【笔记】机器学习 - 李宏毅 - 4 - Gradient Descent
梯度下降 Gradient Descent
梯度下降是一种迭代法(与最小二乘法不同),目标是解决最优化问题:\({\theta}^* = arg min_{\theta} L({\theta})\),其中\({\theta}\)是一个向量,梯度是偏微分。
为了让梯度下降达到更好的效果,有以下这些Tips:
1.调整学习率
梯度下降的过程,应当在刚开始的时候,应该步长大一些,以便更快迭代,当靠近目标时,步长调小一些。
虽然式子中的微分有这个效果,但同时改变一下学习率的值,可以很大程度加速这个过程。
比如说用 \(1/t\) 衰减:\({\eta}^t = {\eta}/\sqrt{(t + 1)}\)
另外,不同的参数应当给不同的学习率。
Adagrad方法
Adagrad是再除以一个参数之前所有微分的均方根。

消去\(\sqrt{(t + 1)}\)参数后得到:
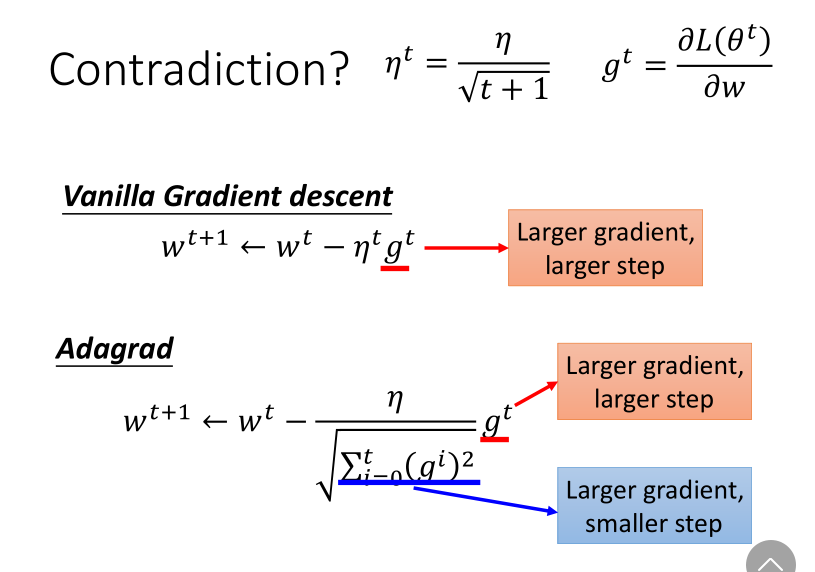
分子分母的作用形成了反差,一个增加步长,一个减小步长。
对此的一种解释是,为了避免迭代突然加快,或者突然减慢。
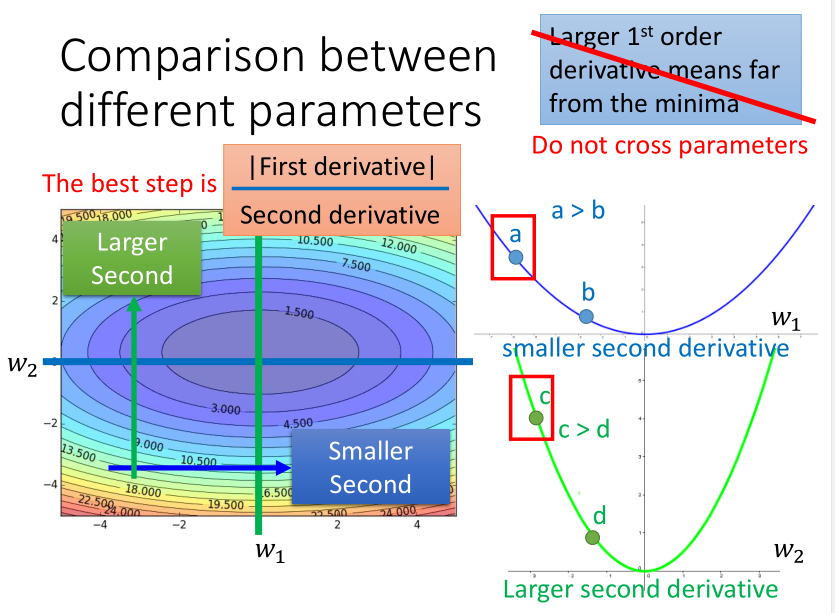
另外一种解释是,以二次凸函数举例,最佳迭代步长直观看是与一次微分成正比的。
但如果考虑跨参数比较的话(不仅看\(x\)),又会发现这个结论不完善,其实它又与二次微分成反比,所以要综合考虑两者。
而二次微分比较难计算,需要更多的时间,所以一般就采用一次微分的均方根来模拟它了。
2.随机梯度下降

随机梯度下降和批量梯度下降不同的是,它不需要把所有训练数据都考虑进来再迭代,而是算出其中一个样本的梯度就迭代一次。
这种方法虽然很快,但数据的震荡也很明显。(小批量梯度下降mini-batch gradient descent是算出其中一部分样本的梯度,是一种折中方法)
3.特征缩放

两个参数的变化范围不同,则在考虑学习率的时候需要分别考虑,比较难处理,而右边的情形就比较容易更新参数,这就是进行特征缩放的原因。
最常见的做法就是直接将其正则化。

梯度下降的原理
为什么每次迭代时,损失函数一定会变小呢?不一定。
可以用泰勒公式可以做解释,一阶的形式非常类似,无论是微分还是偏微分。所以只有当步长较小时,才符合条件。

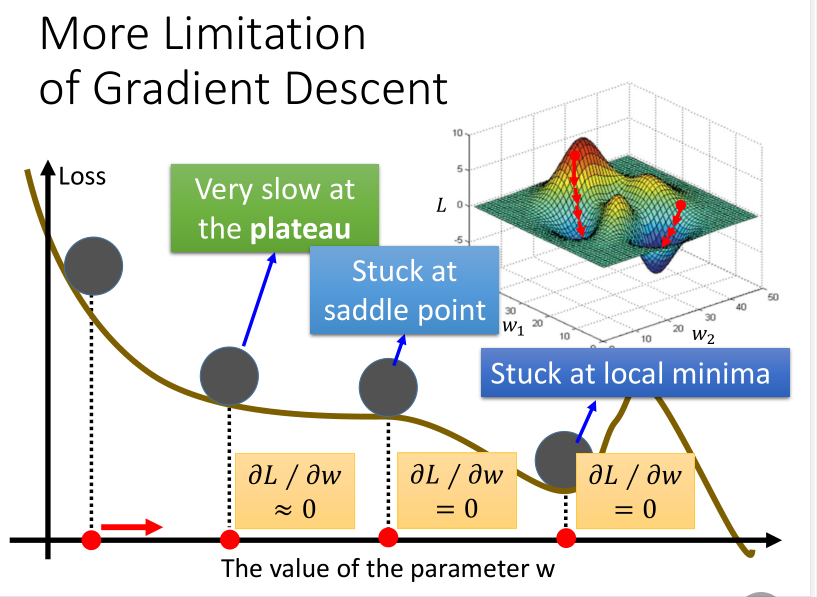
梯度下降的局限
梯度下降方法也有它自身的局限性,如下图所示:
【笔记】机器学习 - 李宏毅 - 4 - Gradient Descent的更多相关文章
- 深度学习课程笔记(四)Gradient Descent 梯度下降算法
深度学习课程笔记(四)Gradient Descent 梯度下降算法 2017.10.06 材料来自:http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLDS1 ...
- 李宏毅老师机器学习课程笔记_ML Lecture 3-1: Gradient Descent
引言: 这个系列的笔记是台大李宏毅老师机器学习的课程笔记 视频链接(bilibili):李宏毅机器学习(2017) 另外已经有有心的同学做了速记并更新在github上:李宏毅机器学习笔记(LeeML- ...
- 吴恩达机器学习笔记 - cost function and gradient descent
一.简介 cost fuction是用来判断机器预算值和实际值得误差,一般来说训练机器学习的目的就是希望将这个cost function减到最小.本文会介绍如何找到这个最小值. 二.线性回归的cost ...
- 李宏毅机器学习笔记2:Gradient Descent(附带详细的原理推导过程)
李宏毅老师的机器学习课程和吴恩达老师的机器学习课程都是都是ML和DL非常好的入门资料,在YouTube.网易云课堂.B站都能观看到相应的课程视频,接下来这一系列的博客我都将记录老师上课的笔记以及自己对 ...
- 机器学习笔记:Gradient Descent
机器学习笔记:Gradient Descent http://www.cnblogs.com/uchihaitachi/archive/2012/08/16/2642720.html
- 斯坦福机器学习视频笔记 Week1 Linear Regression and Gradient Descent
最近开始学习Coursera上的斯坦福机器学习视频,我是刚刚接触机器学习,对此比较感兴趣:准备将我的学习笔记写下来, 作为我每天学习的签到吧,也希望和各位朋友交流学习. 这一系列的博客,我会不定期的更 ...
- 斯坦福机器学习视频笔记 Week1 线性回归和梯度下降 Linear Regression and Gradient Descent
最近开始学习Coursera上的斯坦福机器学习视频,我是刚刚接触机器学习,对此比较感兴趣:准备将我的学习笔记写下来, 作为我每天学习的签到吧,也希望和各位朋友交流学习. 这一系列的博客,我会不定期的更 ...
- 李宏毅机器学习课程---4、Gradient Descent (如何优化 )
李宏毅机器学习课程---4.Gradient Descent (如何优化) 一.总结 一句话总结: 调整learning rates:Tuning your learning rates 随机Grad ...
- 机器学习(1)之梯度下降(gradient descent)
机器学习(1)之梯度下降(gradient descent) 题记:最近零碎的时间都在学习Andrew Ng的machine learning,因此就有了这些笔记. 梯度下降是线性回归的一种(Line ...
随机推荐
- 二、通过工厂方法来配置bean
调用静态工厂方法创建 Bean是将对象创建的过程封装到静态方法中. 当客户端需要对象时, 只需要简单地调用静态方法, 而不同关心创建对象的细节. 要声明通过静态方法创建的 Bean, 需要在 Bean ...
- 最简单的基于FFMPEG+SDL的视频播放器:拆分-解码器和播放器
===================================================== 最简单的基于FFmpeg的视频播放器系列文章列表: 100行代码实现最简单的基于FFMPEG ...
- pyspark 记录
import os import sys spark_name = os.environ.get('SPARK_HOME',None) if not spark_name: raise ValueEr ...
- zabbix4.0的安装与配置
#安装zabbix监控首先的先安装LNMP环境,在这里我采用事先准备好的脚本进行安装LNMP环境 脚本内容如下: #!/bin/bash # DATE:Wed Jan # hw226234@126.c ...
- CentOS7 Cloudera Manager6 完全离线安装 CDH6 集群
本文是在CentOS7.4 下进行CDH6集群的完全离线部署.CDH5集群与CDH6集群的部署区别比较大. 说明:本文内容所有操作都是在root用户下进行的. 文件下载 首先一些安装CDH6集群的必须 ...
- k8s系列---存储卷pv/pvc。configMap/secert
因为pod是有生命周期的,pod一重启,里面的数据就没了.所以我们需要数据持久化存储. 在k8s中,存储卷不属于容器,而是属于pod.也就是说同一个pod中的容器可以共享一个存储卷. 存储卷可以是宿主 ...
- Linux 配置 DNS
这里不讨论如何在linux上搭建一台DNS服务器: 这里讨论的是 配置 linux系统,让其能够解析域名,使用户可以流畅使用Internet 先了解几个文件,位于/etc目录下的有:hosts,hos ...
- JQuery教程之入门基础
语法 $(selector).action() selector:选择器,类似css中的选择器 比如: $('.buttons-tab a') --class为buttons-tab下的子元素a ac ...
- RJM8L151F6P6温度枪方案对比
疫情当下,温度计.呼吸机.监护仪.制氧机等医疗产品的生产供应至关重要,红外温度计属于非接触式测温,它是利用物体热辐射与物体温度之间的关系来工作的. 红外测温仪是一种将红外技术与微电子技术相结合的新型温 ...
- java循环示例
用while循环计算100之内的奇数和偶数和 public class Test{ public static void main(String[] args){ int sum=0; int num ...