通过案例对 spark streaming 透彻理解三板斧之二:spark streaming运行机制
本期内容:
1. Spark Streaming架构
2. Spark Streaming运行机制
Spark大数据分析框架的核心部件: spark Core、spark Streaming流计算、GraphX图计算、MLlib机器学习、Spark SQL、Tachyon文件系统、SparkR计算引擎等主要部件.

Spark Streaming 其实是构建在spark core之上的一个应用程序,要构建一个强大的Spark应用程序 ,spark Streaming是一个值得借鉴的参考,spark Streaming涉及多个job交叉配合,基本涉及到了spark的所有的核心组件,精通掌握spark streaming是至关重要的。
Spark Streaming基础概念理解:
1. 离散流:(Discretized Stream ,DStream):这是spark streaming对内部的持续的实时数据流的抽象描述,也即我们处理的一个实时数据流,在spark streaming中对应一个DStream ;
2. 批数据:将实时流时间以时间为单位进行分批,将数据处理转化为时间片数据的批处理;
3. 时间片或者批处理时间间隔:逻辑级别的对数据进行定量的标准,以时间片作为拆分流数据的依据;
4. 窗口长度:一个窗口覆盖的流数据的时间长度。比如说要每隔5分钟统计过去30分钟的数据,窗口长度为6,因为30分钟是batch interval 的6倍;
5. 滑动时间间隔:比如说要每隔5分钟统计过去30分钟的数据,窗口时间间隔为5分钟;
6. input DStream :一个inputDStream是一个特殊的DStream 将spark streaming连接到一个外部数据源来读取数据。
7. Receiver :长时间(可能7*24小时)运行在Excutor之上,每个Receiver负责一个inuptDStream (比如读取一个kafka消息的输入流)。每个Receiver,加上inputDStream 会占用一个core/slot ;
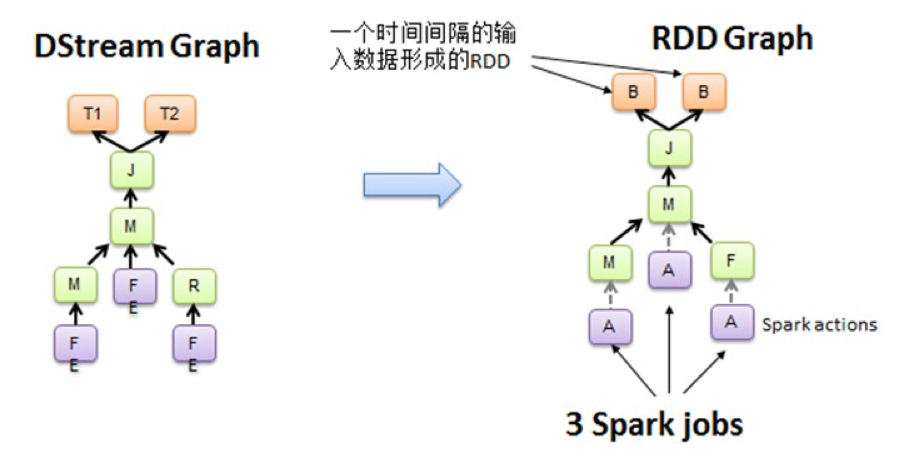
Spark Core处理的每一步都是基于RDD的,RDD之间有依赖关系。下图中的RDD的DAG显示的是有3个Action,会触发3个job,RDD自下向上依赖,RDD产生job就会具体的执行。从DSteam Graph中可以看到,DStream的逻辑与RDD基本一致,它就是在RDD的基础上加上了时间的依赖。RDD的DAG又可以叫空间维度,也就是说整个Spark Streaming多了一个时间维度,也可以成为时空维度。
从这个角度来讲,可以将Spark Streaming放在坐标系中。其中Y轴就是对RDD的操作,RDD的依赖关系构成了整个job的逻辑,而X轴就是时间。随着时间的流逝,固定的时间间隔(Batch Interval)就会生成一个job实例,进而在集群中运行。

对于Spark Streaming来说,当不同的数据来源的数据流进来的时候,基于固定的时间间隔,会形成一系列固定不变的数据集或event集合(例如来自flume和kafka)。而这正好与RDD基于固定的数据集不谋而合,事实上,由DStream基于固定的时间间隔行程的RDD Graph正是基于某一个batch的数据集的。
从上图中可以看出,在每一个Batch上,空间维度的RDD依赖关系都是一样的,不同的是这个五个Batch流入的数据规模和内容不一样,所以说生成的是不同的RDD依赖关系的实例,所以说RDD的Graph脱胎于DStream的Graph,也就是说DStream就是RDD的模板,不同的时间间隔,生成不同的RDD Graph实例。
从源码解读DStream :

从这里可以看出,DStream就是Spark Streaming的核心,就想Spark Core的核心是RDD,它也有dependency和compute。更为关键的是下面的代码:

这是一个HashMap,以时间为key,以RDD为Value,这也正应证了随着时间流逝,不断的生成RDD,产生依赖关系的job,并通过JbScheduler在集群上运行。再次验证了DStream就是RDD的模版。
DStream可以说是逻辑级别的,RDD就是物理级别的,DStream所表达的最终都是通过RDD的转化实现的。前者是更高级别的抽象,后者是底层的实现。DStream实际上就是在时间维度上对RDD集合的封装,DStream与RDD的关系就是随着时间流逝不断的产生RDD,对DStream的操作就是在固定时间上操作RDD。
总结:
在空间维度上的业务逻辑作用于DStream,随着时间的流逝,每个Batch Interval形成了具体的数据集,产生了RDD,对RDD进行Transform操作,进而形成了RDD的依赖关系RDD DAG,形成Job。然后JobScheduler根据时间调度,基于RDD的依赖关系,把作业发布到Spark Cluster上去运行,不断的产生Spark作业。
通过案例对 spark streaming 透彻理解三板斧之二:spark streaming运行机制的更多相关文章
- 通过案例对 spark streaming 透彻理解三板斧之一: spark streaming 另类实验
本期内容 : spark streaming另类在线实验 瞬间理解spark streaming本质 一. 我们最开始将从Spark Streaming入手 为何从Spark Streaming切入 ...
- 通过案例对 spark streaming 透彻理解三板斧之三:spark streaming运行机制与架构
本期内容: 1. Spark Streaming Job架构与运行机制 2. Spark Streaming 容错架构与运行机制 事实上时间是不存在的,是由人的感官系统感觉时间的存在而已,是一种虚幻的 ...
- 通过案例对SparkStreaming透彻理解三板斧之二
本节课主要从以下二个方面来解密SparkStreaming: 一.解密SparkStreaming运行机制 二.解密SparkStreaming架构 SparkStreaming运行时更像SparkC ...
- 通过案例对SparkStreaming透彻理解三板斧之一
本节课通过二个部分阐述SparkStreaming的理解: 一.解密SparkStreaming另类在线实验 二.瞬间理解SparkStreaming本质 Spark源码定制班主要是自己做发行版.自己 ...
- 通过案例对SparkStreaming透彻理解三板斧之三
本课将从二方面阐述: 一.解密SparkStreaming Job架构和运行机制 二.解密SparkStreaming容错架构和运行机制 一切不能进行实时流处理的数据都将是无效的数据.在流处理时代,S ...
- spark 源码分析之十二 -- Spark内置RPC机制剖析之八Spark RPC总结
在spark 源码分析之五 -- Spark内置RPC机制剖析之一创建NettyRpcEnv中,剖析了NettyRpcEnv的创建过程. Dispatcher.NettyStreamManager.T ...
- Spark大数据处理 之 从WordCount看Spark大数据处理的核心机制(1)
大数据处理肯定是分布式的了,那就面临着几个核心问题:可扩展性,负载均衡,容错处理.Spark是如何处理这些问题的呢?接着上一篇的"动手写WordCount",今天要做的就是透过这个 ...
- spark 源码分析之十八 -- Spark存储体系剖析
本篇文章主要剖析BlockManager相关的类以及总结Spark底层存储体系. 总述 先看 BlockManager相关类之间的关系如下: 我们从NettyRpcEnv 开始,做一下简单说明. Ne ...
- JavaWeb三大组件——过滤器的运行机制理解
过滤器Filter 文章前言:本文侧重实用和理解. 一.过滤器的概念. lFilter也称之为过滤器,它是Servlet技术中最实用的技术,WEB开发人员通过Filter技术,对web服务器管理的所有 ...
随机推荐
- iOS开发:XCTest单元测试(附上一个单例的测试代码)
测试驱动开发并不是一个很新鲜的概念了.在我最开始学习程序编写时,最喜欢干的事情就是编写一段代码,然后运行观察结果是否正确.我所学习第一门语言是c语言,用的最多的是在算法设计上,那时候最常做的事情就是编 ...
- Visual Studio 2008打开vs2010解决方案的方法
一个朋友遇到了个问题:用visual studio 2008软件,无法打开一个asp.net网站的sln解决方案.如下图,原因是此解决方案由vs2010生成的,必须由vs2010运行程序打开. 这样一 ...
- LeetCode189——Rotate Array
Rotate an array of n elements to the right by k steps. For example, with n = 7 and k = 3, the array ...
- Multiply game_线段树
Problem Description Tired of playing computer games, alpc23 is planning to play a game on numbers. B ...
- python3.2 + PyQt4界面开发hello world
需要先安装python3.2 然后安装python3.2对应的PyQt4界面库版本 import sys from PyQt4 import QtGui , QtCore app = QtGui.QA ...
- linux C 获取当前目录的实现(转-Blossom)
linux C 获取当前目录的实现: //获取当前目录#include <stdlib.h>#include <stdio.h>#include <string.h> ...
- uva 11582
#include <iostream> #include <map> #include <cmath> #include <vector> #inclu ...
- Lua与C++相互调用
{--1.环境--} 为了快速入手,使用了小巧快速的vc++6.0编译器 以及在官网下载了Lua安装包..官网地址{--http://10.21.210.18/seeyon/index.jsp--} ...
- JavaScript tasks, microtasks, queues and schedules
最近做的项目中,涉及到了JavaScript中Promise的用法,于是做了一点测试,发现没有想象中的那么简单,水很深,所以找来N先生(我的Mentor),想得到专业的指导.N先生也不尽知,但N先生查 ...
- MapReduce 2简介
在Hadoop 1.0版本中,mapred.job.tracker决定了执行MapReduce程序的方式,若设置为local,则使用本地的作业运行器,若设置为主机:端口(eb179:9001),则该配 ...