Mysql大数据量问题与解决
今日格言:了解了为什么,问题就解决了一半。
Mysql 单表适合的最大数据量是多少?
我们说 Mysql 单表适合存储的最大数据量,自然不是说能够存储的最大数据量,如果是说能够存储的最大量,那么,如果你使用自增 ID,最大就可以存储 2^32 或 2^64 条记录了,这是按自增 ID 的数据类型 int 或 bigint 来计算的;如果你不使用自增 id,且没有 id 最大值的限制,如使用足够长度的随机字符串,那么能够限制单表最大数据量的就只剩磁盘空间了。显然我们不是在讨论这个问题。
影响 Mysql 单表的最优最大数量的一个重要因素其实是索引。
我们知道 Mysql 的主要存储引擎 InnoDB 采用 B+树结构索引。(至于为什么 Mysql 选择 b+树而不是其他数据结构来组织索引,不是本文讨论的话题,之后的文章会讲到。)那么 B+树索引是如何影响 Mysql 单表数据量的呢?
B+树
一棵 B+树如下所示:
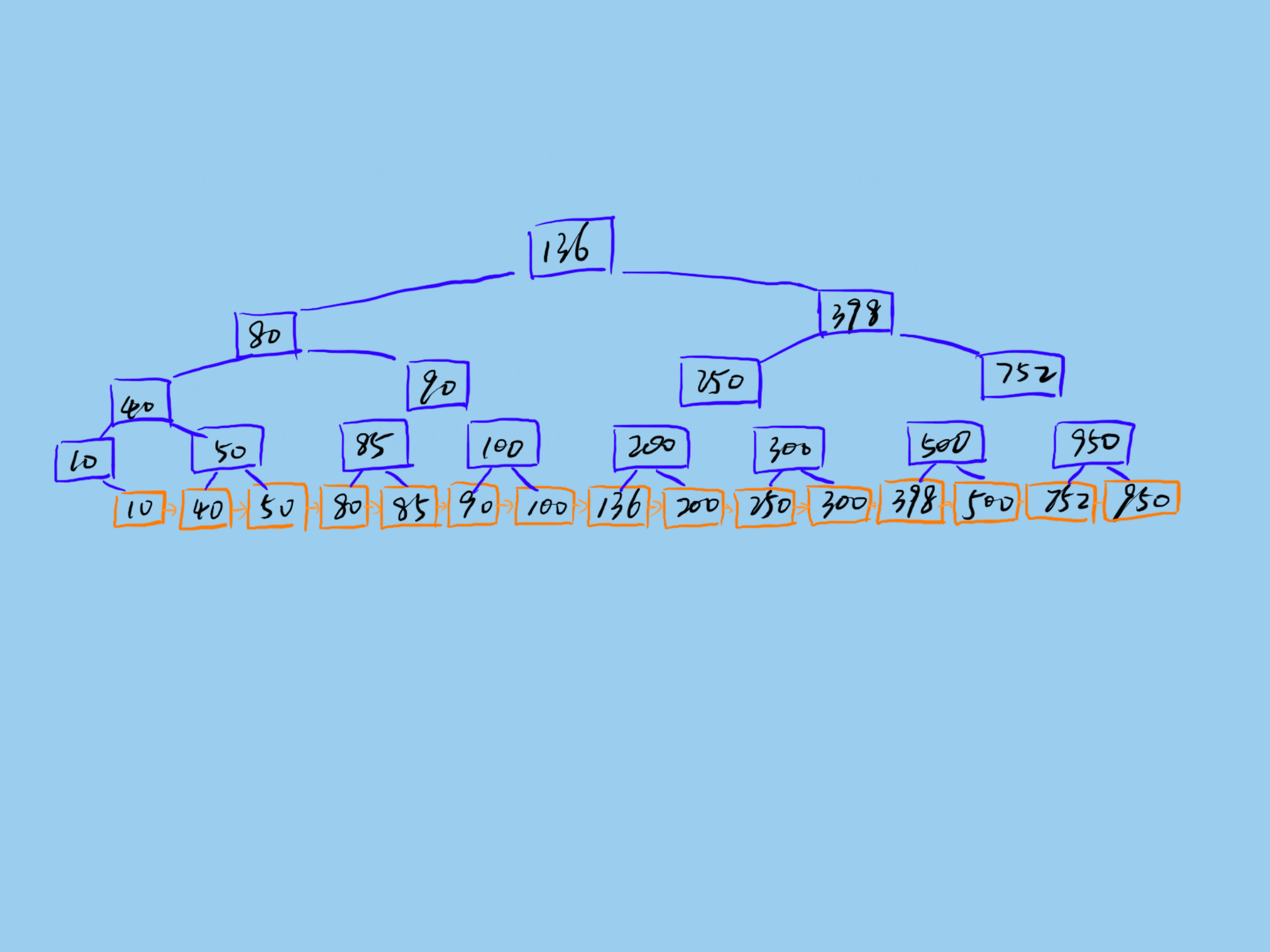
Mysql 的 B+树索引存储在磁盘上,Mysql 每次读取磁盘 Page 的大小是 16KB,为了保证每次查询的效率,需要保证每次查询访问磁盘的次数,一般设计为 2-3 次磁盘访问,再多性能将严重不足。Mysql B+树索引的每个节点需要存储一个指针(8Byte)和一个键值(8Byte)。因此计算16KB/(8B+8B)=1K 16KB 可以存储 1K 个节点,3 次磁盘访问(即 B+树 3 的深度)可以存储 1K _ 1K _ 1K 即 10 亿数据。
如果查询依赖非主键索引,那么还涉及二级索引。这样数据量将更小。
拆分
分而治之——没有什么问题不能通过拆分一次来解决,不行就拆多次。
Mysql 单表存储的数据量有限。一个解决大数据量存储的办法就是分库分表。说白了就是一个数据库一张表放不下那么多数据,那就分多个数据库多张表存储。
拆分可分为垂直拆分和水平拆分。
垂直拆分是按照不同的表(或者 Schema)来切分到不同的数据库(主机)之上,水平拆分则是根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上面或多张相同 Schema 的不同表中。
垂直拆分的最大特点就是规则简单,实施也更为方便,尤其适合各业务之间的耦合度非常低,相互影响很小,业务逻辑非常清晰的系统。在这种系统中,可以很容易做到将不同业务模块所使用的表分拆到不同的数据库中。根据不同的表来进行拆分,对应用程序的影响也更小,拆分规则也会比较简单清晰。
水平拆分与垂直切分相比,相对来说稍微复杂一些。因为要将同一个表中的不同数据拆分到不同的数据库中,对于应用程序来说,拆分规则本身就较根据表名来拆分更为复杂,后期的数据维护也会更为复杂一些。
垂直拆分最直接的就是按领域拆分服务,隔离领域数据库。如此每个库所承担的数据压力就减少了。
水平拆分就是将同一个 Schema 的数据拆分到不同的库或不同的表中,这样每个表的数据量也将减小,查询效率将更高效。水平拆分就涉及到表的分片规则问题。
几种典型的分片规则包括:
- 按照用户 ID 求模,将数据分散到不同的数据库,具有相同数据用户的数据都被分散到一个库中。
- 按照日期,将不同月甚至日的数据分散到不同的库中。
- 按照某个特定的字段求摸,或者根据特定范围段分散到不同的库中。
实现
门面模式——没有什么问题不能通过添加一个中间层来解决。
垂直拆分的一个方案就是在应用层使用多个数据源,按业务访问不同的数据源。另外更好方案其实就是微服务化。按不同的业务领域来拆分微服务,明确领域边界,隔离领域数据库。这样将对数据的存取内聚到独立的服务之中,对外提供统一的接口。在需要同时依赖多个服务时,我们可以通过添加门面应用来组合底层服务的数据,以提供更符合上层业务需求的接口,这些服务往往更接近真实的业务。而底层的服务则是更加内聚的资源服务。
代理模式——没有什么问题不能通过添加一个中间层来解决。
对于水平拆分应该尽量屏蔽拆分带来的数据访问困恼,为了让上层业务无需关心下层数据组织方式。水平拆分往往通过添加一个代理层来做这些事情,代理层对上提供虚拟表,这些虚拟表就像我们在单库上设计的单表一样;代理层对下解析和拆分执行 sql,然后按相应规则在不同的库和表执行相应的 sql 请求,再合并数据,并将合并后的结果返回给上层调用者。
一般代理方式分为如下两种:
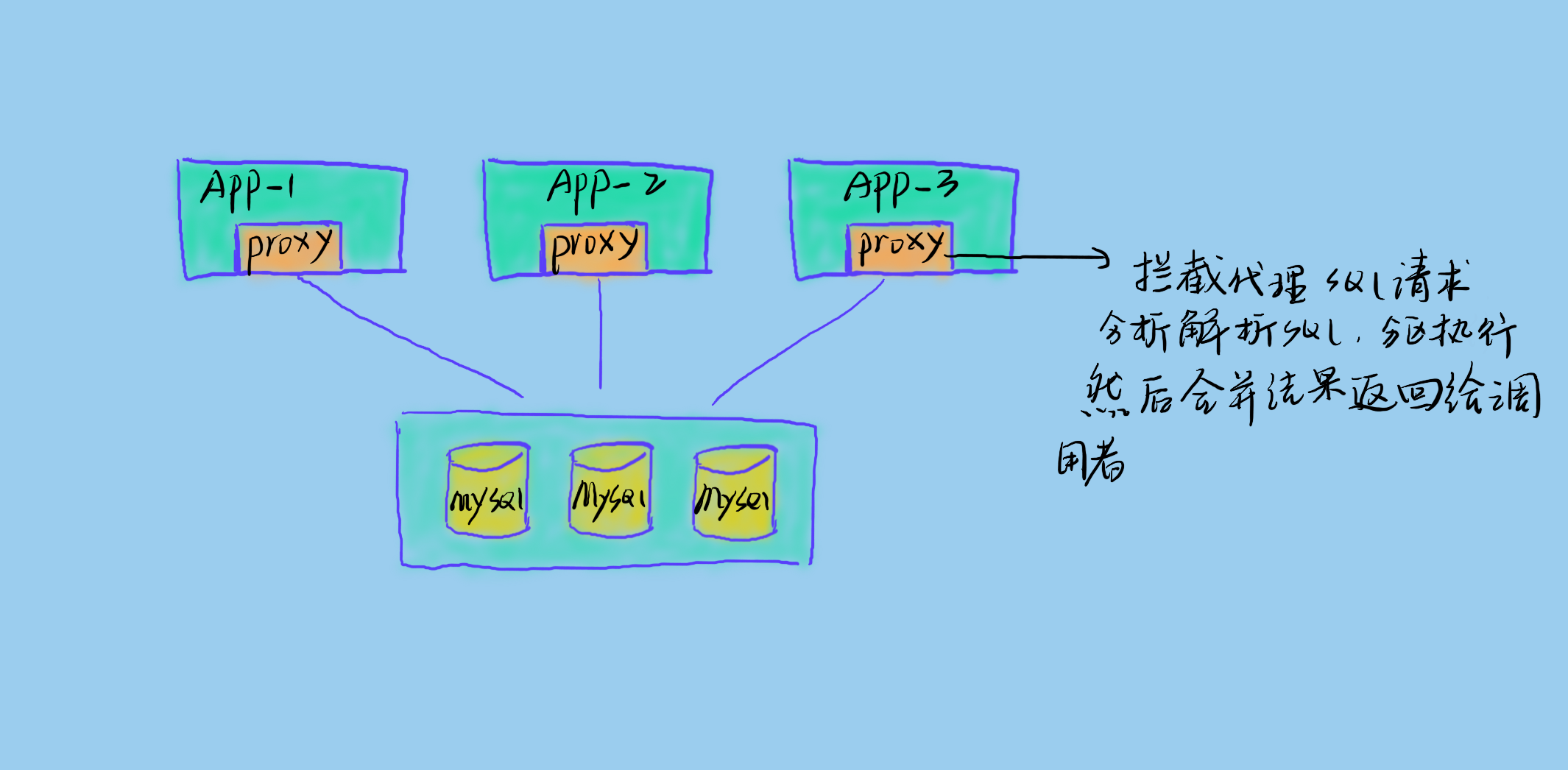
进程内代理
进程内代理即将代理层嵌入到业务服务内部,拦截 sql 请求并做相应的处理。这样的好处是简单,但是侵入性大,且不够灵活。
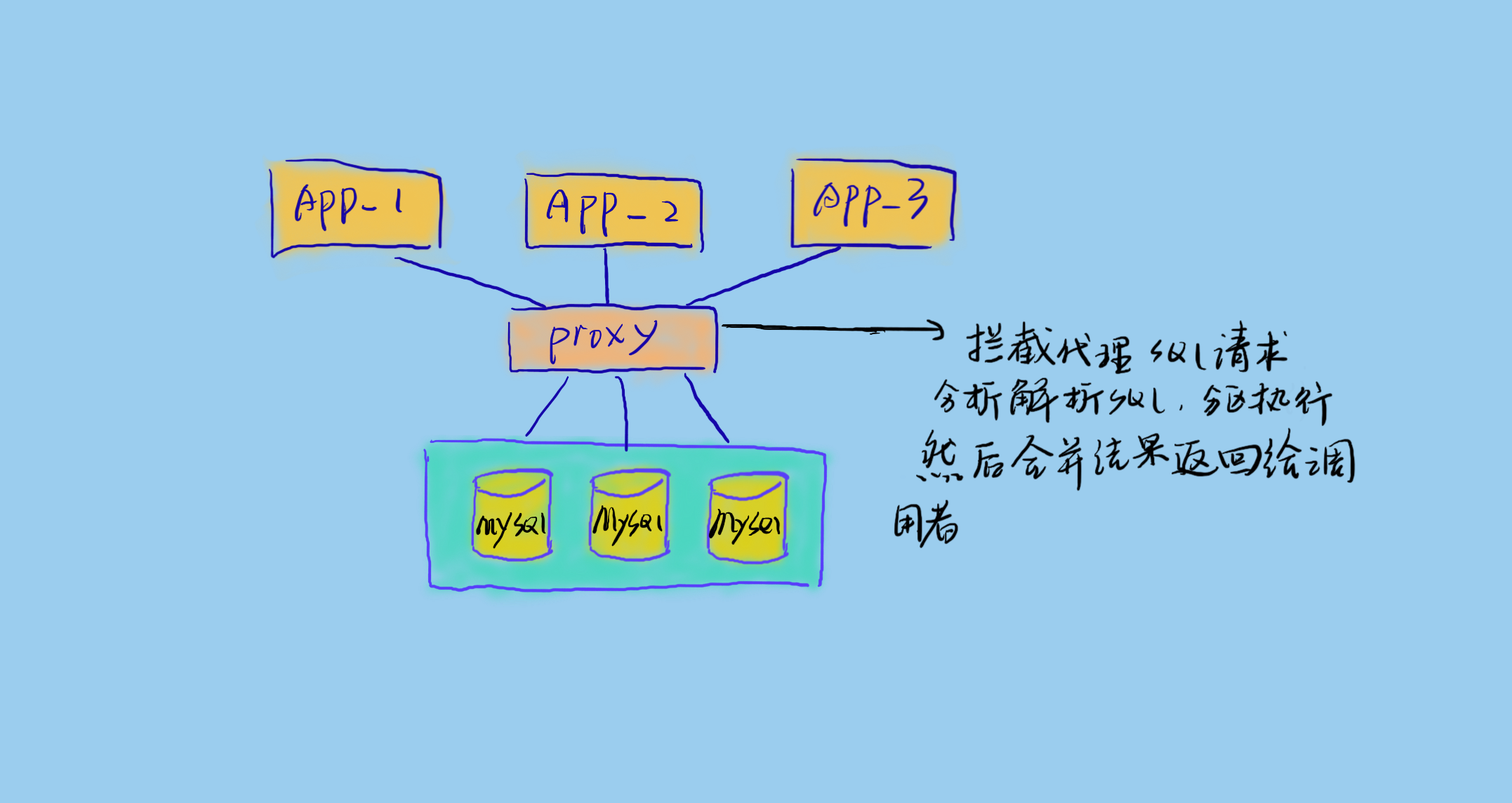
进程外代理
进程外代理即将代理独立成服务,代理真实业务服务和数据库之间的请求。这样是比较复杂的,需要高可用的代理服务架构。但是这样对业务的侵入性低,且易于升级扩展。
问题
分布式事务问题
什么是分布式事务?本地事务的定义就是一系列相关的数据库操作完成后要满足 ACID 四大特性,而分布式事务就是将同一进程的操作放到不同的微服务进程中,即不同微服务应用进程的数据库操作满足事务要求,或者对不同数据库的一系列操作需满足事务要求。
这里就有两个问题需要解决。一个是因为应用的分布式造成的,一个是因为数据库本身的分布式造成的。数据库本身的分布式事务问题一般由数据库自身解决,大多数分布式数据库都可以做到一定的数据一致性保证,如 HBase 保证的强一致性,Cassandra 保证的最终一致性。
应用数据的一致性事务方案我们也可以参考分布式数据库的实现原理来实现。业界也有很多分布式事务的解决思路,如:
- XA 方案
- TCC 方案
- 本地消息表
- 可靠消息最终一致性方案
- 最大努力通知方案
多表 Join 问题
通过分析 Join sql,将 sql 拆分成独立的查询请求,然后分别执行,并将结果合并计算返回给调用者。这个地方会涉及到很多执行优化的问题。
数据统计问题
当数据被分片到不同的数据库或不同的表中时,要对数据做一些全局的或涉及大量数据的统计时便会遇到一些问题。如求 Max,Min,Sum 等聚合问题。如果统计的数据有一定的业务规则,如只会按用户维度去统计,如统计某个用户的订单量,那么对订单表的分片,其实可以采用按用户 id 来分片,如此就可以解决这类统计问题。但是这种方案不通用。很多分片代理服务都需要将 sql 分片到不同的节点上去执行,然后再合并结果返回。
ID 问题
使用分库分表之后,就无法使用 Mysql 的表自增作为 id,因为不同库和表的自增将出现冲突的 id。解决这个问题就需要引入分布式 id 生成技术(将在以后的文章中讲到)。
推荐系列:
列式存储
时间序列数据库(TSDB)初识与选择
十分钟了解 Apache Druid
Apache Druid 底层存储设计
Apache Druid 的集群设计与工作流程
想了解更多数据存储相关知识,请关注我的公众号。

Mysql大数据量问题与解决的更多相关文章
- MySQL大数据量分页查询
mysql大数据量使用limit分页,随着页码的增大,查询效率越低下. 测试实验 1. 直接用limit start, count分页语句, 也是我程序中用的方法: select * from p ...
- 【1】MySQL大数据量分页查询方法及其优化
---方法1: 直接使用数据库提供的SQL语句---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N---适应场景: 适用于数据量较少的情况(元组百/千 ...
- MySQL大数据量分页查询方法及其优化
MySQL大数据量分页查询方法及其优化 ---方法1: 直接使用数据库提供的SQL语句---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N---适 ...
- Mysql 大数据量导入程序
Mysql 大数据量导入程序<?xml:namespace prefix = o ns = "urn:schemas-microsoft-com:office:office" ...
- MySQL 大数据量快速插入方法和语句优化
MySQL大数据量快速插入方法和语句优化是本文我们主要要介绍的内容,接下来我们就来一一介绍,希望能够让您有所收获! INSERT语句的速度 插入一个记录需要的时间由下列因素组成,其中的数字表示大约比例 ...
- mysql大数据量下的分页
mysql大数据量使用limit分页,随着页码的增大,查询效率越低下. 测试实验 1. 直接用limit start, count分页语句, 也是我程序中用的方法: select * from p ...
- MySQL大数据量分页性能优化
mysql大数据量使用limit分页,随着页码的增大,查询效率越低下. 测试实验 1. 直接用limit start, count分页语句, 也是我程序中用的方法: select * from p ...
- MySQL大数据量快速分页实现(转载)
在mysql中如果是小数据量分页我们直接使用limit x,y即可,但是如果千万数据使用这样你无法正常使用分页功能了,那么大数据量要如何构造sql查询分页呢? 般刚开始学SQL语句的时候,会这 ...
- POI读写大数据量excel,解决超过几万行而导致内存溢出的问题
1. Excel2003与Excel2007 两个版本的最大行数和列数不同,2003版最大行数是65536行,最大列数是256列,2007版及以后的版本最大行数是1048576行,最大列数是16384 ...
随机推荐
- (转)解决windows live writer的段首缩进问题
原文地址:http://blog.csdn.net/xiao_wanpeng/article/details/6381799 Windows live writer 默认是没有段首缩进的,并且不能修改 ...
- webStorm ctrl+L 跳转到指定行line eclipes快捷键
webStorm ctrl+L 跳转到指定行line eclipes快捷键
- Layui select下拉框改变之 change 监听事件(转)
在layui中使用 jquery 触发select 的 change事件无效 使用layui.use监听select事件 <select lay-filter="demo" ...
- 附014.Kubernetes Prometheus+Grafana+EFK+Kibana+Glusterfs整合性方案
一 glusterfs存储集群部署 注意:以下为简略步骤,详情参考<附009.Kubernetes永久存储之GlusterFS独立部署>. 1.1 架构示意 略 1.2 相关规划 主机 I ...
- http详解和分析
1.http是什么? http 是一种超文本传输协议原名是这个Hypertext Transfer Protocol -- HTTP/1.1 可以百度查看http的RFC文档编号为RFC-2616 连 ...
- Java-迭代器(新手)
//导入的包.import java.util.ArrayList;import java.util.Collection;import java.util.Iterator;//创建的一个类.pub ...
- python之路---协程
阅读目录 一 引子 二 协程介绍 三 Greenlet模块 四 Gevent模块 引子 之前我们学习了线程.进程的概念,了解了在操作系统中进程是资源分配的最小单位,线程是CPU调度的最小单位.按道理来 ...
- Volatile关键字回顾之线程可见性
java中,volatile关键字有两大作用: 1.保证线程的可见性 2.防止指令重排序 这篇文章主要通过典型案例,体现可见性这一特性. 概念: java中,堆内存是线程共享的.而每个线程,都应该有自 ...
- 洛谷 P5596 【XR-4】题 题解
原题链接 本题只要 推式子 就可以了. \[y^2-x^2=ax + b \] \[a x + x^2 = y^2 - b \] \[4 x^2 + 4 ax = 4 y^2 - 4b \] \[(2 ...
- 《自拍教程51》Python_adb批量生成App版本表格
案例一:版本在软件研发阶段是很重要的, 不同的版本, 已修复的Bug也不一样, 所实现的功能不一样, Android终端产品正式版本发布前,项目经理除了确保系统版本确定无误外, 还会逐个验证所搭载的所 ...