TFIDF<细读>
概念
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜寻引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,因特网上的搜寻引擎还会使用基于连结分析的评级方法,以确定文件在搜寻结果中出现的顺序。
<TF-IDF是一种统计方法,用以评估每个字词对于一个文件集或一个语料库中的其中一份文件的重要程度: 评价一个语料库中的每一个词,对于每个文档的重要性,其中这个语料库是所有文档中词的汇总>
原理
在一份给定的文件里,词频 (term frequency, TF) 指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(分子一般小于分母 区别于IDF),以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。)归一化,是该词出现的次数除以该文档所有词的个数。
逆向文件频率 (inverse document frequency, IDF) 是一个词语普遍重要性的度量。某一特定词语的IDF,可以由(总文件数目除以包含该词语之文件的数目)>1,再将得到的商取对数得到。
<总文件数目除以包含该词语之文件的数目: 假如一个词在所有文件中都出现,那么这个商就接近1,log后的值接近0,重要度接近0.如果一个词就在很少的文件中出现,那么这个商值很大,就是重要性也很大> ,这样看来,TF-IDF倾向于过滤掉常见的词语,保留重要的词语>
 TF:表达一个词在一个文件的出现频率程度
TF:表达一个词在一个文件的出现频率程度
 IDF:表达一个词在所有文件份中出现的频率程度
IDF:表达一个词在所有文件份中出现的频率程度
|D|:语料库中的文件总数
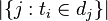 :包含词语
:包含词语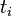 的文件数目(即
的文件数目(即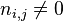 的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用
的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用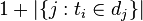
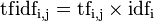
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。
因此,TF-IDF倾向于过滤掉[通过设置TFIDF值的阈值]常见的词语,保留重要的词语。
TFIDF<细读>的更多相关文章
- TF-IDF算法学习报告
TF-IDF是一种统计方法,这个算法在我们项目提取关键词的模块需要被用到,TF-IDF算法是用来估计 一个词汇对于一个文件集中一份文件的重要程度.从算法的定义中就可以看到,这个算法的有效实现是依靠 一 ...
- tf-idf知多少?
1.最完整的解释 TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度.字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反 ...
- TF-IDF提取行业关键词
1. TF-IDF简介 TF-IDF(Term Frequency/Inverse Document Frequency)是信息检索领域非常重要的搜索词重要性度量:用以衡量一个关键词\(w\)对于查询 ...
- 细读cow.osg
细读cow.osg 转自:http://www.cnblogs.com/mumuliang/archive/2010/06/03/1873543.html 对,就是那只著名的奶牛. //Group节点 ...
- Lucene TF-IDF 相关性算分公式(转)
Lucene在进行关键词查询的时候,默认用TF-IDF算法来计算关键词和文档的相关性,用这个数据排序 TF:词频,IDF:逆向文档频率,TF-IDF是一种统计方法,或者被称为向量空间模型,名字听起来很 ...
- TF-IDF
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与文本挖掘的常用加权技术.TF-IDF是一种统计方法,用以评估一字词对于一个文件集或 ...
- TF-IDF 加权及其应用
TF-IDF 加权及其应用 TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索的常用加权技术.TF-IDF是一种统计方法,用以评估某个 ...
- TF-IDF算法
转自:http://www.cnblogs.com/eyeszjwang/articles/2330094.html TF-IDF(term frequency–inverse document fr ...
- TF-IDF 文本相似度分析
前阵子做了一些IT opreation analysis的research,从产线上取了一些J2EE server运行状态的数据(CPU,Menory...),打算通过训练JVM的数据来建立分类模型, ...
随机推荐
- Linux命令面试集
Linux:免费开源,多用户多任务,衍生出很多附属版本,例如常用的RedHat... 常用指令 ls 显示文件或目录 -l 列出文件详细信息l(list) -a ...
- select2的设置选中
select2插件设置选中值并显示的问题 在select2中,要想设置指定值为选中状态并显示: $("#select2_Id").val("XXXXX").se ...
- 求数组中两数之和等于target的两个数的下标
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标. 你可以假设每种输入只会对应一个答案.但是,你不能重复利用这个数组中同样的元 ...
- Python学习笔记6函数和代码复用
1.函数 (1)定义: (2)函数调用 (3)函数的参数传递 参数传递的两种方式:函数调用时,参数可以按照位置或名称的方式传递 (4)函数的返回值 (5)局部变量和全局变量 (6)lambda函数 2 ...
- 解析ReentrantLock实现原理
在Java中通常实现锁有两种方式,一种是synchronized关键字,另一种是Lock(Lock的实现主要有ReentrantLock.ReadLock和WriteLock).synchronize ...
- Java API使用
汉化版Java API使用 首次打开出现的问题 在首次打开API时,可能你会遇见这样的问题. 经过查阅,发现是因为文档的权限问题,文档未解锁造成的.这时候只需要给给它权限就可以. 首先关闭程序,单击右 ...
- Oracle 12导出、导入数据
Precondition: complete the work described in Oracle 12 创建新的数据库实例.用户 1. export data under user " ...
- 201771010134杨其菊《面向对象程序设计(java)》第十六周学习总结
第十六周学习总结 第一部分:理论知识 1. 程序是一段静态的代码,它是应用程序执行的蓝本.进程是程序的一次动态执行,它对应了从代码加载.执行至执行完毕的一个完整过程.操作系统为每个进程分配一段独立的内 ...
- vue项目跳转到外部链接
vue项目中遇到一个打印的功能.思考之后决定点击按钮,跳转到一个HTML页面(后台写的),利用window.print()方法调用浏览器的打印的功能. 所以,现在的问题是,怎样跳转到外部链接.开发vu ...
- vue+elementUI表格列显示隐藏遇到bug
在最近的项目中,有需求要做到根据字段显示列,原来以为简单的v-if可以解决. 在开发的过程中遇到问题, <el-table ref="multipleTable" :data ...