第1节 storm编程:4、storm环境安装以及storm编程模型介绍
dataSource:数据源,生产数据的东西
spout:接收数据源过来的数据,然后将数据往下游发送
bolt:数据的处理逻辑单元。可以有很多个,基本上每个bolt都处理一部分工作,然后将数据继续往下游的bolt发送
storm不会保存数据,也不会生产数据,只是一个数据的搬运工
tuple:元组的概念,可以理解为一个数组,或者一个集合,里面可以封装很多东西,数据从上游往下游发送,都是封装在tuple里面了
topology:spout与bolt组织到一起,形成一个topology
注意,配置文件比较严格,直接拷贝,尽量不要去手写!
===========================================
1、 storm的安装
三台机器运行服务规划
|
运行服务\机器规划 |
Node01 |
Node02 |
Node03 |
|
Zookeeper版本 |
3.4.5 |
||
|
Zookeeper服务 |
是 |
是 |
是 |
|
Storm版本 |
Apache-storm-1.1.1 |
||
|
Nimbus服务 |
是(leader) |
是 |
是 |
|
Supervisor服务 |
是 |
是 |
是 |
|
IP地址规划 |
192.168.52.100 |
192.168.52.110 |
192.168.52.120 |
3.1三台机器安装zookeeper服务
Node01配置文件修改
修改zoo.cfg
dataDir=/export/servers/zookeeper-3.4.9/zkData/data
dataLogDir=/export/servers/zookeeper-3.4.9/zkData/log
autopurge.snapRetainCount=3
autopurge.purgeInterval=1
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
修改myid
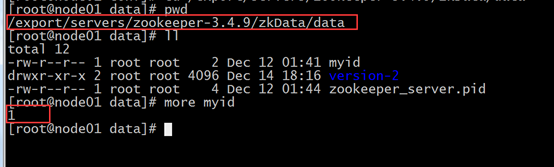
Node02 修改配置文件
修改zoo.cfg
dataDir=/export/servers/zookeeper-3.4.9/zkData/data
dataLogDir=/export/servers/zookeeper-3.4.9/zkData/log
autopurge.snapRetainCount=3
autopurge.purgeInterval=1
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
修改myid
Node03修改配置文件
修改zoo.cfg
dataDir=/export/servers/zookeeper-3.4.9/zkData/data
dataLogDir=/export/servers/zookeeper-3.4.9/zkData/log
autopurge.snapRetainCount=3
autopurge.purgeInterval=1
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
修改myid
三台服务器启动zookeeper服务
bin/zkServer.sh start
三台机器查看zookeeper服务状态
bin/zkServer.sh status
3.2、三台机器安装storm集群
1、上传storm压缩包
2、解压
tar -zxvf apache-storm-1.1.1.tar.gz -C ../servers/
3、修改配置文件
storm.zookeeper.servers:
- "node01"
- "node02"
- "node03"
#
nimbus.seeds: ["node01", "node02", "node03"]
storm.local.dir: "/export/servers/apache-storm-1.1.1/stormdata"
ui.port: 8088 #修改为8089,因为和kafka的8088冲突了
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
4、将storm安装程序分发拷贝到另外两台机器上
scp -r apache-storm-1.1.1/ node02:/export/servers/
scp -r apache-storm-1.1.1/ node03:$PWD
2、 三台机器启动storm服务
Node01 启动相关服务
启动 nimbus进程
nohup bin/storm nimbus >/dev/null 2>&1 &
启动web UI
nohup bin/storm ui >/dev/null 2>&1 &
启动logViewer
nohup bin/storm logviewer >/dev/null 2>&1 &
启动supervisor
nohup bin/storm supervisor >/dev/null 2>&1 &
Node02启动相关服务
nimbus:nohup bin/storm nimbus >/dev/null 2>&1 &
logviewer:nohup bin/storm
logviewer >/dev/null 2>&1 &
supervisor:nohup bin/storm
supervisor >/dev/null 2>&1 &
node03启动相关服务
nimbus:nohup bin/storm
nimbus >/dev/null 2>&1 &
logviewer:nohup bin/storm
logviewer >/dev/null 2>&1 &
supervisor:nohup bin/storm
supervisor >/dev/null 2>&1 &
4、 storm的UI界面管理
访问地址
http://192.168.8.100:8089/index.html 或者
http://node01:8089/
2.
storm的编程模型
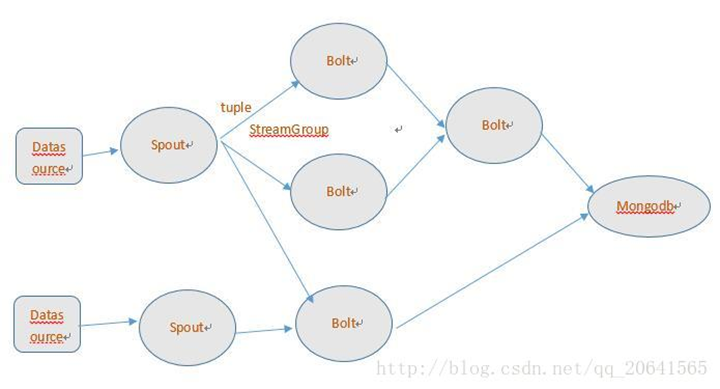
DataSource:外部数据源
Spout:接受外部数据源的组件,将外部数据源转化成Storm内部的数据,以Tuple为基本的传输单元下发给Bolt
Bolt:接受Spout发送的数据,或上游的bolt的发送的数据。根据业务逻辑进行处理。发送给下一个Bolt或者是存储到某种介质上。介质可以是mongodb或mysql,或者其他。
Tuple:Storm内部中数据传输的基本单元,里面封装了一个List对象,用来保存数据。
StreamGrouping:数据分组策略
7种:shuffleGrouping(Random函数),
Non Grouping(Random函数),
FieldGrouping(Hash取模)、
Local or ShuffleGrouping 本地或随机,优先本地。
其中Local or
ShuffleGrouping 是如果分组的时候接收bolt的线程和发送者在一个JVM中默认优先选择一个JVM中的bolt就是local,否则和ShuffleGrouping效果一样。
第1节 storm编程:4、storm环境安装以及storm编程模型介绍的更多相关文章
- kafka和storm集群的环境安装
前言 storm和kafka集群安装是没有必然联系的,我将这两个写在一起,是因为他们都是由zookeeper进行管理的,也都依赖于JDK的环境,为了不重复再写一遍配置,所以我将这两个写在一起.若只需一 ...
- Java SE 9(JDK9)环境安装及交互式编程环境Jshell使用示例
目的 安装JDK 9, 练习Jshell工具的使用, 体验Java的交互式编程环境. 什么是Jshell 其实就是一个命令行工具,安装完JDK9后,可以在bin目录下找到该工具,与Python的解释器 ...
- Web编程:JSP环境安装与配置
Web服务器:Tomcat 数据库服务器:暂时未使用 集成开发环境:eclipse 要运行JSP程序,首先要安装JDK(Java Developer Kit),并且还要配置运行Java程序的环境变量. ...
- Java网络编程:OSI七层模型和TCP/IP模型介绍
OSI(Open System Interconnection),开放式系统互联参考模型 .是一个逻辑上的定义,一个规范,它把网络协议从逻辑上分为了7层.每一层都有相关.相对应的物理设备,比如常规的路 ...
- Storm入门(二)集群环境安装
1.集群规划 storm版本的变更:storm0.9.x storm0.10.x storm1.x上面这些版本里面storm的核心源码是由Java+clojule组成的.storm2.x后期这个 ...
- Storm 学习之路(五)—— Storm编程模型详解
一.简介 下图为Strom的运行流程图,在开发Storm流处理程序时,我们需要采用内置或自定义实现spout(数据源)和bolt(处理单元),并通过TopologyBuilder将它们之间进行关联,形 ...
- Storm 学习之路(三)—— Storm单机版本环境搭建
1. 安装环境要求 you need to install Storm’s dependencies on Nimbus and the worker machines. These are: Jav ...
- Redis安装,mongodb安装,hbase安装,cassandra安装,mysql安装,zookeeper安装,kafka安装,storm安装大数据软件安装部署百科全书
伟大的程序员版权所有,转载请注明:http://www.lenggirl.com/bigdata/server-sofeware-install.html 一.安装mongodb 官网下载包mongo ...
- 第一节:ASP.NET开发环境配置
第一节:ASP.NET开发环境配置 什么是ASP.NET,学这个可以做什么,学习这些有什么内容? ASP.NET是微软公司推出的WEB开发技术. 2002年,推出第一个版本,先后推出ASP.NET2. ...
随机推荐
- 记C++中发现的隐式转换问题
#include <iostream> #include <string> using std::cin; using std::cout; using std::endl; ...
- Linux 目录结构与目录操作
目录结构 Linux的文件系统是采用级层式的树状目录结构,在此结构中的最上层是根目录"/",然后再次目录下再创建其他目录 在Linux系统中,一切皆文件 常见目录作用 / : 所有 ...
- js一位大侠的笔记--转载
js基础 js笔记散记,只是为了方便自己以后可以回看用的: 1.所有用 “点” 的都能 “[]” 代替 odiv.style.color odiv['style'].color odiv['style ...
- 【PAT甲级】1002 A+B for Polynomials (25 分)
题意:给出两个多项式,计算两个多项式的和,并以指数从大到小输出多项式的指数个数,指数和系数. AAAAAccepted code: #include<bits/stdc++.h> usin ...
- 树莓派4B踩坑指南 - (9)安装Git和Docker
安装Git sudo apt-get install wget git-core 安装Docker curl -sSL https://get.docker.com | sh # 树莓派专属脚本福利, ...
- mongodb的remove操作
今天学习mongodb时,打算用db.user.remove()函数把user中的数据都删了,结果没闪成功,提示:remove needs a query.上网查了一下,是因为没有给remove函数传 ...
- pandas help
1. read_csv read_csv方法定义: pandas.read_csv(filepath_or_buffer, sep=', ', delimiter=None, header='infe ...
- 「AHOI2014/JSOI2014」奇怪的计算器
「AHOI2014/JSOI2014」奇怪的计算器 传送门 我拿到这题首先是懵b的,因为感觉没有任何性质... 后来经过同机房dalao的指导发现可以把所有的 \(X\) 放到一起排序,然后我们可以发 ...
- Centos7虚拟环境virtualenv与virtualenvwrapper的安装及基本使用
一.使用虚拟环境的原因 在使用 Python 开发的过程中,工程一多,难免会碰到不同的工程依赖不同版本的库的问题:亦或者是在开发过程中不想让物理环境里充斥各种各样的库,引发未来的依赖灾难.此时,我们需 ...
- 如何查看NXP产品的供货计划?
大的半导体厂商一般会提供每个产品的生命周期计划,NXP的工业级IC一般供货10年,汽车级是15年,具体的时间可以在官网查询得到. 首先,打开NXP官网链接 产品长期供货计划,可以看到以下页面 接着,筛 ...