数据挖掘入门系列教程(十二)之使用keras构建CNN网络识别CIFAR10
简介
在上一篇博客:数据挖掘入门系列教程(十一点五)之CNN网络介绍中,介绍了CNN的工作原理和工作流程,在这一篇博客,将具体的使用代码来说明如何使用keras构建一个CNN网络来对CIFAR-10数据集进行训练。
如果对keras不是很熟悉的话,可以去看一看官方文档。或者看一看我前面的博客:数据挖掘入门系列教程(十一)之keras入门使用以及构建DNN网络识别MNIST,在数据挖掘入门系列教程(十一)这篇博客中使用了keras构建一个DNN网络,并对keras的做了一个入门使用介绍。
CIFAR-10数据集
CIFAR-10数据集是图像的集合,通常用于训练机器学习和计算机视觉算法。它是机器学习研究中使用比较广的数据集之一。CIFAR-10数据集包含10 种不同类别的共6w张32x32彩色图像。10个不同的类别分别代表飞机,汽车,鸟类,猫,鹿,狗,青蛙,马,轮船 和卡车。每个类别有6,000张图像
在keras恰好提供了这些数据集。加载数据集的代码如下所示:
from keras.datasets import cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
print(x_train.shape, 'x_train samples')
print(x_test.shape, 'x_test samples')
print(y_train.shape, 'y_trian samples')
print(y_test.shape, 'Y_test samples')
输出结果如下:

训练集有5w张图片,测试集有1w张图片。在\(x\)数据集中,图片是\((32,32,3)\),代表图片的大小是\(32 \times 32\),为3通道(R,G,B)的图片。
展示图片内容
我们可以稍微的展示一下图片的内容,python代码如下所示:
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(12,10))
x, y = 8, 6
for i in range(x*y):
plt.subplot(y, x, i+1)
plt.imshow(x_train[i],interpolation='nearest')
plt.show()
下面就是数据集中的部分图片:

数据集变换
同样,我们需要将类标签进行one-hot编码:
import keras
# 将类向量转换为二进制类矩阵。
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
实际上这一步还有很多牛逼(骚)操作,比如说对数据集进行增强,变换等等,这样都可以在一定程度上提高模型的鲁棒性,防止过拟合。这里我们就怎么简单怎么来,就只对数据集标签进行one-hot编码就行了。
构建CNN网络
构建的网络模型代码如下所示:
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten,Conv2D, MaxPooling2D
# 构建CNN网络
model = Sequential()
# 添加卷积层
model.add(Conv2D(32, (3, 3), padding='same',input_shape=x_train.shape[1:]))
# 添加激活层
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
# 添加最大池化层
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 将上一层输出的数据变成一维
model.add(Flatten())
# 添加全连接层
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(10))
model.add(Activation('softmax'))
# 网络模型的介绍
print(model.summary())
这里解释一下代码:
Conv2D
Conv2D代表2D的卷积层,可能这里会有人问,我的图片不是3通道(RGB)的吗?为什么使用的是Conv2D而不是Conv3D。首先先说明,在Conv2D中的这个“2”代表的是卷积层可以在两个维度(也就是width,length)进行移动。那么同理Conv3D中的“3”代表这个卷积层可以在3个维度进行移动(比如说视频中的width ,length,time)。那么针对RGB这种3通道(channels),卷积过程中输入有多少个通道,则滤波器(卷积核)就有多少个通道。
简单点来说就是:
输入
单色图片的input,是2D, \(w \times h\)
彩色图片的input,是3D,\(w \times h \times channels\)
卷积核filter
单色图片的filter,是2D, \(w \times h\)
彩色图片的filter,是3D, \(w \times h \times channels\)
值得注意的是,卷积之后的结果是二维的。(因为会将3维卷积得到的结果进行相加)
接着继续解释Conv2D的参数:
Conv2D(32, (3, 3), padding='same',input_shape=x_train.shape[1:])
32表示的是输出空间的维度(也就是filter滤波器的输出数量)(3,3)代表的是卷积核的大小strides(这里没有用到):这个代表是滑动的步长。input_shape:输入的维度,这里是(28,28,3)
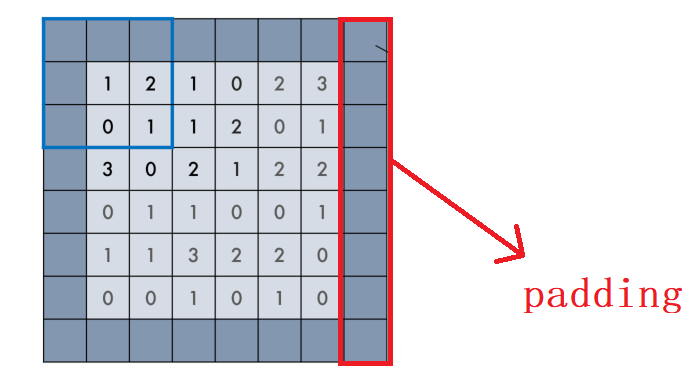
padding在上一篇博客介绍过,在keras中有两个取值:"valid" 或 "same" (大小写敏感)。
- valid padding:不进行任何处理,只使用原始图像,不允许卷积核超出原始图像边界
- same padding:进行填充,允许卷积核超出原始图像边界,并使得卷积后结果的大小与原来的一致
Flatten
Flatten这一层就是为了将多维数据变成一维数据:

构建网络
from keras.optimizers import RMSprop
# 利用 RMSprop 来训练模型。
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy']
)
其他的参数在上两篇博客中已经讲了,就不再赘述。
进行训练评估
这里大家可以根据自己的电脑配置适当调整一下batch_size的大小。
history = model.fit(x_train, y_train,
batch_size=32,
epochs=64,
verbose=1,
validation_data=(x_test, y_test)
)
在i5-10代u,mx250的情况下,训练一轮大概需要27s左右。
训练完成之后,进行评估:
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
结果如下所示:

这个结果可以说的上是一言难尽,
数据挖掘入门系列教程(十二)之使用keras构建CNN网络识别CIFAR10的更多相关文章
- 数据挖掘入门系列教程(二)之分类问题OneR算法
数据挖掘入门系列教程(二)之分类问题OneR算法 数据挖掘入门系列博客:https://www.cnblogs.com/xiaohuiduan/category/1661541.html 项目地址:G ...
- 数据挖掘入门系列教程(十一)之keras入门使用以及构建DNN网络识别MNIST
简介 在上一篇博客:数据挖掘入门系列教程(十点五)之DNN介绍及公式推导中,详细的介绍了DNN,并对其进行了公式推导.本来这篇博客是准备直接介绍CNN的,但是想了一下,觉得还是使用keras构建一个D ...
- 数据挖掘入门系列教程(三)之scikit-learn框架基本使用(以K近邻算法为例)
数据挖掘入门系列教程(三)之scikit-learn框架基本使用(以K近邻算法为例) 简介 scikit-learn 估计器 加载数据集 进行fit训练 设置参数 预处理 流水线 结尾 数据挖掘入门系 ...
- 数据挖掘入门系列教程(八)之使用神经网络(基于pybrain)识别数字手写集MNIST
目录 数据挖掘入门系列教程(八)之使用神经网络(基于pybrain)识别数字手写集MNIST 下载数据集 加载数据集 构建神经网络 反向传播(BP)算法 进行预测 F1验证 总结 参考 数据挖掘入门系 ...
- 数据挖掘入门系列教程(九)之基于sklearn的SVM使用
目录 介绍 基于SVM对MINIST数据集进行分类 使用SVM SVM分析垃圾邮件 加载数据集 分词 构建词云 构建数据集 进行训练 交叉验证 炼丹术 总结 参考 介绍 在上一篇博客:数据挖掘入门系列 ...
- CRL快速开发框架系列教程十二(MongoDB支持)
本系列目录 CRL快速开发框架系列教程一(Code First数据表不需再关心) CRL快速开发框架系列教程二(基于Lambda表达式查询) CRL快速开发框架系列教程三(更新数据) CRL快速开发框 ...
- webpack4 系列教程(十二):处理第三方JavaScript库
教程所示图片使用的是 github 仓库图片,网速过慢的朋友请移步<webpack4 系列教程(十二):处理第三方 JavaScript 库>原文地址.或者来我的小站看更多内容:godbm ...
- 数据挖掘入门系列教程(四)之基于scikit-lean实现决策树
目录 数据挖掘入门系列教程(四)之基于scikit-lean决策树处理Iris 加载数据集 数据特征 训练 随机森林 调参工程师 结尾 数据挖掘入门系列教程(四)之基于scikit-lean决策树处理 ...
- 数据挖掘入门系列教程(四点五)之Apriori算法
目录 数据挖掘入门系列教程(四点五)之Apriori算法 频繁(项集)数据的评判标准 Apriori 算法流程 结尾 数据挖掘入门系列教程(四点五)之Apriori算法 Apriori(先验)算法关联 ...
随机推荐
- 总结一下python的学习路线
1.安装pycharm community编辑器和python 3.7.2解释器的博客链接参考:https://blog.csdn.net/fangye945a/article/details/878 ...
- Light of future-冲刺总结
目录 1.凡事预则立.测试博客的链接 2.包含冲刺日志集合随笔的所有内容 3.描述项目预期计划 7.代码仓库地址.测试文档链接地址.PPT链接地址 归属班级 →2019秋福大软件工程实践Z班 作业要求 ...
- 1036 Boys vs Girls (25分)(水)
1036 Boys vs Girls (25分) This time you are asked to tell the difference between the lowest grade o ...
- Shell脚本的编写及测试
Shell脚本的编写及测试 1.1问题 本例要求两个简单的Shell脚本程序,任务目标如下: 编写一 ...
- New!一只菜鸟的学习之路....
今天拥有了自己的博客,希望在这里记录下自己成长的点点滴滴! 本博客主要记录: 1.在学习过程中遇到的问题及后续的解决办法: 2.技术上的困难,希望路过的大佬指点一二: 3.分享一些实用的技术材料: 4 ...
- 百度找不到,但高手都知道(感觉他们都知道)的一个小细节--BUG调试报告
语言 Batch 前言 以前我一直不明白为什么那么多应用程序在读取"文件路径"作为参数时为什么总是在正式的"文件路径"前要加上个"-f".& ...
- Linux Shell编程,双括号运算符(())
双括号运算符是shell非常强大的扩展. 这里简要介绍两种使用方式: 1.条件判断 跟在if.while.until,for等需要逻辑条件的命令后,进行逻辑判断 if(( expr));then … ...
- MTK Android ROM与RAM的区别
ROM与RAM 简单的说,一个完整的计算机系统是由软件和硬件组成的.其中,硬件部分由中央处理单元CPU(包括运算器和控制器).存储器和输入/输出设备构成.目前个人电脑上使用的主板一般只能支持到1GB的 ...
- wireshark抓包实战(二),第一次抓包
1.选择网卡. 因为wireshark是基于网卡进行抓包的,所以这时候我们必须选取一个网卡进行抓包.选择网卡一般有三种方式 (1)第一种 当我们刚打开软件是会自动提醒您选择,例如: (2)第二种 这时 ...
- 浏览器判断兼容IE
很多时候IE浏览器的兼容性问题总是让人很头疼,或许是样式的或许是脚本的.总之因为IE的低版本问题会引发各种各样的问题出来. function isUnderIE10() {//IE 6,7,8,9 i ...