Coursera, Deep Learning 4, Convolutional Neural Networks, week3, Object detection
学习目标
- Understand the challenges of Object Localization, Object Detection and Landmark Finding
- Understand and implement non-max suppression
- Understand and implement intersection over union
- Understand how we label a dataset for an object detection application
- Remember the vocabulary of object detection (landmark, anchor, bounding box, grid, ...)
Objective Localization
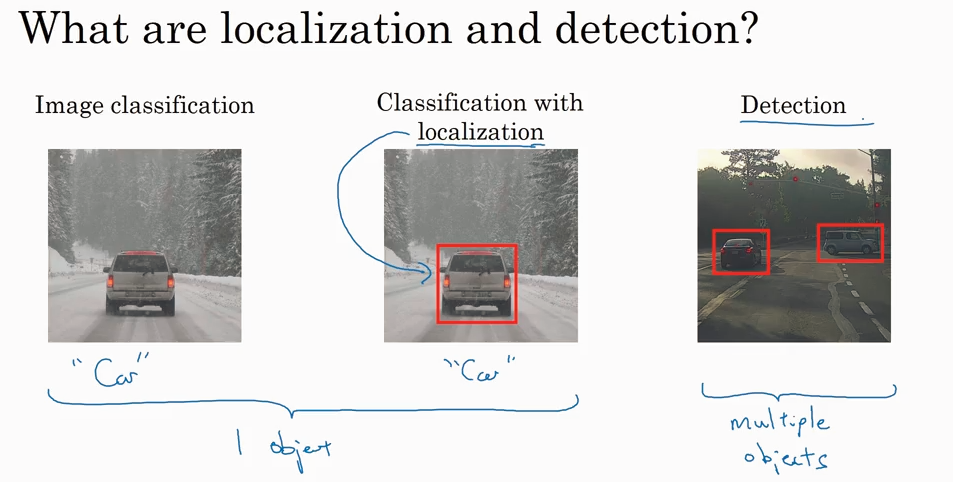
分类,分类加定位,检测。前两种问题都是针对一个object, detection 是针对多个object
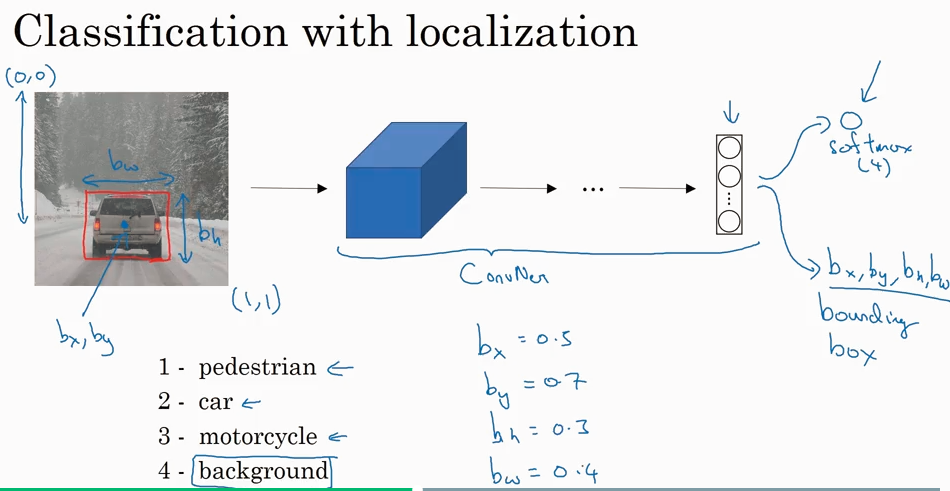
在classification with localization 问题中,就是在output 的 softmax 输出的基础上在加了4个参数来定位bounding box.
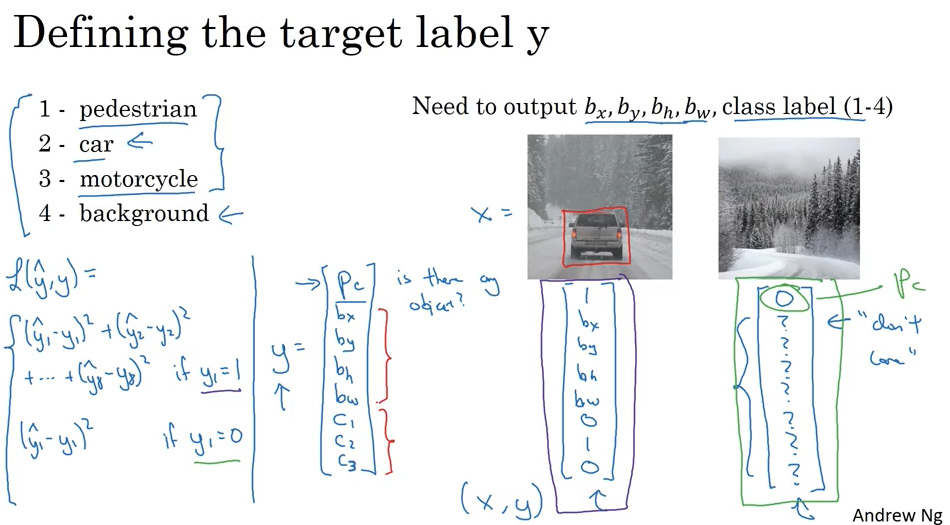
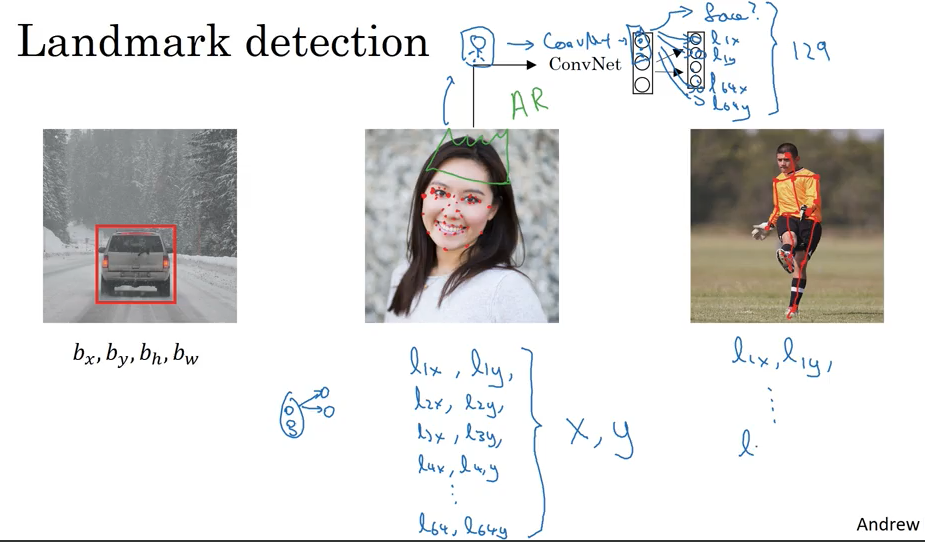
Landmark detection
Object detection


Sliding windown detection 算法最大的缺点是computational cost. 在早期人们用简单的线性分类器去分类的时候还好,现在用conv net 去分类尤其在stride 很小的情况下就cost太高了。幸运的是这个问题有办法解决. 接着往下看
Convolutional implementation of Sliding Windows
下图表示了怎么把fully connected layer 转化为convolutional layer.
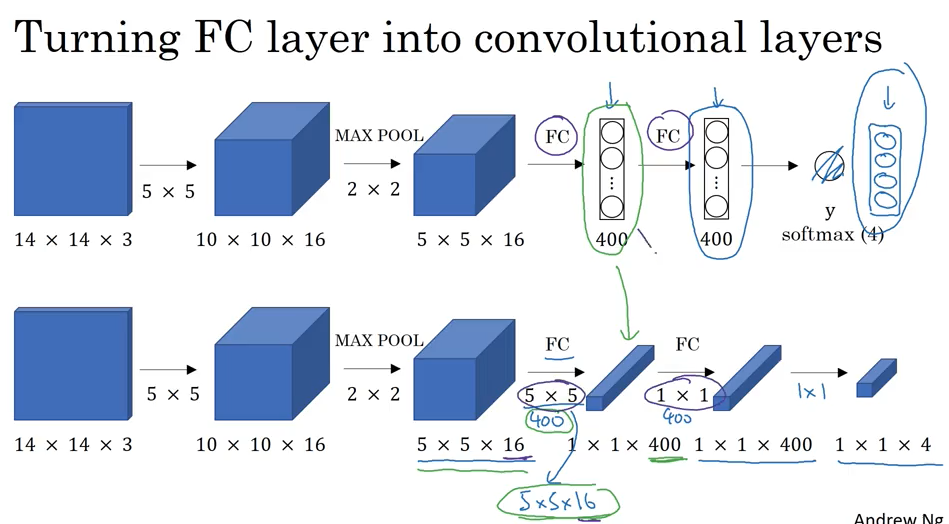
下面显示4次计算高度重复,下图第二行演示了使用第一行训练出来的filter parameter 去预测label,这样可以图像的share的重合的部分,极大提高计算效率。Convolutional 实现可以一次性求出结果而不是循环很多次.
现在还剩一个问题就是只考虑了分类问题没有考虑定位localization问题. 那么怎么定位呢,我们很容易想到前面介绍的classification+localization, 请继续往下看。
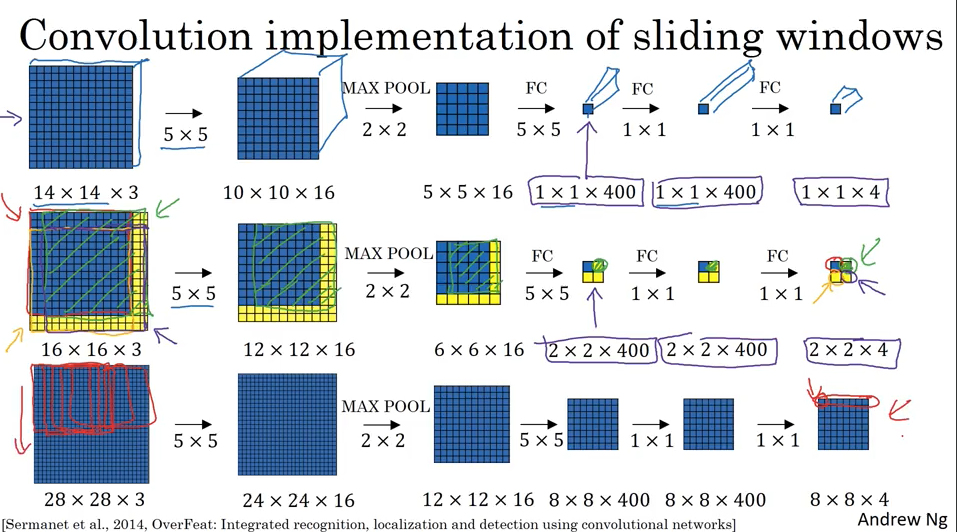
下图演示了用3x3的分割来做分类和定位,实际工作中会更细的分割,比如19x19。
一个对象的midpoint在哪个cell里,就说这个对象属于哪个cell.
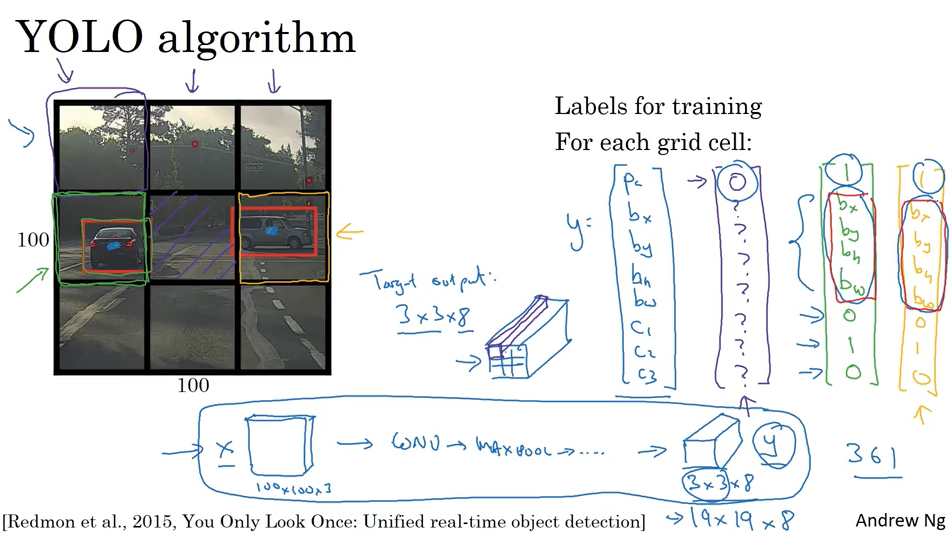
YOLO 算法
YOLO 算法就是前面介绍的知识点的集成,对每一个小方框使用了classification+localization, 然后对整个9个小方框并没有循环,而是使用了convolutional 实现一次性计算。
YOLO 算法能更精确的预测bounding box. 因为解决了不能正好框住object的问题.
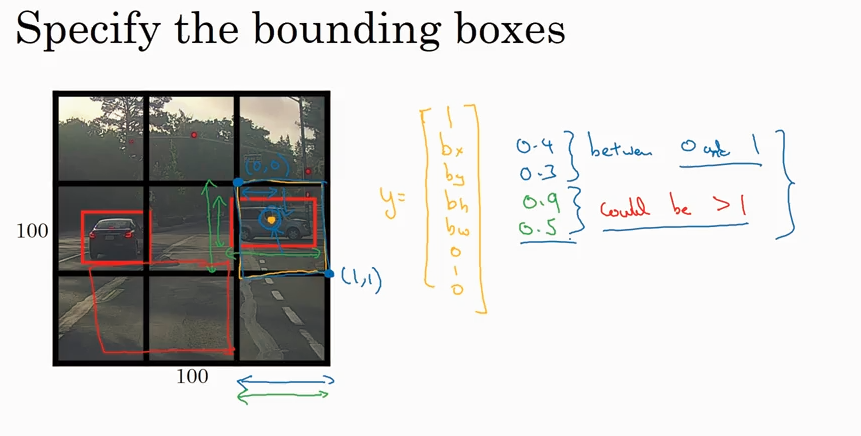
bounding box 的encoding. bh, bw 是和小框边长的比例,可以>1.
IoU (Intersection over Union)

Non-max suppression
解决同一个对象被多次检测到的情况, 去除那些可能性小的bounding box 只留下最可能的


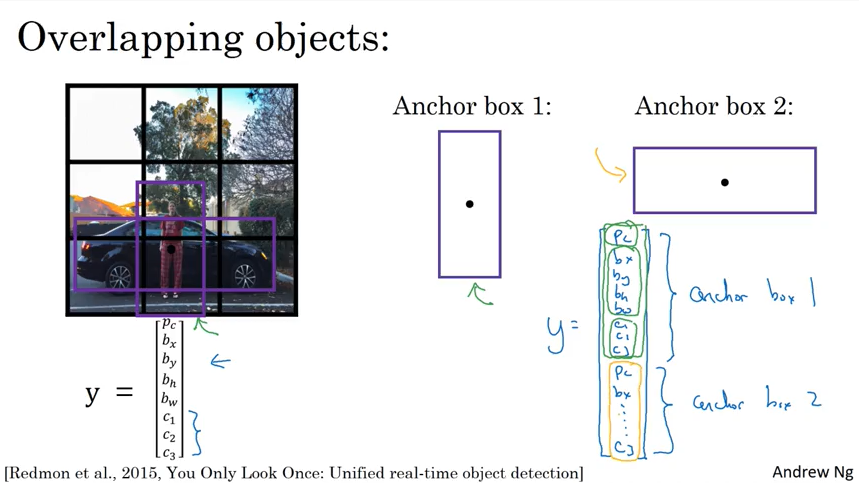
Anchor Boxes
Anchor Boxes 是干什么的?- 使得可以检测多个Object.
为什么之前讲的就是一个cell 只能检测一个Object呢?因为一个y 向量里面只有一个bounding box.
学习过程了产生了一个问题,为什么一定要预定义一些Anchor Box呢?直接像只处理单个Object那样测量一个bounding box, 只不过对多个object的情况测量多个bounding box 不就行了吗? 这里加一些个人理解,我觉得测量多个bounding box这样做也可以,本质上来说Anchor Box 就是bounding box, 只是Anchor Box 尺寸固定更加容易对input 图片标注. 纯属个人理解,希望有人看到这里指教一下.

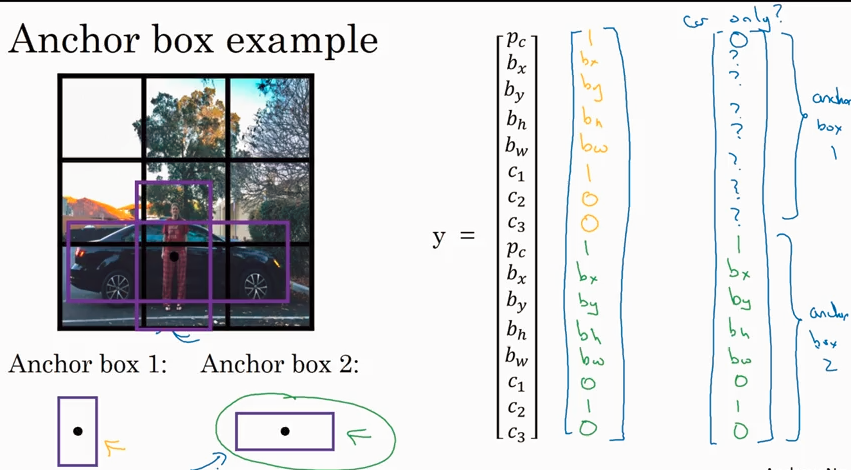
怎么选Anchor box呢?
人们一般手动选择5-10个可以cover 待检测对象的box. 更好的做法是用K-means算法来归类待检测对象,然后自动选出anchor box.
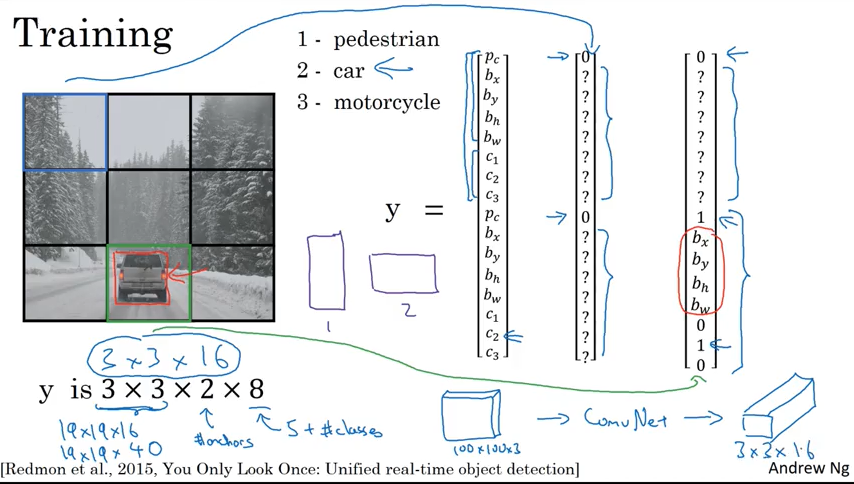
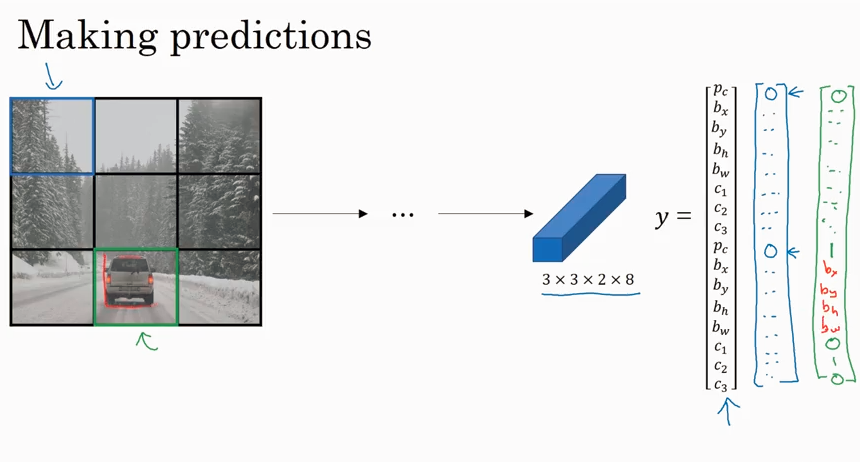
YOLO Algorithm
前面讲了核心的 YOLO算法,然后又讲了一个特殊情况的处理,已经一个对象多次被检测到的情况就需要 non-max suppression, 多个对象共同属于一个cell的情况就需要 Anchor Box. 所以这里集成了完整的YOLO算法.


R-CNN
Region CNN - 忽略一些明显没有用的grid cell

Coursera, Deep Learning 4, Convolutional Neural Networks, week3, Object detection的更多相关文章
- Coursera, Deep Learning 4, Convolutional Neural Networks - week1
CNN 主要解决 computer vision 问题,同时解决input X 维度太大的问题. Edge detection 下面演示了convolution 的概念 下图的 vertical ed ...
- Coursera, Deep Learning 4, Convolutional Neural Networks - week4,
Face recognition One Shot Learning 只看一次图片,就能以后识别, 传统deep learning 很难做到这个. 而且如果要加一个人到数据库里面,就要重新train ...
- Coursera, Deep Learning 4, Convolutional Neural Networks - week2
Case Study (Note: 红色表示不重要) LeNet-5 起初用来识别手写数字灰度图片 AlexNet 输入的是227x227x3 的图片,输出1000 种类的结果 VGG VGG比Ale ...
- Deep Learning Tutorial - Convolutional Neural Networks(LENET)
CNN很多概述和要点在CS231n.Neural Networks and Deep Learning中有详细阐述,这里补充Deep Learning Tutorial中的内容.本节前提是前两节的内容 ...
- 论文笔记之:Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
Learning Multi-Domain Convolutional Neural Networks for Visual Tracking CVPR 2016 本文提出了一种新的CNN 框架来处理 ...
- [CVPR2015] Is object localization for free? – Weakly-supervised learning with convolutional neural networks论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #323333 } p. ...
- 【论文阅读】Learning Dual Convolutional Neural Networks for Low-Level Vision
论文阅读([CVPR2018]Jinshan Pan - Learning Dual Convolutional Neural Networks for Low-Level Vision) 本文针对低 ...
- 【DeepLearning学习笔记】Coursera课程《Neural Networks and Deep Learning》——Week2 Neural Networks Basics课堂笔记
Coursera课程<Neural Networks and Deep Learning> deeplearning.ai Week2 Neural Networks Basics 2.1 ...
- 论文阅读:MDNet: Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
前言 CVPR2016 来自Korea的POSTECH这个团队 大部分算法(例如HCF, DeepLMCF)只是用在大量数据上训练好的(pretrain)的一些网络如VGG作为特征提取器,这些做法 ...
随机推荐
- 【转】服务化框架技术选型与京东JSF解密
[京东技术]声明:本文转载自微信公众号“开涛的博客”,转载务必声明. 作者:章耿,原京东资深架构师,曾负责京东服务框架,配置中心等基础平台.近十年工作经验,专注于基础中间件等底层技术架构,对分布式系统 ...
- Transactional ejb 事务陷阱
对应ejb,默认是对整个类使用事务.所以所有方法都开启事务. 而对于用TransactionAttribute注释来引用容器管理的事务,只能在第一级的方法中使用.对应类中的方法再调用其它类中方法,注释 ...
- bzoj3467: Crash和陶陶的游戏
就一篇题解: BZOJ3467 : Crash和陶陶的游戏 - weixin_34248487的博客 - CSDN博客 1.离线,建出Atrie树:B树的倍增哈希数组,节点按照到根路径字典序排序 2. ...
- aggregate聚合
最近使用mongodb需要查询数据,用到了aggregate,学习下,上代码 db.表名.aggregate([ {$match:{'created_time':{$gte:'2016-01-15', ...
- JavaMail发送邮箱
package utils; import java.security.GeneralSecurityException; import java.util.Properties; import ja ...
- go 定时器
go 定时器 package main import ( "fmt" "time" ) func main() { t := time.NewTicker(ti ...
- python 微信爬虫实例
单线程版: import urllib.request import urllib.parse import urllib.error import re,time headers = (" ...
- C#设计模式(10)——桥接模式
1.桥接模式介绍 桥接模式用于将抽象化和实现化解耦,使得两者可以独立变化.在面向对象中用通俗的话说明:一个类可以通过多角度来分类,每一种分类都可能变化,那么就把多角度分离出来让各个角度都能独立变化,降 ...
- mysq存储金额的数值类型选择
在之前得项目中用到了double,计算之后有很长得小数位,需要用算法去除,非常麻烦,以后推荐使用:decimal 这个是专门处理金额值的,Java 类型对应BigDecimal
- java使用google开源工具实现图片压缩【转】
jar包名 import net.coobird.thumbnailator.Thumbnails; import net.coobird.thumbnailator.geometry.Positio ...