HiBench成长笔记——(7) 阅读《The HiBench Benchmark Suite: Characterization of the MapReduce-Based Data Analysis》
《The HiBench Benchmark Suite: Characterization of the MapReduce-Based Data Analysis》内容精选
We then evaluate and characterize the Hadoop framework using HiBench, in terms of speed (i.e., job running time), throughput (i.e., the number of tasks completed per minute), HDFS bandwidth, system resource (e.g., CPU, memory and I/O) utilizations, and data access patterns.
关键内容:speed、 throughput、HDFS bandwidth、 system resource、data access patterns
the last one is an enhanced version of the DFSIO benchmark that we have extended to evaluate the aggregated bandwidth delivered by HDFS.
关键内容:evaluate the aggregated bandwidth delivered by HDFS
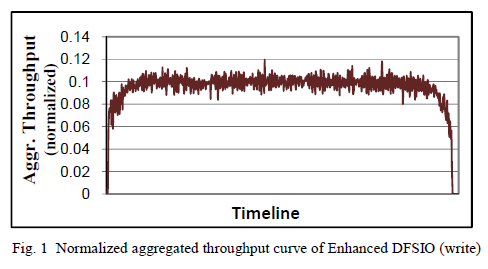
As shown in Fig. 1, the aggregated throughput curve has a warm-up period and a cool-down period where map tasks are launching up and shutting down respectively. Between these two periods, there is a steady period where the aggregated throughput values are stable across different time slots. Therefore, the Enhanced DFSIO workload computes the aggregated HDFS throughput by averaging the throughput value of each time slot in the steady period. In Enhanced DFSIO, when the number of concurrent map tasks at a time slot is above a specified percentage (e.g., 50% is used in our benchmarking) of the total map task slots in the Hadoop cluster, the slot is considered to be in the steady period.
关键内容:warm-up period、cool-down period、steady period、computes the aggregated HDFS throughput by averaging the throughput value of each time slot in the steady period
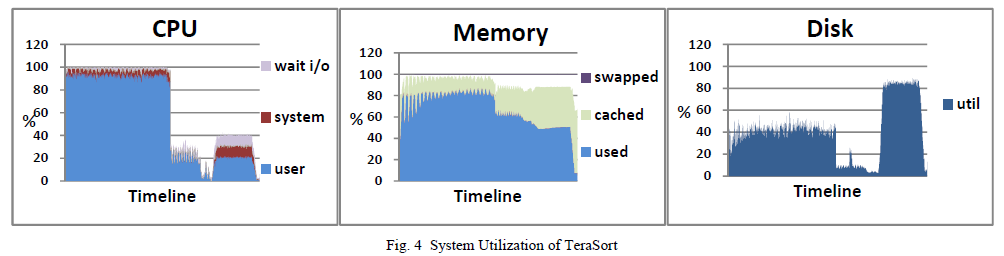
In essence, the TeraSort workload is similar to Sort and therefore is I/O bound in nature. However, we have compressed its shuffle data (i.e., map output) in the experiment so as to minimize the disk and network I/O during shuffle, as shown in Table III. Consequently, TeraSort have very high CPU utilization and moderate disk I/O during the map stage and shuffle phases, and moderate CPU utilization and heavy disk I/O during the reduce phases, as shown in Fig. 4.
关键内容:map stage、shuffle phases、reduce phases、high、moderate、CPU utilization、disk I/O
The best performance (total running time) of Hadoop workloads is usually obtained by accurately estimating the size of the map output, shuffle data and reduce input data, and properly allocating memory buffers to prevent multiple spilling (to disk) of those data.
关键内容:estimating the size of the map output、 shuffle data and reduce input data、allocating memory buffers
HiBench成长笔记——(7) 阅读《The HiBench Benchmark Suite: Characterization of the MapReduce-Based Data Analysis》的更多相关文章
- HiBench成长笔记——(2) CentOS部署安装HiBench
安装Scala 使用spark-shell命令进入shell模式,查看spark版本和Scala版本: 下载Scala2.10.5 wget https://downloads.lightbend.c ...
- HiBench成长笔记——(3) HiBench测试Spark
很多内容之前的博客已经提过,这里不再赘述,详细内容参照本系列前面的博客:https://www.cnblogs.com/ratels/p/10970905.html 创建并修改配置文件conf/spa ...
- HiBench成长笔记——(1) HiBench概述
测试分类 HiBench共计19个测试方向,可大致分为6个测试类别:分别是micro,ml(机器学习),sql,graph,websearch和streaming. 2.1 micro Benchma ...
- HiBench成长笔记——(5) HiBench-Spark-SQL-Scan源码分析
run.sh #!/bin/bash # Licensed to the Apache Software Foundation (ASF) under one or more # contributo ...
- HiBench成长笔记——(4) HiBench测试Spark SQL
很多内容之前的博客已经提过,这里不再赘述,详细内容参照本系列前面的博客:https://www.cnblogs.com/ratels/p/10970905.html 和 https://www.cnb ...
- HiBench成长笔记——(11) 分析源码run.sh
#!/bin/bash # Licensed to the Apache Software Foundation (ASF) under one or more # contributor licen ...
- HiBench成长笔记——(10) 分析源码execute_with_log.py
#!/usr/bin/env python2 # Licensed to the Apache Software Foundation (ASF) under one or more # contri ...
- HiBench成长笔记——(9) 分析源码monitor.py
monitor.py 是主监控程序,将监控数据写入日志,并统计监控数据生成HTML统计展示页面: #!/usr/bin/env python2 # Licensed to the Apache Sof ...
- HiBench成长笔记——(8) 分析源码workload_functions.sh
workload_functions.sh 是测试程序的入口,粘连了监控程序 monitor.py 和 主运行程序: #!/bin/bash # Licensed to the Apache Soft ...
随机推荐
- apache、mysql、php核心、phpmyadmin的安装及相互关联
1.apache的安装 https://blog.csdn.net/ashendove/article/details/52206198 里面的serverName 就是你在服务中 设置的apach ...
- 在visual studio中快速添加代码段
昨天我在网课上,看到老师输入#2之后,立马就出现了一堆代码. 我于是赶紧打开自己的visual studio尝试一下,并没有任何反应. 上网查找,发现visual studio有自定义代码段的功能. ...
- selenium webdriver 实例化浏览器对象
public static FirefoxDriver FFSetting() { System.setProperty("webdriver.firefox.bin", &quo ...
- PAT T1022 Werewolf
暴力搜索加剪枝~ #include<bits/stdc++.h> using namespace std; ; int a[maxn]; bool visit[maxn]; vector& ...
- W - Prime Time 素数判断+前缀和
W - Prime Time 题意:用公式n*n+n+41,判断素数的百分比 #include<iostream> #include<algorithm> #include&l ...
- day11 作业
# 1.编写装饰器,为多个函数加上认证的功能(用户的账号密码来源于文件), # 要求登录成功一次,后续的函数都无需再输入用户名和密码 # FLAG = False # def login(func): ...
- 墨西哥萨卡特卡斯将举行GNOME GUADEC 2020 峰会
导读 GNOME基金会今天宣布了下两届GUADEC(GNOME用户和开发人员欧洲会议)活动的主办城市,这也将是GNOME桌面环境下一版本的代号. 随着GNOME 3.34 “Thessalonik”的 ...
- Codeforces Round #620 (Div. 2) 题解
A. Two Rabbits 思路: 很明显,如果(y-x)%(a+b)==0的话ans=(y-x)/(a+b),否则就为-1 #include<iostream> #include< ...
- 「Violet」蒲公英
「Violet」蒲公英 传送门 区间众数,强制在线. 分块经典题. 像这题一样预处理,然后就直接爆搞,复杂度 \(O(n \sqrt n)\) 参考代码: #include <algorithm ...
- 吴裕雄 Bootstrap 前端框架开发——Bootstrap 表单:表单帮助文本
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...