HiBench成长笔记——(4) HiBench测试Spark SQL
很多内容之前的博客已经提过,这里不再赘述,详细内容参照本系列前面的博客:https://www.cnblogs.com/ratels/p/10970905.html 和 https://www.cnblogs.com/ratels/p/10976060.html
执行脚本
bin/workloads/sql/scan/prepare/prepare.sh
返回信息
[root@node1 prepare]# ./prepare.sh patching args= Parsing conf: /home/cf/app/HiBench-master/conf/hadoop.conf Parsing conf: /home/cf/app/HiBench-master/conf/hibench.conf Parsing conf: /home/cf/app/HiBench-master/conf/spark.conf Parsing conf: /home/cf/app/HiBench-master/conf/workloads/sql/scan.conf probe -.cdh5./lib/hadoop/../../jars/hadoop-mapreduce-client-jobclient--cdh5.14.2-tests.jar start HadoopPrepareScan bench hdfs -.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn fs -rm -r -skipTrash hdfs://node1:8020/HiBench/Scan/Input rm: `hdfs://node1:8020/HiBench/Scan/Input': No such file or directory Pages:, USERVISITS: Submit MapReduce Job: /opt/cloudera/parcels/CDH--.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn jar /home/cf/app/HiBench-master/autogen/target/autogen-7.1-SNAPSHOT-jar-with-dependencies.jar HiBench.DataGen -t hive -b hdfs://node1:8020/HiBench/Scan -n Input -m 8 -r 8 -p 120 -v 1000 -o sequence // :: INFO HiBench.HiveData: Closing hive data generator... finish HadoopPrepareScan bench

执行脚本
bin/workloads/sql/scan/spark/run.sh
返回信息
[root@node1 spark]# ./run.sh patching args= Parsing conf: /home/cf/app/HiBench-master/conf/hadoop.conf Parsing conf: /home/cf/app/HiBench-master/conf/hibench.conf Parsing conf: /home/cf/app/HiBench-master/conf/spark.conf Parsing conf: /home/cf/app/HiBench-master/conf/workloads/sql/scan.conf probe -.cdh5./lib/hadoop/../../jars/hadoop-mapreduce-client-jobclient--cdh5.14.2-tests.jar start ScalaSparkScan bench hdfs -.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn fs -rm -r -skipTrash hdfs://node1:8020/HiBench/Scan/Output rm: `hdfs://node1:8020/HiBench/Scan/Output': No such file or directory Export env: SPARKBENCH_PROPERTIES_FILES=/home/cf/app/HiBench-master/report/scan/spark/conf/sparkbench/sparkbench.conf Export env: HADOOP_CONF_DIR=/etc/hadoop/conf.cloudera.yarn Submit Spark job: /opt/cloudera/parcels/CDH--.cdh5./lib/spark/bin/spark-submit --properties- --executor-cores --executor-memory 4g /home/cf/app/HiBench-master/sparkbench/assembly/target/sparkbench-assembly-7.1-SNAPSHOT-dist.jar ScalaScan /home/cf/app/HiBench-master/report/scan/spark/conf/../rankings_uservisits_scan.hive // :: INFO CuratorFrameworkSingleton: Closing ZooKeeper client. hdfs -.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn fs -du -s hdfs://node1:8020/HiBench/Scan/Output finish ScalaSparkScan bench

查看ResourceManager Web UI
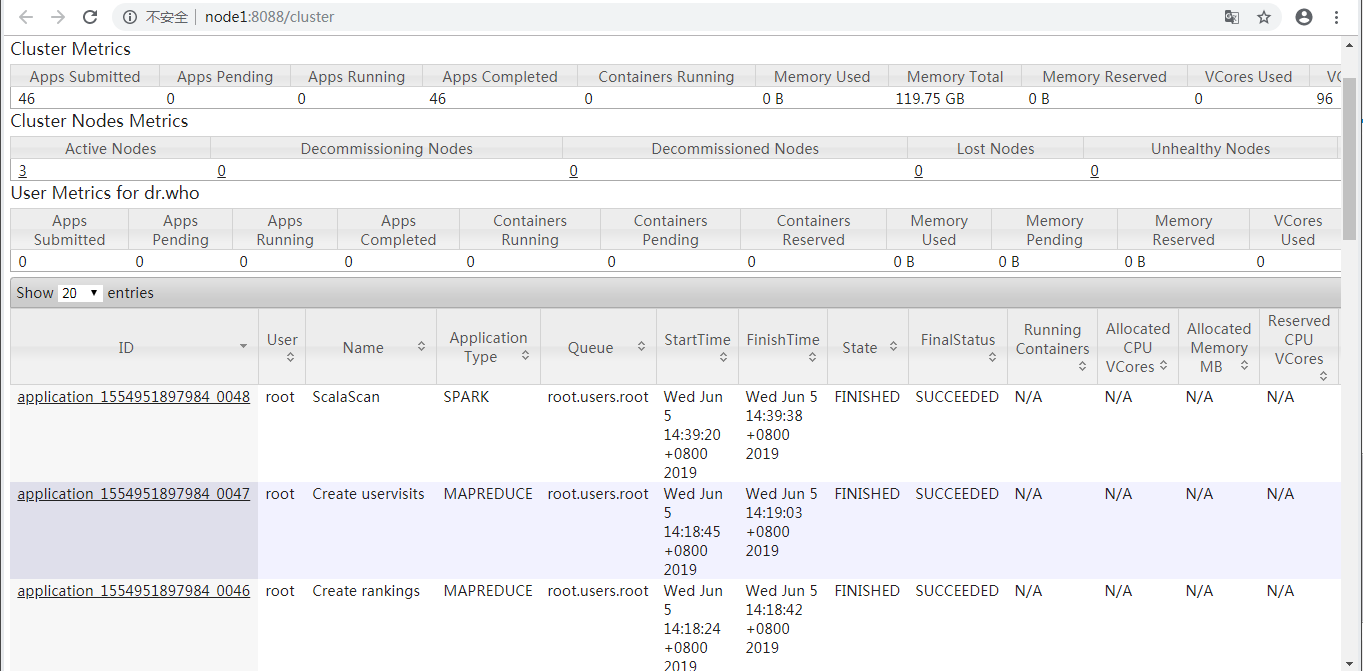
prepare.sh启动了application_1554951897984_0047和application_1554951897984_0046两个MAPREDUCE任务,run.sh启动了application_1554951897984_0048这个Spark任务。
查看(Hadoop)HistoryServer Web UI
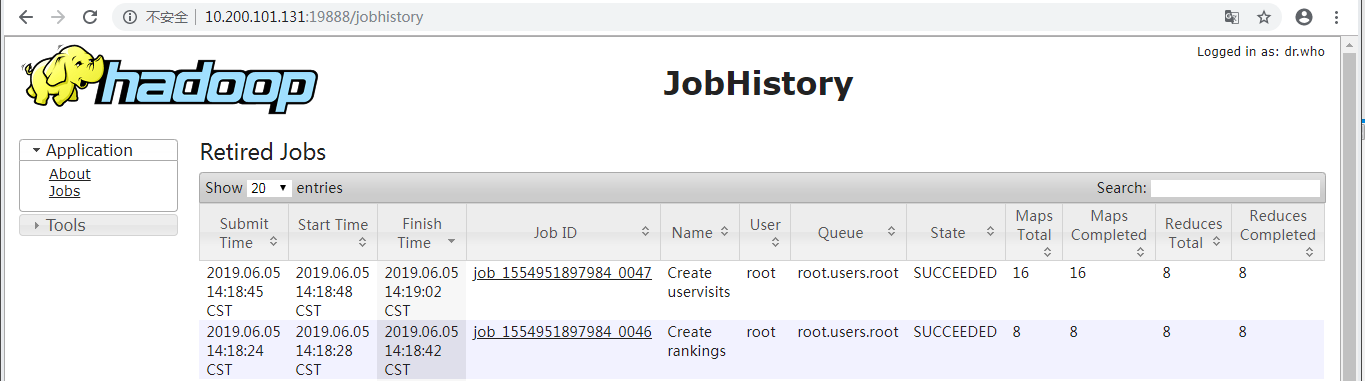
显示了prepare.sh启动的application_1554951897984_0047和application_1554951897984_0046两个MAPREDUCE任务。
查看(Spark) History Server Web UI
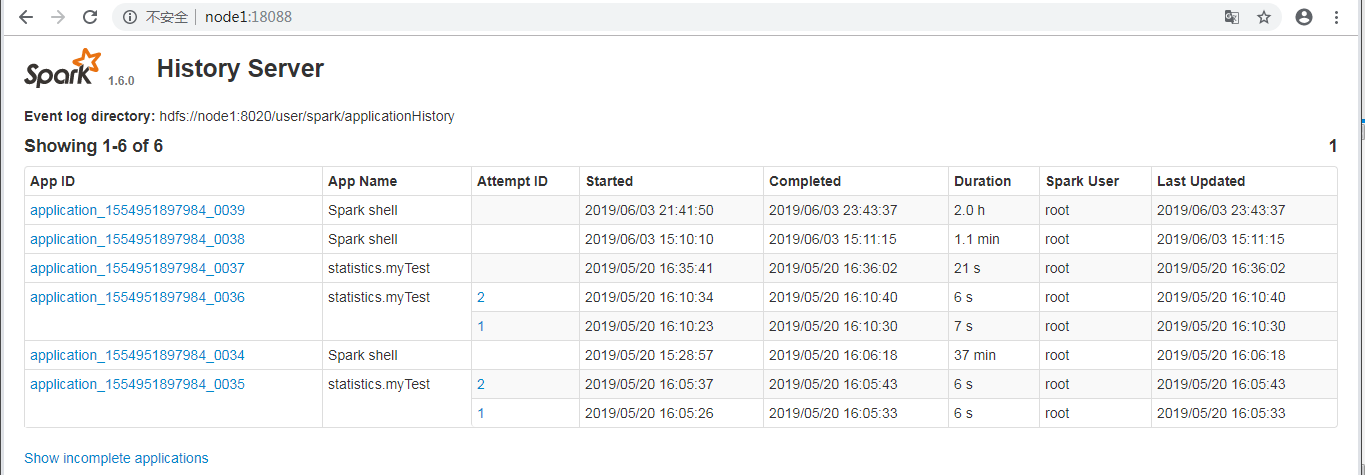
并未显示run.sh启动的application_1554951897984_0048这个Spark任务。
执行脚本
bin/workloads/sql/join/prepare/prepare.sh
返回信息
[root@node1 prepare]# ./prepare.sh patching args= Parsing conf: /home/cf/app/HiBench-master/conf/hadoop.conf Parsing conf: /home/cf/app/HiBench-master/conf/hibench.conf Parsing conf: /home/cf/app/HiBench-master/conf/spark.conf Parsing conf: /home/cf/app/HiBench-master/conf/workloads/sql/join.conf probe -.cdh5./lib/hadoop/../../jars/hadoop-mapreduce-client-jobclient--cdh5.14.2-tests.jar start HadoopPrepareJoin bench hdfs -.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn fs -rm -r -skipTrash hdfs://node1:8020/HiBench/Join/Input rm: `hdfs://node1:8020/HiBench/Join/Input': No such file or directory Pages:, USERVISITS: Submit MapReduce Job: /opt/cloudera/parcels/CDH--.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn jar /home/cf/app/HiBench-master/autogen/target/autogen-7.1-SNAPSHOT-jar-with-dependencies.jar HiBench.DataGen -t hive -b hdfs://node1:8020/HiBench/Join -n Input -m 8 -r 8 -p 120 -v 1000 -o sequence // :: INFO HiBench.HiveData: Closing hive data generator... finish HadoopPrepareJoin bench
执行脚本
bin/workloads/sql/join/spark/run.sh
返回信息
[root@node1 spark]# ./run.sh patching args= Parsing conf: /home/cf/app/HiBench-master/conf/hadoop.conf Parsing conf: /home/cf/app/HiBench-master/conf/hibench.conf Parsing conf: /home/cf/app/HiBench-master/conf/spark.conf Parsing conf: /home/cf/app/HiBench-master/conf/workloads/sql/join.conf probe -.cdh5./lib/hadoop/../../jars/hadoop-mapreduce-client-jobclient--cdh5.14.2-tests.jar start ScalaSparkJoin bench hdfs -.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn fs -du -s hdfs://node1:8020/HiBench/Join/Input hdfs -.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn fs -rm -r -skipTrash hdfs://node1:8020/HiBench/Join/Output rm: `hdfs://node1:8020/HiBench/Join/Output': No such file or directory Export env: SPARKBENCH_PROPERTIES_FILES=/home/cf/app/HiBench-master/report/join/spark/conf/sparkbench/sparkbench.conf Export env: HADOOP_CONF_DIR=/etc/hadoop/conf.cloudera.yarn Submit Spark job: /opt/cloudera/parcels/CDH--.cdh5./lib/spark/bin/spark-submit --properties- --executor-cores --executor-memory 4g /home/cf/app/HiBench-master/sparkbench/assembly/target/sparkbench-assembly-7.1-SNAPSHOT-dist.jar ScalaJoin /home/cf/app/HiBench-master/report/join/spark/conf/../rankings_uservisits_join.hive // :: INFO remote.RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports. finish ScalaSparkJoin bench
执行脚本
bin/workloads/sql/aggregation/prepare/prepare.sh
返回信息
[root@node1 prepare]# ./prepare.sh patching args= Parsing conf: /home/cf/app/HiBench-master/conf/hadoop.conf Parsing conf: /home/cf/app/HiBench-master/conf/hibench.conf Parsing conf: /home/cf/app/HiBench-master/conf/spark.conf Parsing conf: /home/cf/app/HiBench-master/conf/workloads/sql/aggregation.conf probe -.cdh5./lib/hadoop/../../jars/hadoop-mapreduce-client-jobclient--cdh5.14.2-tests.jar start HadoopPrepareAggregation bench hdfs -.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn fs -rm -r -skipTrash hdfs://node1:8020/HiBench/Aggregation/Input rm: `hdfs://node1:8020/HiBench/Aggregation/Input': No such file or directory Pages:, USERVISITS: Submit MapReduce Job: /opt/cloudera/parcels/CDH--.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn jar /home/cf/app/HiBench-master/autogen/target/autogen-7.1-SNAPSHOT-jar-with-dependencies.jar HiBench.DataGen -t hive -b hdfs://node1:8020/HiBench/Aggregation -n Input -m 8 -r 8 -p 120 -v 1000 -o sequence // :: INFO HiBench.HiveData: Closing hive data generator... finish HadoopPrepareAggregation bench
执行脚本
bin/workloads/sql/aggregation/spark/run.sh
返回信息
[root@node1 spark]# ./run.sh patching args= Parsing conf: /home/cf/app/HiBench-master/conf/hadoop.conf Parsing conf: /home/cf/app/HiBench-master/conf/hibench.conf Parsing conf: /home/cf/app/HiBench-master/conf/spark.conf Parsing conf: /home/cf/app/HiBench-master/conf/workloads/sql/aggregation.conf probe -.cdh5./lib/hadoop/../../jars/hadoop-mapreduce-client-jobclient--cdh5.14.2-tests.jar start ScalaSparkAggregation bench hdfs -.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn fs -rm -r -skipTrash hdfs://node1:8020/HiBench/Aggregation/Output rm: `hdfs://node1:8020/HiBench/Aggregation/Output': No such file or directory Export env: SPARKBENCH_PROPERTIES_FILES=/home/cf/app/HiBench-master/report/aggregation/spark/conf/sparkbench/sparkbench.conf Export env: HADOOP_CONF_DIR=/etc/hadoop/conf.cloudera.yarn Submit Spark job: /opt/cloudera/parcels/CDH--.cdh5./lib/spark/bin/spark-submit --properties- --executor-cores --executor-memory 4g /home/cf/app/HiBench-master/sparkbench/assembly/target/sparkbench-assembly-7.1-SNAPSHOT-dist.jar ScalaAggregation /home/cf/app/HiBench-master/report/aggregation/spark/conf/../uservisits_aggre.hive // :: INFO remote.RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports. hdfs -.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn fs -du -s hdfs://node1:8020/HiBench/Aggregation/Output finish ScalaSparkAggregation bench
参考:https://www.cnblogs.com/barneywill/p/10436299.html
HiBench成长笔记——(4) HiBench测试Spark SQL的更多相关文章
- HiBench成长笔记——(1) HiBench概述
测试分类 HiBench共计19个测试方向,可大致分为6个测试类别:分别是micro,ml(机器学习),sql,graph,websearch和streaming. 2.1 micro Benchma ...
- HiBench成长笔记——(3) HiBench测试Spark
很多内容之前的博客已经提过,这里不再赘述,详细内容参照本系列前面的博客:https://www.cnblogs.com/ratels/p/10970905.html 创建并修改配置文件conf/spa ...
- HiBench成长笔记——(6) HiBench测试结果分析
Scan Join Aggregation Scan Join Aggregation Scan Join Aggregation Scan Join Aggregation Scan Join Ag ...
- HiBench成长笔记——(5) HiBench-Spark-SQL-Scan源码分析
run.sh #!/bin/bash # Licensed to the Apache Software Foundation (ASF) under one or more # contributo ...
- HiBench成长笔记——(2) CentOS部署安装HiBench
安装Scala 使用spark-shell命令进入shell模式,查看spark版本和Scala版本: 下载Scala2.10.5 wget https://downloads.lightbend.c ...
- HiBench成长笔记——(8) 分析源码workload_functions.sh
workload_functions.sh 是测试程序的入口,粘连了监控程序 monitor.py 和 主运行程序: #!/bin/bash # Licensed to the Apache Soft ...
- HiBench成长笔记——(7) 阅读《The HiBench Benchmark Suite: Characterization of the MapReduce-Based Data Analysis》
<The HiBench Benchmark Suite: Characterization of the MapReduce-Based Data Analysis>内容精选 We th ...
- HiBench成长笔记——(10) 分析源码execute_with_log.py
#!/usr/bin/env python2 # Licensed to the Apache Software Foundation (ASF) under one or more # contri ...
- HiBench成长笔记——(9) 分析源码monitor.py
monitor.py 是主监控程序,将监控数据写入日志,并统计监控数据生成HTML统计展示页面: #!/usr/bin/env python2 # Licensed to the Apache Sof ...
随机推荐
- [C++基本语法:从菜鸟变成大佬系列,就像1,2,3那么简单](七):C++的修饰符
修饰符是什么? C++允许char,int和double数据类型在它们之前有修饰符.修饰符用于改变基本类型的含义,以便更精确地满足各种情况的需要. 这里列出了数据类型修饰符: signed unsig ...
- arcPy实现要素图层数据的复制(选择特定字段填写属性)
>>> import arcpy>>> fc=r"D:\楚雄州数据\testdata.gdb">>> editor=arcpy ...
- js里用 toLocaleString 实现给数字加三位一逗号间隔(有无小数点都适用)
<input type="hidden" id="totalLandArea" value="<%-info.totalLandArea% ...
- SQL模糊匹配之正则表达式
− 方括号[ ]:指定一个字符.字符串.匹配他们中的任意一个. − 示例1:查询用户名以J或者以M开头的用户信息 − SELECT user_name FROM ecs_ ...
- 吴裕雄 Bootstrap 前端框架开发——Bootstrap 网格系统实例:偏移列
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- sparkRDD:第1节 RDD概述;第2节 创建RDD
RDD的特点: (1)rdd是数据集: (2)rdd是编程模型:因为rdd有很多数据计算方法如map,flatMap,reduceByKey等: (3)rdd相互之间有依赖关系: (4)rdd是可以分 ...
- 【PAT甲级】1015 Reversible Primes (20 分)
题意: 每次输入两个正整数N,D直到N是负数停止输入(N<1e5,1<D<=10),如果N是一个素数并且将N转化为D进制后逆转再转化为十进制后依然是个素数的话输出Yes,否则输出No ...
- 如何启动mac版docker自带的k8s
最近准备好好学习下k8s,为了图方便,直接使用docker集成的k8s,但是网上找了一些教程但都没能一次性成功,只好自己从头跑一遍,顺手写个教程可以方便有类似需求的同学参考. 话不多说,直接上步骤. ...
- css中class后面跟两个类,这两个类用空格隔开
css中class后面跟两个类,这两个类用空格隔开,那么这两个类对这个元素都起作用,如果产生冲突,那么后面的类将替代前面的类.
- 怎么样运行jar
一.制作jar文件 在制作.jar 文件之前你必须先编译好你的.java文件.假设我们的文件目录是c:javamyJavahelloHello.java 现在假设Hello.java的文件内容为: / ...