zookeeper集群的搭建以及hadoop ha的相关配置
1、环境
centos7 hadoop2.6.5 zookeeper3.4.9 jdk1.8
master作为active主机,data1作为standby备用机,三台机器均作为数据节点,yarn资源管理器在master上开启,在data1上备用,data1上开启历史服务器
主要参考见下表
| master | 192.168.1.215 | Namenode DataNode QuorumPeerMain ZKFC JournalNode ResourceManager NodeManager |
| data1 | 192.168.1.218 | Namenode DataNode QuorumPeerMain ZKFC JournalNode ResourceManager NodeManager JobHistoryServer ApplicationHistoryServer |
| data2 | 192.168.1.219 |
DataNode QuorumPeerMain JournalNode NodeManager |
2、zookeeper集群的搭建
安装到/usr/Apache目录下,所有者与所属组均为hadoop
tar -zxvf zookeeper-3.4..tar.gz -C /usr/Apache/
ln -s zookeeper-3.4./ zookeeper
cd zookeeper/conf
# 配置文件
cp zoo_sample.cfg zoo.cfg
# 编辑zoo.cfg的内容
# The number of milliseconds of each tick
tickTime=
# The number of ticks that the initial
# synchronization phase can take
initLimit=
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/usr/Apache/zookeeper/data
dataLogDir=/usr/Apache/zookeeper/data/log
# the port at which the clients will connect
clientPort=
# the maximum number of client connections.
# increase this if you need to handle more clients
maxClientCnxns=
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
autopurge.snapRetainCount=
# Purge task interval in hours
# Set to "" to disable auto purge feature
autopurge.purgeInterval=
#
server.1=master:2888:3888
server.2=data1:2888:3888
server.3=data2:2888:3888
一般采用默认值,重点是标蓝的地方。
数据的路径单独设,将日志分开,并且,不要放到默认的tmp文件夹下面,因为这个会定期删除
dataDir=/usr/Apache/zookeeper/data dataLogDir=/usr/Apache/zookeeper/data/log
将快照打开,并且设置autopurge.purgeInterval=1,与上面的不同,快照需要定期删除
增大客户端的连接数量maxClientCnxns=
先安装到master下面,之后进行分发
scp -r zookeeper-3.4. data1:usr/Apache/
scp -r zookeeper-3.4. data2:usr/Apache/
# 注意所属组与所有者
chown -R hadoop:hadoop zookeeper
# 分别在三台机器的/usr/Apache/zookeeper/data目录下建立myid文件,分别写入数字1、2、3,这点很重要
cd /usr/Apache/zookeeper/data/
touch myid
# 三台机器分别启动
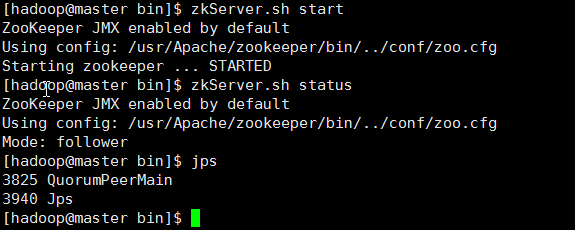
zkServer.sh start
# 查看状态
zkServer.sh status
# 最后,检查,关闭一个看是否自动选举
3、hadoop以及yarn的高可用配置
先前安装过,主要是配置文件的修改,注意,如果不重新安装,需要删除一些文件 rm -rf tmp/* data/nn/* data/jn/* data/dn/* data/dn/* logs/*
上面的data/nn data/jn data/dn data/dn 是自己建的一些文件,用于节点数据的存放。
重新安装也不麻烦,此处选择重新安装,目录选择/usr/Apache,所有者与所属组均为hadoop,环境变量如下:
更改环境变量,hadoop用户下面的~/.bashrc文件
export HADOOP_HOME=/usr/Apache/hadoop
export ZOOKEEPER_HOME=/usr/Apache/zookeeper
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export CLASSPATH=.:$HADOOP_HOME/lib:$CLASSPATH
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin
# 之后
source ~/.bashrc
下面关键看配置
1> core-site.xml
<configuration>
<!--缓存文件存储的路径,可以这样写file:/opt/mdisk/disk02/data/tmp,file:/opt/mdisk/disk01/data/tmp-->
<!--如果挂载多个数据盘,用逗号分开-->
<!--配置缓存文件的目录,注意另建新的文件夹tmp,不要在hadoop/tmp下,因为会定期删除-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/Apache/hadoop/data/tmp</value>
<description>A base for other temporary directories.</description>
</property> <!--指定nameservice的名称,自定义,但后面必须保持一致-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://nscluster</value>
</property> <!-- 编辑日志文件存储的路径,这个也可以放到hdfs-site.xml中 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/Apache/hadoop/data/jn</value>
</property> <!--文件读写缓存大小,此处为128kb-->
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property> <!--指定zookeeper地址,配置HA时需要,这个也可以放到hdfs-site.xml中-->
<!--<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,data1:2181,data2:2181</value>
</property>--> <!--以下不是必须的-->
<!--配置hdfs文件被永久删除前保留的时间(单位:分钟),默认值为0表明垃圾回收站功能关闭-->
<!--<property>
<name>fs.trash.interval</name>
<value>0</value>
</property>--> <!--指定可以在任何IP访问-->
<!--<property>
<name>hadoop.proxyuser.hduser.hosts</name>
<value>*</value>
</property>--> <!--指定所有用户可以访问-->
<!--<property>
<name>hadoop.proxyuser.hduser.groups</name>
<value>*</value>
</property>-->
</configuration>
这里要注意hadoop.tmp.dir这个属性,上面的注释也已经说了,一定不要放到暂时的hadoop/tmp中,而要放到永久的文件夹中,否则namenode的启动可能遇到问题。
上面一些注释掉的属性不是必须的,下面一样。
2> hdfs-site.xml
注意下面的nscluster是自定义的名称,并且被应用于多个属性中,部署使用时更改样式
<configuration> <!--指定hdfs元数据存储的路径-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/Apache/hadoop/data/nn</value>
</property> <!--指定hdfs数据存储的路径-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/Apache/hadoop/data/dn</value>
</property> <!--开启WebHDFS功能(基于REST的接口服务)-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property> <!-- 数据备份的个数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property> <!--关闭权限验证 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property> <!--DateNode上的服务线程数,处理rpc,默认为10,可以调大-->
<property>
<name>dfs.datanode.handler.count</name>
<value>200</value>
</property> <!--文件操作的线程数,如果处理文件有很多,则调大,建议值8192-->
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>8192</value>
</property> <!--不用的数据节点,添加到excludes文件,方法同slaves文件,之后执行hadoop dfsadmin -refreshNodes命令-->
<property>
<name>dfs.hosts.exclude</name>
<value>/usr/Apache/hadoop/etc/hadoop/excludes</value>
</property> <!--以下为ha的相关配置-->
<!-- 指定hdfs的nameservice的名称为nscluster,务必与core-site.xml中的逻辑名称相同 -->
<property>
<name>dfs.nameservices</name>
<value>nscluster</value>
</property> <!-- 指定nscluster的两个namenode的名称,分别是nn1,nn2,注意后面的后缀.nscluster,这个是自定义的,如果逻辑名称为nsc,则后缀为.nsc,下面一样 -->
<property>
<name>dfs.ha.namenodes.nscluster</name>
<value>nn1,nn2</value>
</property> <!-- 配置nn1,nn2的rpc通信 端口 -->
<property>
<name>dfs.namenode.rpc-address.nscluster.nn1</name>
<value>master:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.nscluster.nn2</name>
<value>data1:9000</value>
</property> <!-- 配置nn1,nn2的http访问端口 -->
<property>
<name>dfs.namenode.http-address.nscluster.nn1</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.nscluster.nn2</name>
<value>data1:50070</value>
</property> <!-- 指定namenode的元数据存储在journalnode中的路径 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;data1:8485;data2:8485/nscluster</value>
</property> <!-- 开启失败故障自动转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property> <!-- 配置失败自动切换的方式 -->
<property>
<name>dfs.client.failover.proxy.provider.nscluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property> <!-- 配置zookeeper地址,如果已经在core-site.xml中配置了,这里不是必须的 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,data1:2181,data2:2181</value>
</property> <!-- 配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property> <!-- 指定秘钥的位置 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property> <!--配置sshfence隔离机制超时时间-->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property> <!--保证数据恢复-->
<!--<property>
<name>dfs.journalnode.http-address</name>
<value>0.0.0.0:8480</value>
</property>-->
<!--<property>
<name>dfs.journalnode.rpc-address</name>
<value>0.0.0.0:8485</value>
</property> -->
</configuration>
3> mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property> <!--配置 MapReduce JobHistory Server 地址 ,默认端口10020-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
</property> <!--配置 MapReduce JobHistory Server web ui 地址, 默认端口19888-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
</property> <!--不用的数据节点,添加到excludes文件,之后执行hadoop dfsadmin -refreshNodes命令,-->
<!--协同hdfs-site.xml中的dfs.hosts.exclude属性-->
<property>
<name>mapred.hosts.exclude</name>
<value>/usr/Apache/hadoop/etc/hadoop/excludes</value>
</property> <property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property> </configuration>
注意上面0.0.0.0:19888这种写法,不能简单的写为19888,否则历史服务器不能访问
4> yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties -->
<!--NodeManager上运行的附属服务,需配置成mapreduce_shuffle才可运行MapReduce程序-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property> <!-- 日志删除时间 -1禁用,单位为秒 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property> <!--修改日志目录hdfs://mycluster/var/log/hadoop-yarn/apps,当应用程序运行结束后,日志被转移到的HDFS目录(启用日志聚集功能时有效)-->
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/logs</value>
</property> <!-- yarn内存,配置nodemanager可用的资源内存 -->
<!--<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>8192</value>
</property>--> <!-- yarn cpu,配置nodemanager可用的资源CPU -->
<!--<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>8</value>
</property>--> <!--以下为ha配置-->
<!-- 开启yarn ha -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property> <!-- 指定yarn ha的名称 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>nscluster-yarn</value>
</property> <!--启用自动故障转移-->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>??
<value>true</value>
</property> <!-- resourcemanager的两个名称 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property> <!-- 配置rm1、rm2的主机 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>data1</value>
</property> <!-- 配置yarn web访问的端口 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>data1:8088</value>
</property> <!-- 配置zookeeper的地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2181,data1:2181,data2:2181</value>
</property> <!-- 配置zookeeper的存储位置 -->
<property>
<name>yarn.resourcemanager.zk-state-store.parent-path</name>
<value>/rmstore</value>
</property> <!-- yarn restart-->
<!-- 开启resourcemanager restart -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property> <!-- 配置resourcemanager的状态存储到zookeeper中 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property> <!-- 开启nodemanager restart -->
<property>
<name>yarn.nodemanager.recovery.enabled</name>
<value>true</value>
</property> <!-- 配置rpc的通信端口 -->
<property>
<name>yarn.nodemanager.address</name>
<value>0.0.0.0:45454</value>
</property>
<!--配置Web Application Proxy安全代理(防止yarn被攻击)-->
<property>
<name>yarn.web-proxy.address</name>
<value>0.0.0.0:8888</value>
</property> </configuration>
注意:
A. yarn.nodemanager.address这个属性0.0.0.0:45454,在2.6的版本中不要只写成45454,否则会导致nodemanager启动不了
B. yarn.nodemanager.resource.memory-mb与yarn.nodemanager.resource.cpu-vcores这两个属性,可以默认,在目前的hadoop版本中,如果设置不当,会导致mapreduce程序呈现accepted但是不能run的状态。在试验中,2cpu,1G内存的配置就出现了这种情况。当设置为8cpu,8G内存时却正常了,即使这不是机器的真实配置。针对这种情况,另一个解决方案是添加yarn.scheduler.minimum-allocation-mb这个属性:
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2200</value>
<description>Amount of physical memory, in MB, that can be allocated for containers.</description>
</property> <property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>500</value>
</property>
由于资源问题而导致的这种情况可参考以下:
http://stackoverflow.com/questions/20200636/mapreduce-jobs-get-stuck-in-accepted-state
http://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.0.9.1/bk_installing_manually_book/content/rpm-chap1-11.html
http://zh.hortonworks.com/blog/how-to-plan-and-configure-yarn-in-hdp-2-0/
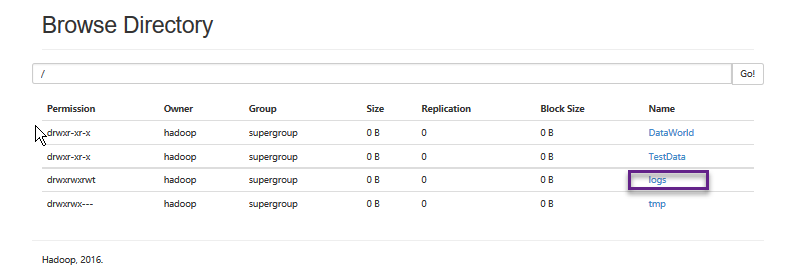
C. 如果日志设置不当,也会出现maprduce不能运行的情况。将yarn.log-aggregation-enable属性设置为true,开启日志聚集功能,则需要设置yarn.nodemanager.remote-app-log-dir属性,即聚集后的日志存放的路径。注意上面将属性设置为/logs,标识的是在hdfs中的目录(不需要自己建立,系统需要时自己会根据配置文件创建),而非本地。下图显示了程序运行后生成的日志:
5> hadoop-env.sh
设置一些重要的环境变量,设置内存的大小等,视情况而定
export JAVA_HOME=/usr/java/jdk
export HADOOP_PORTMAP_OPTS="-Xmx1024m $HADOOP_PORTMAP_OPTS"
export HADOOP_CLIENT_OPTS="-Xmx1024m $HADOOP_CLIENT_OPTS"
..............
6> 其他
在slaves文件中添加master,data1,data2三个名字,另外需要创建在配置文件中出现的一些目录和文件:
etc/hadoop/excludes,hadoop2.6.5/data/nn,data/tmp,data/jn,data/dn,同时设置好这些文件的权限以及所有者和所属组。
4、集群启动
1> 确定启动zookeeper
zkServer.sh start
2> 启动journalnode,新安装的需要三台机器分别启动
hadoop-daemons.sh start journalnode
3> 启动master的namenode
hadoop-daemon.sh start namenode
4> 同步data1的namenode
hdfs namenode -bootstrapStandby
hadoop-daemon.sh start namenode
在data1上执行以上命令后,master与data1节点此时仍然会是standby状态
5> 格式化ZKFC,这一步可以提前运行,不是必须按此顺序,但前提是开启了zookeeper,并且在hadoop的配置文件中设置开启了故障自动转移
hdfs zkfc -formatZK
在master上运行即可。
6> 三台机器分别启动datanode
hadoop-daemons.sh start datanode
7> 开启zkfc,这时查看一下,dfs应该会正常启动了,一般率先启动zkfc的机器会作为active节点
hadoop-daemons.sh start zkfc
先在master上开启,后在data1上开启
8> 开启yarn
start-yarh.sh
# 或者单独启动
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start nodemanager
此处在master上运行start-yarh.sh,在data1上运行yarn-daemon.sh start resourcemanager,让data1作为资源管理器的备选节点。
9> 其他
mr-jobhistory-daemon.sh start historyserver
yarn-daemon.sh start historyserver
开启历史服务器,此处在data1上运行
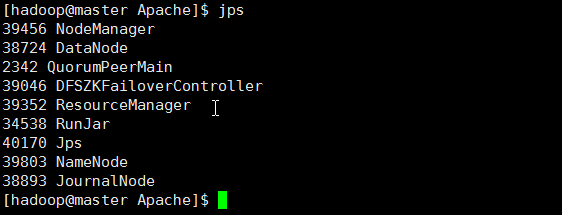
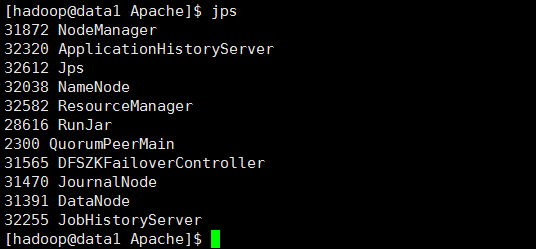
10> 结果
master
data1
data2

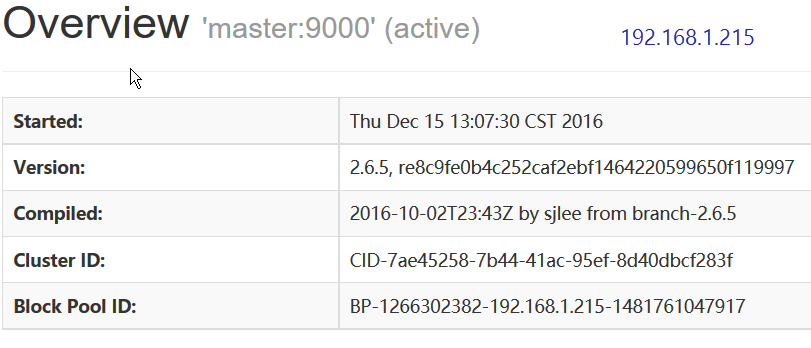
访问192.168.1.215:50070
master处于active状态
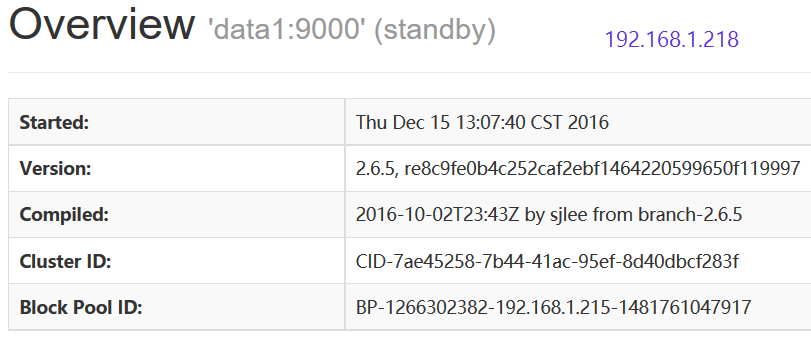
访问192.168.1.218:50070
data1处于standby状态
访问192.168.1.215:8088
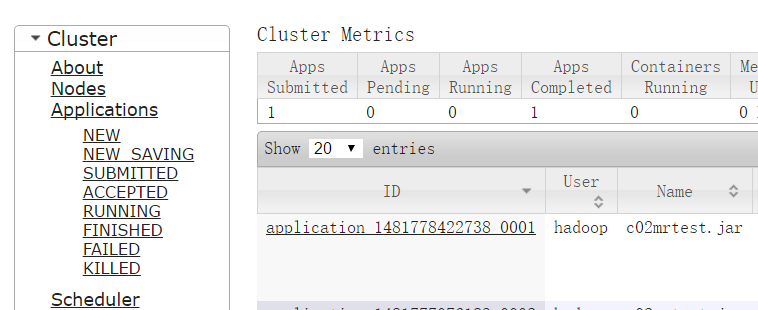
访问192.168.1.218:8088
提示:This is standby RM. Redirecting to the current active RM: http://master:8088/cluster
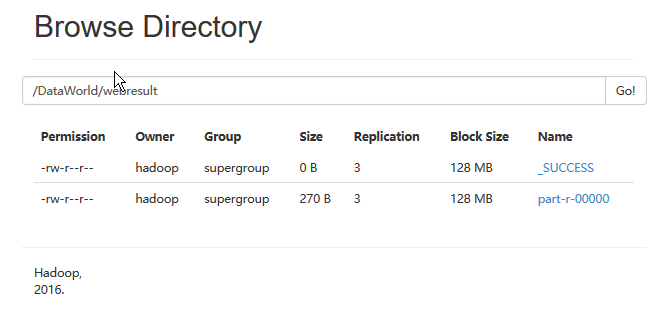
最后进行测试,在任一机器上运行以下命令
yarn jar ~/c02mrtest.jar com.mr.test.MRWeb /TestData/webcount.txt /DataWorld/webresult5
运行结果:
附:常用命令
# journalnode
hadoop-daemons.sh start journalnode
hadoop-daemons.sh stop journalnode
# namenode
hadoop namenode -format
hadoop-daemon.sh start namenode
hadoop-daemon.sh stop namenode
# 同步
hdfs namenode -bootstrapStandby
hadoop-daemon.sh start namenode
# datanode
hadoop-daemons.sh start datanode
hadoop-daemons.sh stop datanode # zookeeper以及zkfc
zkServer.sh start
zkServer.sh stop
hdfs zkfc -formatZK
hadoop-daemons.sh start zkfc
hadoop-daemons.sh stop zkfc
# yarn
yarn-daemon.sh start resourcemanager
yarn-daemon.sh stop resourcemanager
yarn-daemon.sh start nodemanager
yarn-daemon.sh stop nodemanager
yarn-daemon.sh start proxyserver
yarn-daemon.sh stop proxyserver
mr-jobhistory-daemon.sh start historyserver
mr-jobhistory-daemon.sh stop historyserver
yarn-daemon.sh start historyserver
yarn-daemon.sh stop historyserver
# rm1 rm2为配置文件中设定的资源管理器名称
yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm2 start-dfs.sh
stop-dfs.sh
start-yarn.sh
stop-yarn.sh
zookeeper集群的搭建以及hadoop ha的相关配置的更多相关文章
- Solr集群的搭建以及使用(内涵zookeeper集群的搭建指南)
1 什么是SolrCloud SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud.当一个系统的索引数据量少的时候 ...
- 大数据平台搭建-zookeeper集群的搭建
本系列文章主要阐述大数据计算平台相关框架的搭建,包括如下内容: 基础环境安装 zookeeper集群的搭建 kafka集群的搭建 hadoop/hbase集群的搭建 spark集群的搭建 flink集 ...
- [转]ZooKeeper 集群环境搭建 (本机3个节点)
ZooKeeper 集群环境搭建 (本机3个节点) 是一个简单的分布式同步数据库(或者是小文件系统) ------------------------------------------------- ...
- zookeeper集群环境搭建详细图文教程
zookeeper集群环境搭建详细图文教程 zhoubang @ 2018-01-02 [文档大纲] 友情介绍 软件环境 注意点 环境安装 1. 新建用于存储安装包以及软件安装的目录 2. 下载安装z ...
- Linux环境下ZooKeeper集群环境搭建关键步骤
ZooKeeper版本:zookeeper-3.4.9 ZooKeeper节点:3个节点 以下为Linux环境下ZooKeeper集群环境搭建关键步骤: 前提条件:已完成在Linux环境中安装JDK并 ...
- Docker 一步搞定 ZooKeeper 集群的搭建
Docker 一步搞定 ZooKeeper 集群的搭建 背景 原来学习 ZK 时, 我是在本地搭建的伪集群, 虽然说使用起来没有什么问题, 但是总感觉部署起来有点麻烦. 刚好我发现了 ZK 已经有了 ...
- centos7下安装zookeeper&zookeeper集群的搭建
一.centos7下安装zookeeper 1.zookeeper 下载地址 https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/ 2.安装步骤 ...
- centos7 zookeeper集群的搭建
说明:该集群的搭建是为了服务于solr集群,请参考我的关于solr集群搭建的博客. 1.创建solr-cloud目录 mkdir /usr/local/solr-cloud 2.将解压的apache- ...
- Zookeeper集群快速搭建
Zookeeper集群快速搭建 1.cd /usr/local/zookeeper/conf(如在192.168.212.101服务器) mv zoo_sample.cfg zoo.cfg 修改con ...
随机推荐
- 论:开发者信仰之“天下IT是一家“(Java .NET篇)
比尔盖茨公认的IT界领军人物,打造了辉煌一时的PC时代. 2008年,史蒂夫鲍尔默接替了盖茨的工作,成为微软公司的总裁. 2013年他与微软做了最后的道别. 2013年以后,我才真正看到了微软的变化. ...
- [C#] 软硬结合第二篇——酷我音乐盒的逆天玩法
1.灵感来源: LZ是纯宅男,一天从早上8:00起一直要呆在电脑旁到晚上12:00左右吧~平时也没人来闲聊几句,刷空间暑假也没啥动态,听音乐吧...~有些确实不好听,于是就不得不打断手头的工作去点击下 ...
- ABP文档 - SignalR 集成
文档目录 本节内容: 简介 安装 服务端 客户端 连接确立 内置功能 通知 在线客户端 帕斯卡 vs 骆峰式 你的SignalR代码 简介 使用Abp.Web.SignalR nuget包,使基于应用 ...
- 散列表(hash table)——算法导论(13)
1. 引言 许多应用都需要动态集合结构,它至少需要支持Insert,search和delete字典操作.散列表(hash table)是实现字典操作的一种有效的数据结构. 2. 直接寻址表 在介绍散列 ...
- 第一个shell脚本
打开文本编辑器,新建一个文件,扩展名为sh(sh代表shell),扩展名并不影响脚本执行,见名知意就好. #!/bin/bash echo "Hello World !" &quo ...
- Android注解使用之注解编译android-apt如何切换到annotationProcessor
前言: 自从EventBus 3.x发布之后其通过注解预编译的方式解决了之前通过反射机制所引起的性能效率问题,其中注解预编译所采用的的就是android-apt的方式,不过最近Apt工具的作者宣布了不 ...
- Hawk 6. 编译和扩展开发
Hawk是开源项目,因此任何人都可以为其贡献代码.作者也非常欢迎使用者能够扩展出更有用的插件. 编译 编译需要Visual Stuido,版本建议使用2015, 2010及以上没有经过测试,但应该可以 ...
- 简单酷炫的canvas动画
作为一个新人怀着激动而紧张的心情写了第一篇帖子还请大家多多支持,小弟在次拜谢. 驯鹿拉圣诞老人动画效果图如下 html如下: <div style="width:400px;heigh ...
- Oracle Standard Error 列表
今天,我特意从网上找了一些,以及自己平时总结的,关于错误编号和说明,平时我们在写项目的时候,往往是可能会出现下面这些错误,例如:违反唯一约束,无效的会话ID,等等.希望对大家有点帮助!可以看看,如果有 ...
- CSS笔记
初级篇===========================选择器============================元素选择器css:h1{color: red}html:<h1> ...