爬虫——scrapy框架
Scrapy是一个异步处理框架,是纯Python实现的爬虫框架,其架构清晰,模块之间的耦合程度低,可拓展性强,可以灵活完成各种需求。我们只需要定制几个模块就可以轻松实现一个爬虫。
1.架构

Scrapy Engine,引擎,负责整个系统的数据流处理、触发事务,是整个框架的核心。
Item,项目,它定义了爬取结果的数据结构,爬取的数据会被赋值成Item对象。
Scheduler,调度器,接受引擎发送过来的请求,并将其加入到队列之中,在引擎再次请求时将请求提供给引擎。
Downloader,下载器,下载网页内容,并将网页内容返回给爬虫。
Sprider,爬虫,其内定义了爬取逻辑和网页的解析规则,它主要负责解析响应并生成提取结果的新的请求。
Item Pipeline,项目管道,负责处理由爬虫从网页中提取的项目,它的主要任务是清洗、验证和存储数据。
Downloader Middlewares,下载器中间件,位于引擎和下载器直接的钩子框架,主要处理引擎与下载器之间的请求和响应。
Spider Middle,爬虫中间件,位于引擎和爬虫之间的钩子框架,主要处理爬虫输入的响应和输出的结果及新请求。
2.数据流
Scrapy中的数据流由引擎控制,数据流的过程如下:
(1)scrapy engine打开一个网站,找到该网站的Sprider,并向该Sprider请求第一个需要爬取的URL。
3.创建项目
在pycharm的终端Terminal : scrapy startproject tutorial ,
然后在pycharm打开该项目得到如下目录:
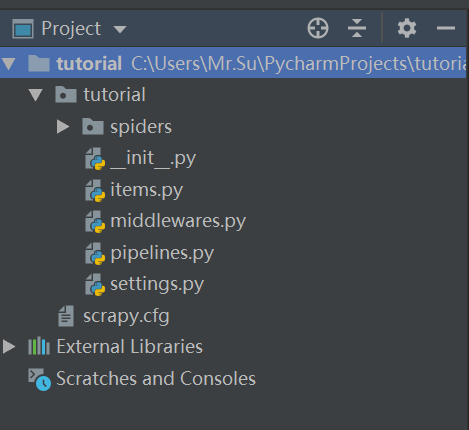
- scrapy.cfg: 项目的配置文件
- tutorial/items.py: 项目中的item文件,定义数据结构。
- tutorial/pipelines.py: 项目中的pipelines文件,数据存储,操作数据。
- tutorial/settings.py: 项目的设置文件。
- tutorial/spiders/: 放置spider代码的目录。
4.创建Spider
spider是自己定义的类,Scrapy用它来抓取内容。并解析抓取的结果。不过这个类必须继承Scrapy提供的Spider类scrapy.Sprider,还要定义Spider的名称和起始请求。
命令行创建spider : scrapy genspider quotes quotes.toscrape.com # -*- coding: utf- -*-
import scrapy class QuotesSpider(scrapy.Spider):
name = 'quotes' #用来区分不同的Spider
allowed_domains = ['quotes.toscrape.com'] #允许爬取的域名
start_urls = ['http://quotes.toscrape.com/'] #spider启动时爬取的url列表 def parse(self, response):#负责解析返回的响应、提取数据或者进一步生成要处理的请求。
#response是爬取start_url的结果
pass
4.创建item
item需要继承scrapy.Item类,并且定义类型为scrapy.Field的字段。假设我们需要获取的内容是name、age、 sex。
修改item.py如下:
# -*- coding: utf- -*- # Define here the models for your scraped items
#保存和爬取数据的容器
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class QuoteItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
age = scrapy.Field()
sex = scrapy.Field()
pass
scrapy demo:爬取http://quotes.toscrape.com/的author、text、tags,并保存为json、csv文件。
items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#保存和爬取数据的容器
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class QuoteItem(scrapy.Item):
# define the fields for your item here like:
text = scrapy.Field()
author = scrapy.Field()
# tags = scrapy.Field()
pass
spirders/quotes.py
# -*- coding: utf- -*-
import scrapy
from tutorial.items import QuoteItem class QuotesSpider(scrapy.Spider):
name = 'quotes' #用来区分不同的Spider
allowed_domains = ['quotes.toscrape.com'] #允许爬取的域名
start_urls = ['http://quotes.toscrape.com/'] #spider启动时爬取的url列表 def parse(self, response): #负责解析返回的响应、提取数据或者进一步生成要处理的请求 #数据提取
quotes = response.css('.quote') #选择所有的quote
for quote in quotes:
item = QuoteItem() #.text::text 表示选择class=text的节点的正文内容
item['text'] = quote.css('.text::text').extract_first() #获取节点的内容:.text::text表示获取其内容text
item['author'] = quote.css('.author::text').extract_first()# .extract_first表示获取其正文的第一个元素
#item['tags'] = quote.css('.tags::text').extract_first()
yield item next = response.css('.pager .next a::attr("href")').extract_first() #获取下一个需要爬取的页面
url = response.urljoin(next)#urljoin()将相对url构造成一个绝对url
yield scrapy.Request(url=url,callback = self.parse) #回调函数 命令行运行: scrapy crawl quotes
执行完成后,我们可以在命令行查看运行结果,但是如何把执行结果保存为json文件或者csv文件呢?
scrapy支持多种格式输出:
scrapy crawl quotes -o quotes.json
scrapy crawl quotes -o quotes.csv
#运行成功后,项目根目录里会自动生成json和csv文件。
爬虫——scrapy框架的更多相关文章
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- 爬虫scrapy框架之CrawlSpider
爬虫scrapy框架之CrawlSpider 引入 提问:如果想要通过爬虫程序去爬取全站数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模 ...
- 安装爬虫 scrapy 框架前提条件
安装爬虫 scrapy 框架前提条件 (不然 会 报错) pip install pypiwin32
- 爬虫Ⅱ:scrapy框架
爬虫Ⅱ:scrapy框架 step5: Scrapy框架初识 Scrapy框架的使用 pySpider 什么是框架: 就是一个具有很强通用性且集成了很多功能的项目模板(可以被应用在各种需求中) scr ...
- Python爬虫Scrapy框架入门(2)
本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西 附上原创链接: http://www.cnblogs.com/qiyeboy/p/5428240.html 基本思路是,查看网页元素,填写 ...
- 爬虫Scrapy框架运用----房天下二手房数据采集
在许多电商和互联网金融的公司为了更好地服务用户,他们需要爬虫工程师对用户的行为数据进行搜集.分析和整合,为人们的行为选择提供更多的参考依据,去服务于人们的行为方式,甚至影响人们的生活方式.我们的scr ...
- 自己动手实现爬虫scrapy框架思路汇总
这里先简要温习下爬虫实际操作: cd ~/Desktop/spider scrapy startproject lastspider # 创建爬虫工程 cd lastspider/ # 进入工程 sc ...
- 爬虫--Scrapy框架课程介绍
Scrapy框架课程介绍: 框架的简介和基础使用 持久化存储 代理和cookie 日志等级和请求传参 CrawlSpider 基于redis的分布式爬虫 一scrapy框架的简介和基础使用 a) ...
- 爬虫--Scrapy框架的基本使用
流程框架 安装Scrapy: (1)在pycharm里直接就可以进行安装Scrapy (2)若在conda里安装scrapy,需要进入cmd里输入指令conda install scrapy ...
- Python网咯爬虫 — Scrapy框架应用
Scrapy框架 Scrapy是一个高级的爬虫框架,它不仅包括了爬虫的特征,还可以方便地将爬虫数据保存到CSV.Json等文件中. Scrapy用途广泛,可以用于数据挖掘.监测 ...
随机推荐
- 利用fpm制作rpm包
使用fpm制作rpm包 安装如下 [root@web01 ~]# yum install -y gcc zlib zlib-devel wget http://ruby.taobao.org/mirr ...
- Java strictfp
strictfp关键字 用于强制Java中的浮点计算(float或double)的精度符合IEEE 754标准. 不使用strictfp:浮点精度取决于目标平台的硬件,即CPU的浮点处理能力. 使用s ...
- 【Beta】博客合集
[Beta Scrum]冲刺! 1/5 [Beta Scrum]冲刺! 2/5 [Beta Scrum]冲刺! 3/5 [Beta Scrum]冲刺! 4/5 [Beta Scrum]冲刺! 5/5
- swiper.js + jquery.magnific-popup.js 实现奇葩的轮播需要
奇葩的轮播图 说轮播图很简单的,一定是没有遇到厉害的产品. 先说需求: 首先,一个mask会有三张图片,点击左右按钮会左右滑动一张图片的宽度. 点击展示的三张图片的任意一张,弹出遮罩,显示该图片的放大 ...
- Linux 大爆炸:一个内核,无数发行版
即使你是一个 Linux 新人,你可能也已经知道它不是一个单一的.整体的操作系统,而是一群项目.这个星座中不同的“星”组成了“发行版”.每个都提供了自己的 Linux 模式. 感谢这一系列发行版所提供 ...
- [容斥原理] hdu 4135 Co-prime
题目链接: http://acm.hdu.edu.cn/showproblem.php?pid=4135 Co-prime Time Limit: 2000/1000 MS (Java/Others) ...
- UVA10817-Headmaster's Headache(动态规划基础)
Problem UVA10817-Headmaster's Headache Time Limit: 4500 mSec Problem Description Input The input con ...
- C. Nice Garland
题意: 就是有一串灯分别颜色是R,G,B.要求将每种颜色的灯相隔2个不同的灯.比如,RGR变成RGB才叫好看. 分析: RGB有6种排列,分别是:"RGB", "RBG& ...
- 路飞学城-Python开发集训-第4章
学习心得: 学习笔记: 在python中一个py文件就是一个模块 模块好处: 1.提高可维护性 2.可重用 3.避免函数名和变量名冲突 模块分为三种: 1.内置标准模块(标准库),查看所有自带和第三方 ...
- 深度学习PyTorch环境安装——mac
参考:http://python.jobbole.com/87522/ 1.首先要安装Anaconda 1)什么是Anaconda Anaconda是Python的包管理器和环境管理器,是一个包含18 ...