Zipkin 分布式数据追踪系统
Zipkin 是一个分布式数据追踪系统,适用于微服务架构下的调用链路数据采集及分析工作。
可通过一个 Web 前端轻松的收集和分析数据,例如用户每次请求服务的处理时间等,可方便的监测系统中存在的瓶颈。
一、配置 Java 环境 安装 JDK
Zipkin 使用 Java8
yum install java-1.8.-openjdk* -y
java -version
二、安装 Zipkin
1、创建zipkin安装目录
mkdir -p /opt/server/zipkin && cd "$_"
2、下载 Zipkin
wget -O zipkin.jar 'https://search.maven.org/remote_content?g=io.zipkin.java&a=zipkin-server&v=LATEST&c=exec'
3、启动 Zipkin (nohup & 可以进行后台运行 )
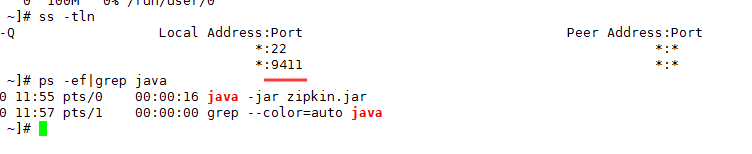
java -jar zipkin.jar
Zipkin 默认监听 9411 端口
三、配置 MySQL 数据持久化
1、Zipkin 支持的持久化方案很多: Cassandra, MySQL, Elasticsearch。
wget http://dev.mysql.com/get/mysql57-community-release-el7-9.noarch.rpm
rpm -Uvh mysql57-community-release-el7-.noarch.rpm
yum install mysql-community-server -y
systemctl start mysqld.service
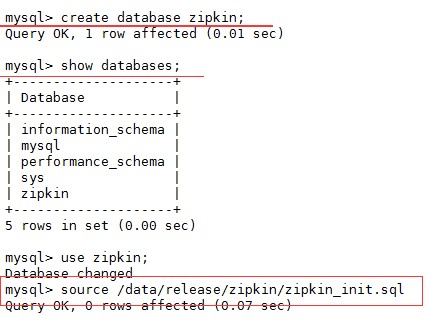
设置 mysql 密码 创建一个zipkin 库;
mysql -uroot -p
> ALTER USER 'root'@'localhost' IDENTIFIED BY 'passwd'; > create database zipkin; exit
2、创建 Zipkin初始化文件 zipkin_init.sql
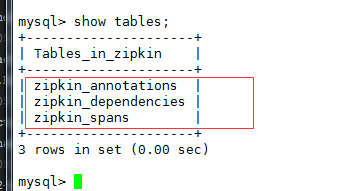
创建了 zipkin_annotations, zipkin_dependencies, zipkin_spans 三张数据表
# cat /opt/server/zipkin/zipkin_init.sql
CREATE TABLE IF NOT EXISTS zipkin_spans (
`trace_id_high` BIGINT NOT NULL DEFAULT COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL,
`id` BIGINT NOT NULL,
`name` VARCHAR() NOT NULL,
`parent_id` BIGINT,
`debug` BIT(),
`start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL',
`duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci; ALTER TABLE zipkin_spans ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `id`) COMMENT 'ignore insert on duplicate';
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`, `id`) COMMENT 'for joining with zipkin_annotations';
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds';
ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames';
ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range'; CREATE TABLE IF NOT EXISTS zipkin_annotations (
`trace_id_high` BIGINT NOT NULL DEFAULT COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id',
`span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id',
`a_key` VARCHAR() NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1',
`a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB',
`a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation',
`a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp',
`endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_ipv6` BINARY() COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address',
`endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_service_name` VARCHAR() COMMENT 'Null when Binary/Annotation.endpoint is null'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci; ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds';
ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames';
ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces';
ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT 'for dependencies job'; CREATE TABLE IF NOT EXISTS zipkin_dependencies (
`day` DATE NOT NULL,
`parent` VARCHAR() NOT NULL,
`child` VARCHAR() NOT NULL,
`call_count` BIGINT
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci; ALTER TABLE zipkin_dependencies ADD UNIQUE KEY(`day`, `parent`, `child`);
3、初始化导入:
mysql -u root --password='passwd' > use zipkin;
> source /opt/server/zipkin/zipkin_init.sql
> show tables;
> exit
四、重新启动 zipkin
cd /opt/server/zipkin
STORAGE_TYPE=mysql MYSQL_HOST=localhost MYSQL_TCP_PORT= MYSQL_DB=zipkin MYSQL_USER=root MYSQL_PASS='passwd' \
nohup java -jar zipkin.jar &
五、创建一个dome 示例
1、搭建 NodeJS 环境
curl --silent --location https://rpm.nodesource.com/setup_8.x | sudo bash -
yum install nodejs -y
2、创建 /opt/server/service_testing 工作目录
mkdir -p /opt/server/service_testing
3、在 /opt/server/service_testing 目录下创建并编辑 package.json
# cat /opt/server/service_testing/package.json
{
"name": "service_testing",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {},
"author": "",
"license": "ISC",
"dependencies": {
"express": "^4.15.3",
"zipkin": "^0.7.2",
"zipkin-instrumentation-express": "^0.7.2",
"zipkin-transport-http": "^0.7.2"
}
}
4、安装相关依赖
# npm install
5、创建并编辑 app.js
# cat /opt/server/service_testing/app.js
const express = require('express');
const {Tracer, ExplicitContext, BatchRecorder} = require('zipkin');
const {HttpLogger} = require('zipkin-transport-http');
const zipkinMiddleware = require('zipkin-instrumentation-express').expressMiddleware; const ctxImpl = new ExplicitContext();
const recorder = new BatchRecorder({
logger: new HttpLogger( {
endpoint: 'http://127.0.0.1:9411/api/v1/spans'
})
}); const tracer = new Tracer({ctxImpl, recorder}); const app = express(); app.use(zipkinMiddleware({
tracer,
serviceName: 'service-testing'
})); app.use('/', (req, res, next) => {
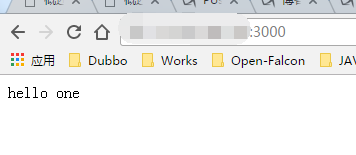
res.send('hello one');
}); app.listen(, () => {
console.log('service-testing listening on port 3000!')
});
6、启动服务 (监听 3000 端口)http://IP:3000
# node app.js
六、zipkin 访问 http://IP:9411
Zipkin 分布式数据追踪系统的更多相关文章
- 分布式链路监控与追踪系统Zipkin
1.分布式链路监控与追踪产生背景2.SpringCloud Sleuth + Zipkin3.分布式服务追踪实现原理4.搭建Zipkin服务追踪系统5.搭建Zipkin集成RabbitMQ异步传输6. ...
- 基于zipkin分布式链路追踪系统预研第一篇
本文为博主原创文章,未经博主允许不得转载. 分布式服务追踪系统起源于Google的论文“Dapper, a Large-Scale Distributed Systems Tracing Infras ...
- zipkin分布式链路追踪系统
基于zipkin分布式链路追踪系统预研第一篇 分布式服务追踪系统起源于Google的论文“Dapper, a Large-Scale Distributed Systems Tracing Inf ...
- 基于CentOS搭建基于 ZIPKIN 的数据追踪系统
系统要求:CentOS 7.2 64 位操作系统 配置 Java 环境 安装 JDK Zipkin 使用 Java8 -openjdk* -y 安装完成后,查看是否安装成功: java -versio ...
- Laravel + go-micro + grpc 实践基于 Zipkin 的分布式链路追踪系统 摘自https://mp.weixin.qq.com/s/JkLMNabnYbod-b4syMB3Hw?
分布式调用链跟踪系统,属于监控系统的一类.系统架构逐步演进时,后期形态往往是一个平台由很多不同的服务.组件构成,用户请求过来后,可能会经过其中多个服务,如图 不过,出问题时往往很难排查,如整个请求变慢 ...
- 数据追踪系统Zipkin 及其 Zipkin的php客户端驱动hoopak
Zipkin是Twitter的一个开源项目,是一个致力于收集Twitter所有服务的监控数据的分布式跟踪系统,它提供了收集数据,和查询数据两大接口服务.Zipkin 是一款开源的分布式实时数据追踪系统 ...
- 【Springboot】实例讲解Springboot整合OpenTracing分布式链路追踪系统(Jaeger和Zipkin)
1 分布式追踪系统 随着大量公司把单体应用重构为微服务,对于运维人员的责任就更加重大了.架构更复杂.应用更多,要从中快速诊断出问题.找到性能瓶颈,并不是一件容易的事.因此,也随着诞生了一系列面向Dev ...
- 分布式链路追踪系统Sleuth和ZipKin
1.微服务下的链路追踪讲解和重要性 简介:讲解什么是分布式链路追踪系统,及使用好处 进行日志埋点,各微服务追踪. 2.SpringCloud的链路追踪组件Sleuth 1.官方文档 http://cl ...
- 微服务SpringCloud之zipkin链路追踪
随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成,当整个请求变慢或不可用时,我们是无法得知该请求是由某个或某些后端服务引起的,这时就需要解决如何快读定位 ...
随机推荐
- 在 Docker 中使用 mysql 的一些技巧
启动到后台: docker-compose start docker-composer 执行命令: entrypoint: pwd app: build: ./app working_dir: /a ...
- 终于解决了用JAVA写窗口程序在不同的windows界面下的显示保持一致。
好像是两三年前的时候发现这个问题. 由于在windows经典界面与windows xp界面下,窗口的标题栏的高度是不一样的. 所以我们在用Java写GUI程序的时候,会遇到一个问题. 当我把一个JFr ...
- JMeter关联(正则表达式提取器)
正则表达式总结 关联:与系统交互过程中,系统返回的内容,需要在接下来的交互中用到,如防止csrf攻击而生成的token. 从前一个请求中取,用Regular Expression Extractor ...
- 第一篇-Win10打开txt文件出现中文乱码
如果刚开始安装的是英文的Win10系统,那么打开txt文件时很容易出现乱码问题.包括打开cmd窗口,也是不能显示中文的.当然,麻烦的处理方法是: 在cmd中想要显示中文:先输入chcp 936,之后中 ...
- javascript 请求action传递中文参数乱码问题
1.js $.ajaxFileUpload ( { url:'<%=basePath%>uploadDatFile/fil ...
- ubuntu vim01
不小心按了ctrl+s(停止向终端输入),解决办法ctrl+q(恢复向终端输入)
- Java如何判断文件或者文件夹是否在?不存在如何创建?
Java如何判断文件或者文件夹是否在?不存在如何创建? 1. 首先明确一点的是:test.txt文件可以和test文件夹同时存在同一目录下:test文件不能和test文件夹同时存在同一目录下. 原 ...
- try语句的使用
C语言里try是一个语句或函数.其作用是是抛出错误用. 将有可能产生错误的语句括在一起,放入try语句块.如果在try语句块中发生异常,FlashPlayer会创建一个错误对象,并将该Error对象派 ...
- tomcat部署-手动启动tomcat部署,添加网页,
公司的内网什么都不能往外传,于是自己用公司的网络搭了一个网页,在网上抄了一堆upload,用来来回传输数据.... 但是每次用ideaJ启动服务器太费时. 研究了一下怎么手动启动tomcat,部署网页 ...
- HDU 1003 Max Sum 求区间最大值 (尺取法)
Max Sum Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total Su ...