论文阅读笔记十二:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation(DeepLabv3+)(CVPR2018)

论文链接:https://arxiv.org/abs/1802.02611
tensorflow 官方实现: https: //github.com/tensorflow/models/tree/master/research/deeplab
实验代码:https://github.com/fourmi1995/IronSegExperiment-Deeplabv3_PLUS.git
摘要
分割任务中常见的结构有空间池化模型与编码-解码结构,前者主要通过不同的卷积和不同rate的池化操作和感受野对输入的feature map编码多尺寸信息。编码-解码结构可以通过逐渐恢复空间信息获得物体的边缘信息。该文的改进:(1)结合了上述两种结构的优点。DeepLabv3+ 在DeepLabv3的基础上增加了一个decoder 模型来是增强物体边缘的分割。(2)引用了Xception中的深度可分卷积,应用在ASPP与decoder提高了网络的训练速度。
介绍
通过引入空洞卷积可以生成更加密集的feature map,然而由于GPU内存的限制,提取输入图片分辨率小4倍甚至8倍的feature map在计算上是不被允许的。而decoder层由于没有卷积核没有被扩张,因此计算速度上可以提高很多。本文的贡献如下。
(1)让DeepLabv3作为encoder,用一个简单有效的decoder模型,形成encoder-decoder结构。
(2)可以通过空洞卷积随意控制编码层feature map的分辨率。
(3)将Xception的深层可分卷积应用在ASPP与decoder模型中,使网络更快速。
(4)在PASCAL VOC2012与Cityscapes上得到stae-of-art的效果。
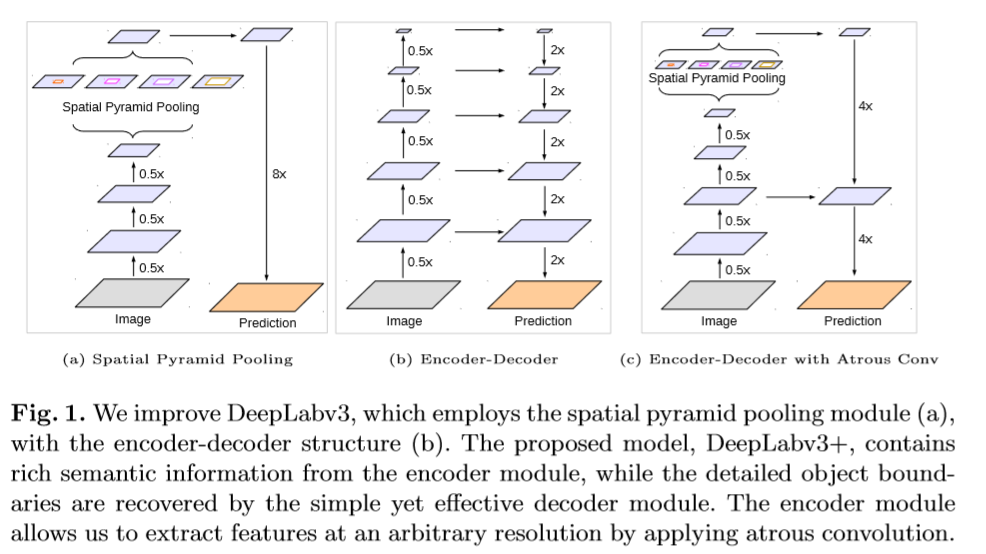
相关工作
Encoder-Decoder:(1)Encoder模型用于减少feature map的分辨率并捕捉更抽象的分割信息。(2)Decoder模型用于恢复空间信息。
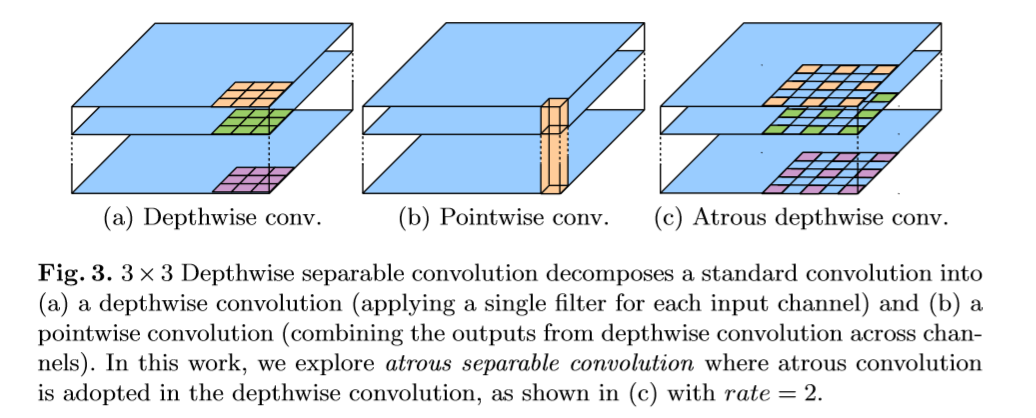
深度可分卷积(group 卷积):该卷积的一个优势是可以在保证性能相近的条件下尽可能的减少计算量和大量的可训练参数。
(参考博客:https://medium.com/@chih.sheng.huang821/%E6%B7%B1%E5%BA%A6%E5%AD%B8%E7%BF%92-mobilenet-depthwise-separable-convolution-f1ed016b3467)
方法
深度可分卷积,将标准的卷积拆为深度卷积,后接一个pointwise卷积(1x1卷积),极大的减少了计算量。深度卷积的功能是对每一个通道进行空间卷积,而pointwise卷积的功能是将深度卷积的输出进行融合。
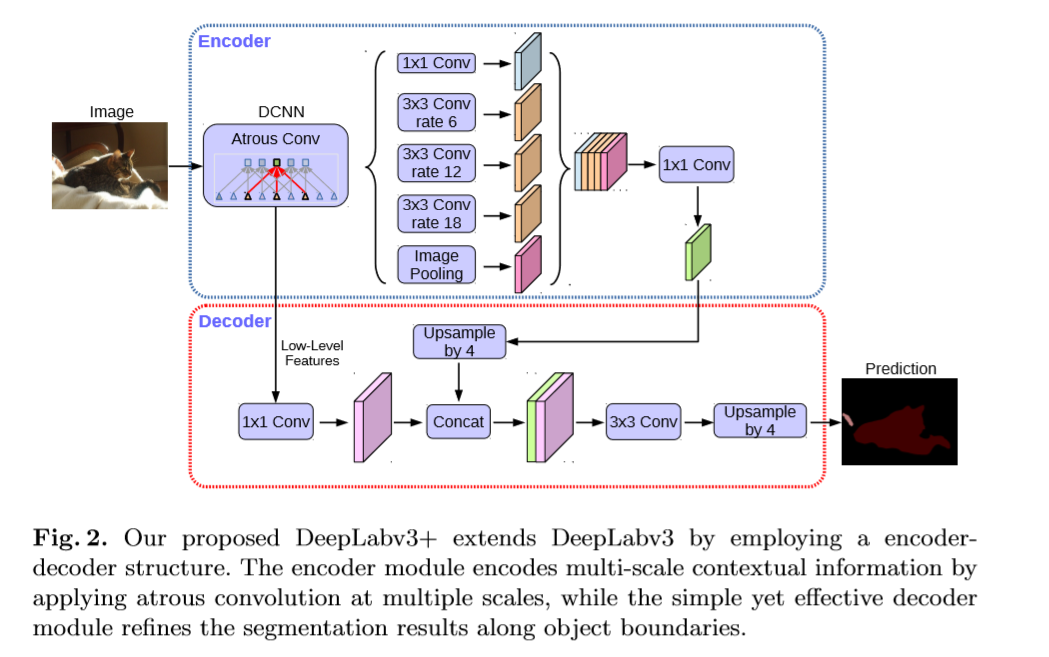
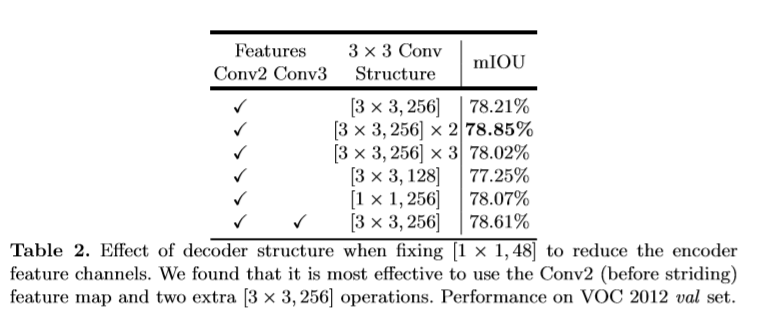
该文使用DeepLabv3中logits前最后一层的feature map作为encoder的输出。通常得到的out_stride为16,基于双线性插值上采样16倍作为decoder层比较常用,但有时可能得不到理想的效果(边界信息仍不准确)。该文提出如下模型。(1)首先通过双线性插值恢复4倍大小的分辨率。(2)然后与对应的低层次的feature map进行拼接,低层次的feature map首先用1x1的卷积处理降低通道数。(3)后接一个大小为3x3的卷积来增强feature maps(4)在通过一个插值来进一步恢复4倍分辨率至原图大小。
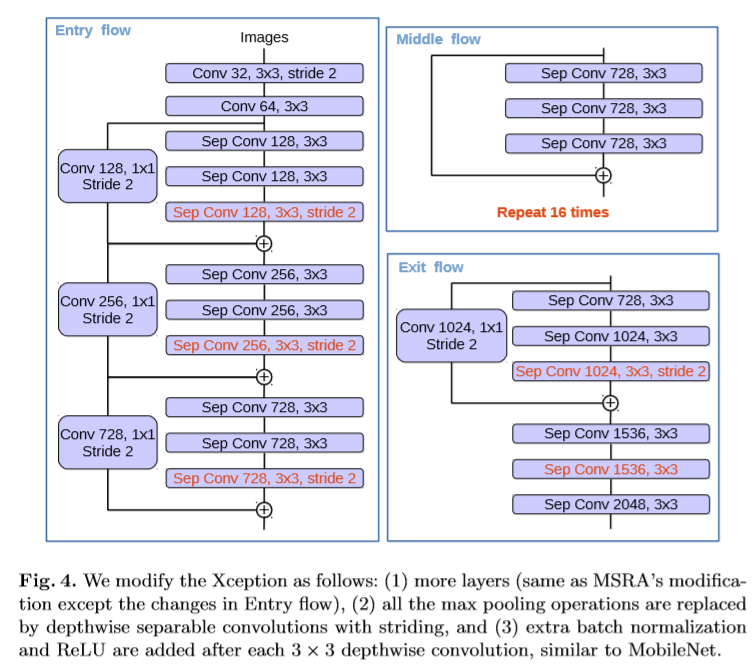
该文对Xception模型的改进,(1)加深了Xception(2)用深度可分卷积替换所有max pooling 减少了计算量,进而可以使用空洞卷积来提取feature(另一种方式是直接在max pooling 中应用空洞卷积)(3)在每个3x3的深度可分卷积后后接,BN层和ReLU。
实验
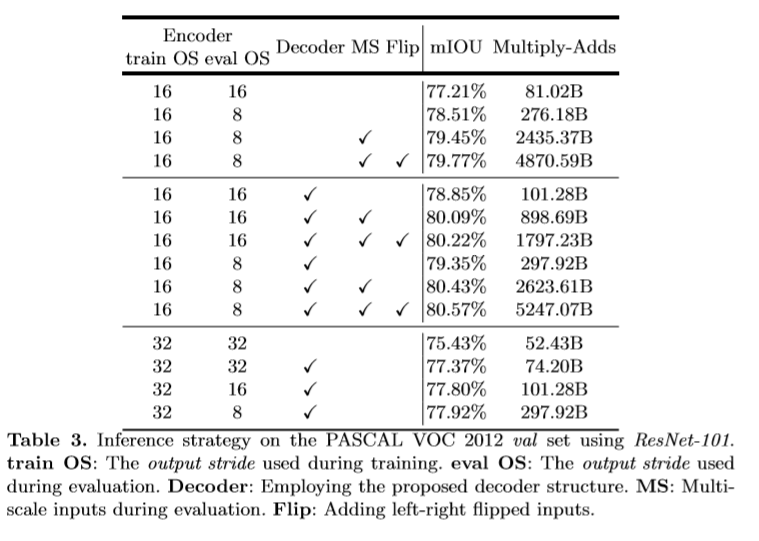
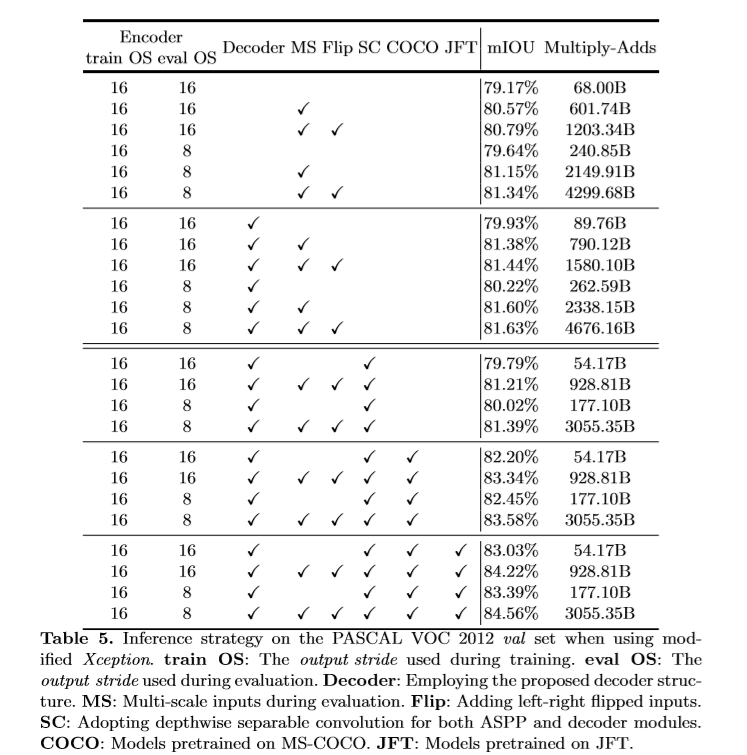
该文使用了预训练的ResNet-101和改进后的Xception通过空洞卷积来提取密集的特征。
learning rate policy: "poly" , learning rate: 0.007, crop size: 513x513 , output_stride = 16,random scale data augmentation


参考
1. Everingham, M., Eslami, S.M.A., Gool, L.V., Williams, C.K.I., Winn, J., Zisserman, A.: The pascal visual object classes challenge a retrospective. IJCV (2014)
2. Mottaghi, R., Chen, X., Liu, X., Cho, N.G., Lee, S.W., Fidler, S., Urtasun, R., Yuille, A.: The role of context for object detection and semantic segmentation in the wild. In: CVPR. (2014)
3. Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., Schiele, B.: The cityscapes dataset for semantic urban scene understanding. In: CVPR. (2016)
个人实验结果

论文阅读笔记十二:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation(DeepLabv3+)(CVPR2018)的更多相关文章
- 论文阅读笔记十四:Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation(CVPR2015)
论文链接:https://arxiv.org/abs/1506.04924 摘要 该文提出了基于混合标签的半监督分割网络.与当前基于区域分类的单任务的分割方法不同,Decoupled 网络将分割与分类 ...
- 论文阅读笔记(二十一)【CVPR2017】:Deep Spatial-Temporal Fusion Network for Video-Based Person Re-Identification
Introduction (1)Motivation: 当前CNN无法提取图像序列的关系特征:RNN较为忽视视频序列前期的帧信息,也缺乏对于步态等具体信息的提取:Siamese损失和Triplet损失 ...
- 论文阅读笔记十九:PIXEL DECONVOLUTIONAL NETWORKS(CVPR2017)
论文源址:https://arxiv.org/abs/1705.06820 tensorflow(github): https://github.com/HongyangGao/PixelDCN 基于 ...
- 论文阅读笔记十六:DeconvNet:Learning Deconvolution Network for Semantic Segmentation(ICCV2015)
论文源址:https://arxiv.org/abs/1505.04366 tensorflow代码:https://github.com/fabianbormann/Tensorflow-Decon ...
- 论文阅读笔记十五:Pyramid Scene Parsing Network(CVPR2016)
论文源址:https://arxiv.org/pdf/1612.01105.pdf tensorflow代码:https://github.com/hellochick/PSPNet-tensorfl ...
- 论文阅读笔记(二十二)【CVPR2017】:See the Forest for the Trees: Joint Spatial and Temporal Recurrent Neural Networks for Video-based Person Re-identification
Introduction 在视频序列中,有些帧由于被严重遮挡,需要被尽可能的“忽略”掉,因此本文提出了时间注意力模型(temporal attention model,TAM),注重于更有相关性的帧. ...
- 论文阅读笔记(二十)【AAAI2019】:Spatial and Temporal Mutual Promotion for Video-Based Person Re-Identification
Introduction (1)Motivation: 作者考虑到空间上的噪声可以通过时间信息进行弥补,其原因为:不同帧的相同区域可能是相似信息,当一帧的某个区域存在噪声或者缺失,可以用其它帧的相同区 ...
- 论文阅读笔记十八:ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation(CVPR2016)
论文源址:https://arxiv.org/abs/1606.02147 tensorflow github: https://github.com/kwotsin/TensorFlow-ENet ...
- 【学习笔记】Vins-Mono论文阅读笔记(二)
估计器初始化简述 单目紧耦合VIO是一个高度非线性的系统,需要在一开始就进行准确的初始化估计.通过将IMU预积分与纯视觉结构进行松耦合对齐,我们得到了必要的初始值. 理解:这里初始化是指通过之前imu ...
随机推荐
- layer兼容性问题
一.Layer 弹出层在ie8错乱的解决办法 弹出层在火狐.谷歌.360极速模式.IE6下都能100%面积正常显示,但在IE8和360的兼容模式下只显示弹出层下半部分或右半部分的内容,在主页面加上: ...
- 2016221 Java第二周学习补充
对switch语句的理解 在程序中遇到switch时,要将switch后的表达式与后续程序中的case常量进行比较,如若相等,程序将执行后面所有的case语句,直到遇到break 为止.如果走完整个程 ...
- unity实现剧情对话
using UnityEngine; using System.Collections; public class Test : MonoBehaviour { private string show ...
- 题解-PKUWC2018 随机游走
Problem loj2542 题意:一棵 \(n\) 个结点的树,从点 \(x\) 出发,每次等概率随机选择一条与所在点相邻的边走过去,询问走完一个集合 \(S\)的期望时间,多组询问 \(n\le ...
- 【转】Linux下gcc生成和使用静态库和动态库详解
一.基本概念 1.1 什么是库 在Windows平台和Linux平台下都大量存在着库. 本质上来说,库是一种可执行代码的二进制形式,可以被操作系统载入内存执行. 由于windows和linux的平台不 ...
- codeforces 461div.2
A Cloning Toys standard input/output 1 s, 256 MB B Magic Forest standard input/output 1 s, 256 M ...
- k8s技能树
- event & signals & threads
The Event Systemhttp://doc.qt.io/qt-4.8/eventsandfilters.html Each thread can have its own event loo ...
- js用replaceAll全部替换的方法
1 前言 js中字符串整体替换,只有自带的replace,并没有replaceAll,如果我们需要把字符串中的字符统一替换,可以用正则表达式,由于经常使用就在String直接加个原生方法,方便调用. ...
- Net 4.5 WebSocket 在 Windows 7, Windows 8 and Server 2012上的比较以及问题
Net 4.5 WebSocket在Windows 8, Windows 10, Windows Server 2012可以,但是在Windows 7, 就会报错. 错误1.“一个文件正在被访问,当前 ...