为附件处理并且设定最终下载完成的文件名称
header('content-disposition:attachment;filename=' . substr($file_name, strrpos($file_name, '/') + 1)); //针对大文件,规定每次读取文件的字节数为4096字节,直接输出数据
$buffer = 4096;
$fp = fopen($file_path, 'rb');
//总的缓冲的字节数
$sum_buffer = 0; //只要没到文件尾,就一直读取
while (!feof($fp) && $sum_buffer < $filesize) {
echo fread($fp, $buffer);
$sum_buffer += $buffer;
} //记录下载
die("下载成功!"); ?>

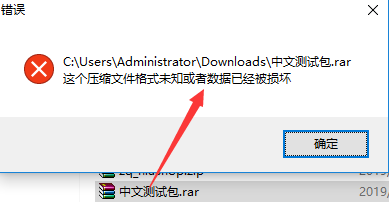
有兴趣的朋友可以找下bug,哈哈
php 通过header下载中文文件名 压缩包损坏或文件不存在的问题的更多相关文章
- LINUNX下PHP下载中文文件名代码
function get_basename($filename){ return preg_replace('/^.+[\\\\\\/]/', '', ...
- springMVC下载中文文件名乱码【转】
//遇到的现象是,下载含有中文文件名的文件时,能获取到文件,但是使用IE正常,使用firefox,chrome文件名却乱码.//既然如此,就区分一下浏览器再返回好了,处理方式如下 //RESTfull ...
- springMVC下载中文文件名乱码【原】
重点就在于添加 "attachment;filename*=utf-8'zh_cn'" + fileName //遇到的现象是,下载含有中文文件名的文件时,能获取到文件,但是使用 ...
- safari下载中文文件名乱码
原因:响应头设置content-disposition,主要遵循 RFC 5987标准. response.setHeader("content-disposition",&quo ...
- java 解决safari下载中文文件名乱码
主要就是在响应头设置content-disposition,主要遵循 RFC 5987标准. response.setHeader("content-disposition",&q ...
- 非Windows系统 如何解压带中文密码和中文文件名的zip压缩文件
数据科学交流群,群号:189158789 ,欢迎各位对数据科学感兴趣的小伙伴的加入! 一.安装unar软件包: Linux(Debian系列): apt install unarLinux(RedHa ...
- IE浏览器下载文件中文文件名乱码问题解决
处理过程 根据IE的F12中的log提示,是因为http头信息中的编码替换了html文件中的编码.我最初的思路是设置Tomcat默认编码,但是我发现我已经在Server.xml中设置过,想到这里我想到 ...
- python用ftplib上传下载中文报错解决
python中的中文编码一直以来都是一个极为头大的问题,经常抛出编码转换的异常,python中的str和unicode到底是一个什么东西呢?在python中提到unicode,一般指的是unicode ...
- 上传文件,经过Zuul,中文文件名乱码解决办法
转载请标明出处: http://blog.csdn.net/forezp/article/details/77170470 本文出自方志朋的博客 问题描述 在项目中又一个上传文件的oss服务,直接调用 ...
随机推荐
- Unix 和· Linux 系统概述
一.Unix 1.Unix 定义 Unix 是一个计算机操作系统,一个用来协调.管理和控制计算机硬件和软件资源的控制程序 '2.Unix 特点 ① 多用户:在同一时刻可以有多个用户同时使用Unix操作 ...
- 读《图解HTTP》有感-(确保WEB安全的HTTPS)
写在前面 该章节分析当前使用的HTTP协议中存在的安全性问题,以及采用HTTPS协议来规避这些可能存在的缺陷 正文 1.HTTP的缺点 1.1.由于HTTP不具备加密功能,所以在通信链路上,报文是以明 ...
- ORC文字识别软件破解版
下载地址:http://pan.baidu.com/s/1bnCiXdl 点击 然后可以免费用了ABBYY了!!
- 深入理解Java NIO
初识NIO: 在 JDK 1. 4 中 新 加入 了 NIO( New Input/ Output) 类, 引入了一种基于通道和缓冲区的 I/O 方式,它可以使用 Native 函数库直接分配堆外内存 ...
- PAT1008:Elevator
1008. Elevator (20) 时间限制 400 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue The highest ...
- redis Web服务器
redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合).zset(sorted set ...
- SSM-MyBatis-06:Mybatis中openSession到底做了什么
------------吾亦无他,唯手熟尔,谦卑若愚,好学若饥------------- 1.找SqlSesionFactory实现类 Ctrl+H:DefaultSqlSessionFactory: ...
- SVN使用指引(Windows)
SVN使用指引(本地服务器为Windows) 原:http://wiki.open.qq.com/wiki/SVN%E4%BD%BF%E7%94%A8%E6%8C%87%E5%BC%95%EF%BC% ...
- Java 线程池(ThreadPoolExecutor)原理分析与使用
在我们的开发中"池"的概念并不罕见,有数据库连接池.线程池.对象池.常量池等等.下面我们主要针对线程池来一步一步揭开线程池的面纱. 使用线程池的好处 1.降低资源消耗 可以重复利用 ...
- Nordic nRF51/nRF52开发流程说明
Nordic nRF51系列包括nRF51822/nRF51422/nRF51802等芯片,nRF52系列包括nRF52832/nRF52840/nRF52810等芯片,硬件工程师可以按照如下流程去评 ...