ELK收集Nginx自定义日志格式输出
1.ELK收集日志的有两种常用的方式:
1.1:不修改源日志格式,简单的说就是在logstash中转通过 grok方式进行过滤处理,将原始无规则的日志转换为规则日志(Logstash自定义日志格式)
1.2:修改 源日志格式,将需要的日志格式进行规则输出,logstash只负责日志的收集和传输,不对日志做任何过滤处理(filebeat生产者自定义日志格式)
优缺点:
首先我们来看下不修改源日志格式,这样Logstash会通过grok来处理分析,对线上业务无任何影响;但是在高压环境下,Logstash中的grok会成为性能瓶颈,最终会阻塞正常的日志输出,所以,在Logsatsh中,尽量不要使用grok过滤功能
第二种是修改 源日志格式,也就是在收集生产日志的过程中,自定义日志格式,虽然有一定的工作量,但是优势很明显,因为是实现定义好了日志输出格式,logstash那就只负责收集和传输了,这样大大减轻了logstash负担,可以更高效的收集和传输日志;是企业首选方案
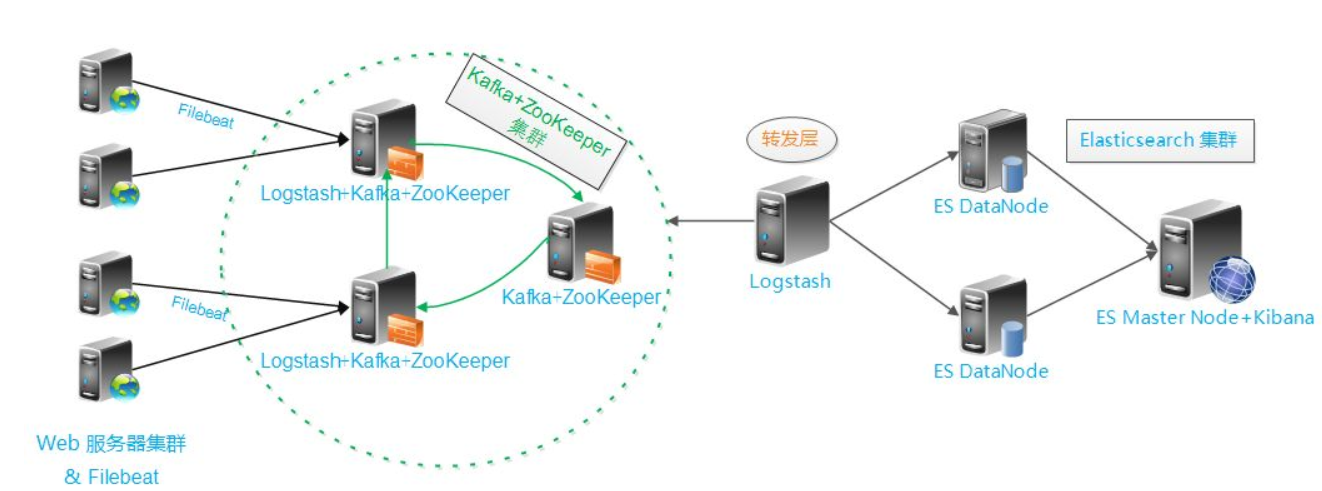
下图是引用了网上与之本次实验效果图
最前方是一台Apache服务器用于生产日志,filebeat收集web服务产生的日志,将收集到的日志推送到Kafka集群中,完成日志的收集工作
接着Logstash去kafka集群中拉取日志并进行过滤分析之后转发到Elasticsearch集群中进行索引和存储,最后由Kibana完成日志的可视化查询展示
Nginx支持自定义输出日志格式;先来了解一下关于多层代理获取用户真实IP的几个概念
#remote_addr: 客户端地址,如果没有使用代理,默认就是客户端真实IP,如果使用了代理,这个就是上层代理IP
#X-Forwarded-For: 简称XFF,一个http扩展头,格式为X-Forwarded-For:client,proxy1,proxy2,如果请求经过三个代理层(proxy1,proxy2.proxy3),用户IP为IP0,那么标准的XFF,服务器最终只会收到X-Forwarded-For:IP0,IP1,IP2
Ps:经过了三层代理。IP3这个地址X-Fowarded-For并未获取到,而remote_addr刚好获取的就是IP3的地址
下面红色标记的字段是自定义nginx日志输出格式:其中调用了nginx中map指令,通过map定义了一个变量$clientRealIp,这个就是获取客户端真实IP的变量,map指令由ngx_http_map_module模块提供并默认加载
map首选定义了一个$clientRealIp变量,如果$HTTP_x_forwarded_for为空的话“(""为空),则remote_addr的变量值则赋予给clientRealIP,如果不为空,则通过正则表达式取出第一个IP赋值给firstAddr,最后由firstAddr赋值给clientRealIP;
接着,通过log_format指令自定义nginx日志格式定义了13个字段,access_log指令指定了日志文件存放路径
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 1024;
}
http {
map $http_x_forwarded_for $clientRealIp {
"" $remote_addr;
~^(?P<firstAddr>[0-9\.]+),?.*$ $firstAddr;
}
log_format nginx_log_json '{"accessip_list":"$proxy_add_x_forwarded_for","client_ip":"$clientRealIp","http_host":"$host","@timestamp":"$time_iso8601","method":"$request_method","url":"$request_uri","status":"$status","http_referer":"$http_referer","body_bytes_sent":"$body_bytes_sent","request_time":"$request_time","http_user_agent":"$http_user_agent","total_bytes_sent":"$bytes_sent","server_ip":"$server_addr"}';
access_log /var/log/nginx/access.log nginx_log_json;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
include /etc/nginx/mime.types;
default_type application/octet-stream;
include /etc/nginx/conf.d/*.conf;
server {
listen 80 default_server;
listen [::]:80 default_server;
server_name _;
root /usr/share/nginx/html;
include /etc/nginx/default.d/*.conf;
location / {
}
error_page 404 /404.html;
location = /40x.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}
}
输出的日志为
#tail /var/log/nginx/access.log
{"accessip_list":"124.207.82.22","client_ip":"124.207.82.22","http_host":"203.195.163.239","@timestamp":"2018-09-03T19:47:42+08:00","method":"GET","url":"/","status":"304","http_r
eferer":"-","body_bytes_sent":"0","request_time":"0.000","http_user_agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 S
afari/537.36","total_bytes_sent":"180","server_ip":"10.104.137.230"}

分析详解:
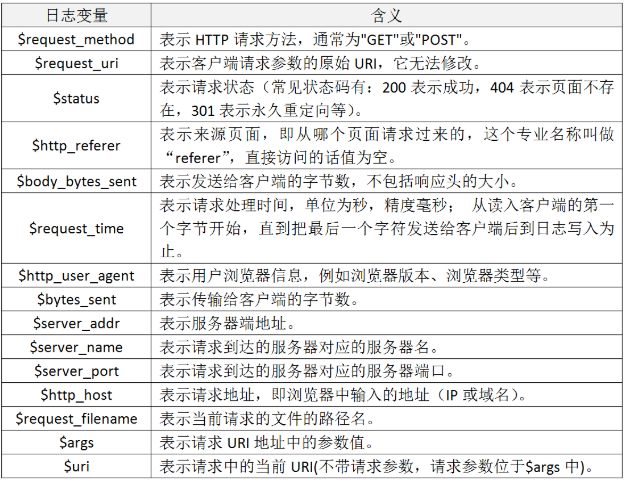
accessip_list:输出时代理叠加而成的IP地址列表
client_ip:客户端访问真实IP
http_host:客户端请求的地址,也就是浏览器输入的IP或者域名
@timestamp:时间戳,表示请求的时间
method:表示HTTP请求方法,通常为“GET”或者“POST”
url:表示客户端请求参数的原始URL
status:表示请求状态
http_reserer:表示来源页面,即从哪个页面请求过来的,专业名称叫referer
body_bytes_sent:表示发送客户端的字节数,不包括响应头的大小
request_time:表示请求处理时间,单位为秒,精度毫秒
http_user_agent:表示用户浏览器信息,例如浏览器版本,类型等
total_bytes_sent:表示传输给客户端字节数
server_ip:表示本地服务器的IP地址信息
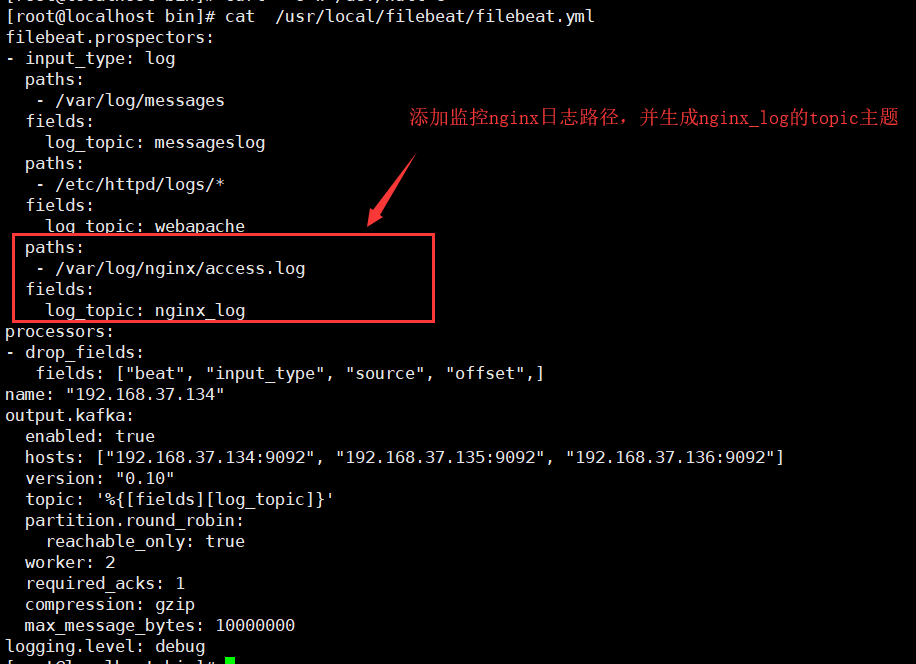
【filebeat配置】

【Logstash事件配置 】
input {
kafka {
bootstrap_servers => "192.168.37.134:9092,192.168.37.135:9092,192.168.37.136:9092"
topics => "nginx_log" #指定输入源中需要从哪个topic中读取日志数据
group_id => "logstash"
codec => json {
charset => "UTF-8" #将输入的json日志输出进行utf8格式编码
}
add_field => { "[@metadata][myid]" => "nginxaccess-log" } #增加一个字段,用于标识和判断,与下方output输出相对应
}
}
filter {
if [@metadata][myid] == "nginxaccess-log" {
mutate {
gsub => ["message", "\\x", "\\x"] #message字段,也就是日志的输出内容,插件作用就是讲message字段内容中UTF8单字节编码做替换处理,目的就是应对URL出现中文情况,防止乱码的出现
}
if ( 'method":"HEAD' in [message] ) { #如果message字段中有HEAD请求,就会删除
drop {}
}
json { #启动json解码插件,因为输入的数据是复合的数据结构,只是一部分记录的是json格式
source => "message" #指定json格式字段,也就是message字段
remove_field => "prospector"
remove_field => "beat"
remove_field => "source"
remove_field => "input"
remove_field => "offset"
remove_field => "fields"
remove_field => "host"
remove_field => "@version"
remove_field => "message" #因为json格式中已经定义好了每个字段,所以输出也就是按照每个字段输出,不需要message字段了,这里直接移除
}
}
}
output {
if [@metadata][myid]=="nginxaccess-log" { #当有多个输入源的时候,可根据不同的标识,指定不同的输出地址
elasticsearch {
hosts =>["192.168.37.134:9200","192.168.37.135:9200","192.168.37.136:9200"]
index => "webnginx_log-%{+YYYY-MM-dd}" #自定义指定索引名称
}
}
}
[root@localhost etc]# nohup /usr/local/logstash/bin/logstash -f nginxlog.conf & #后台运行Logstash事件
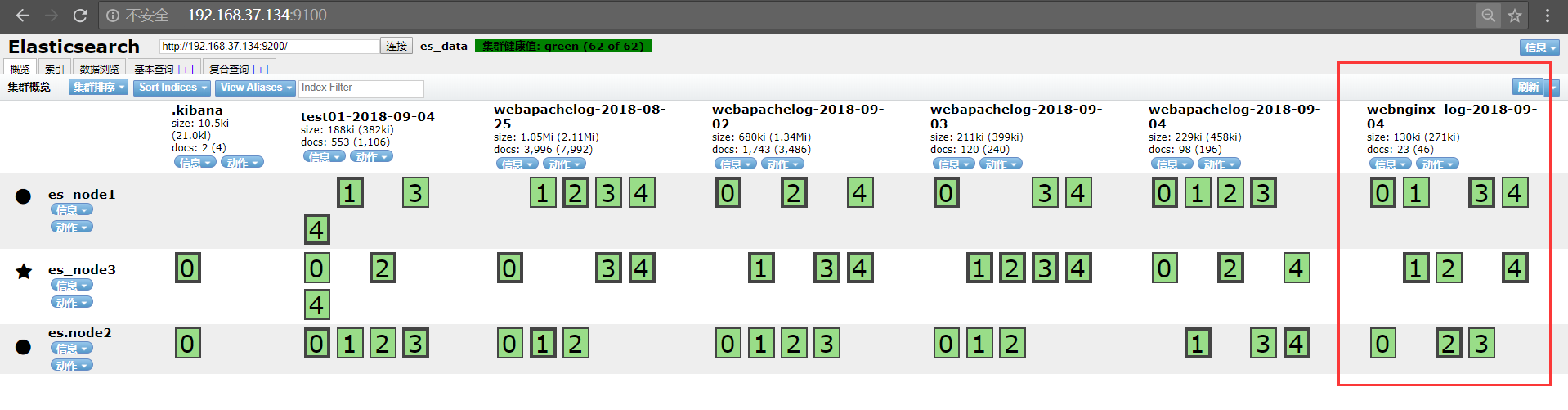
http://192.168.37.134:9100/ #访问Elasticsearch集群ip,验证es是否将nginx日志事件存储为索引;
ok! Elasticsearch成功存储索引名称
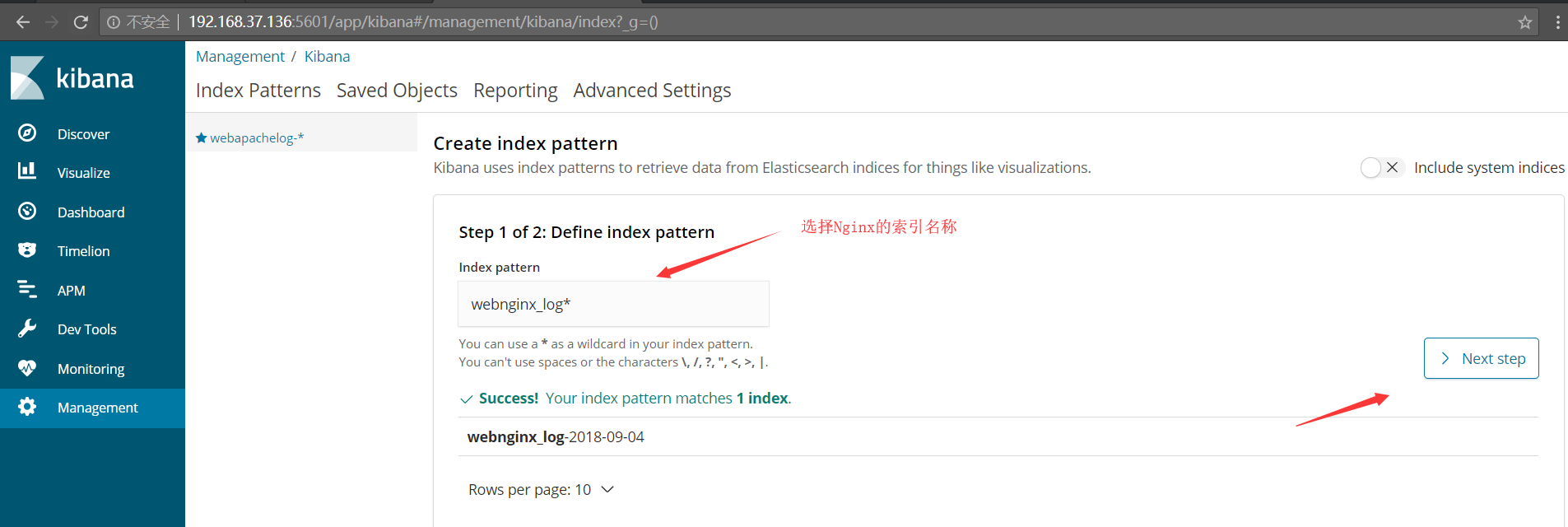
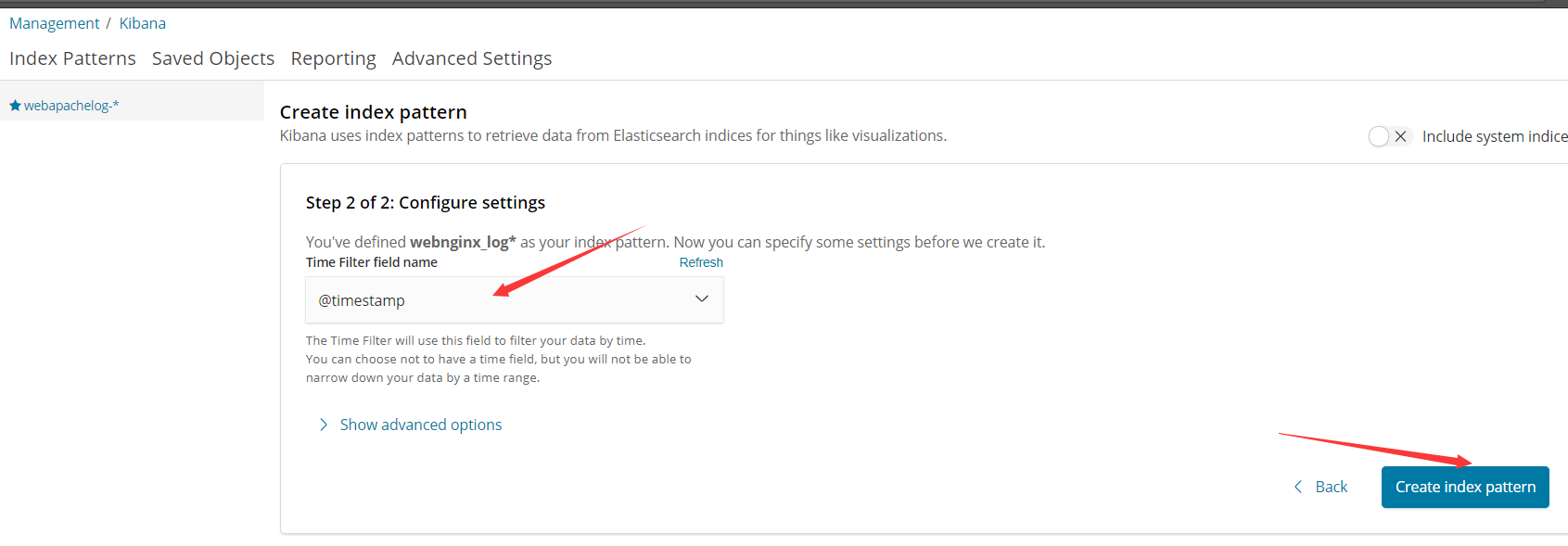
http://192.168.37.136:5601 接下来在kibana创建索引,如下图所示


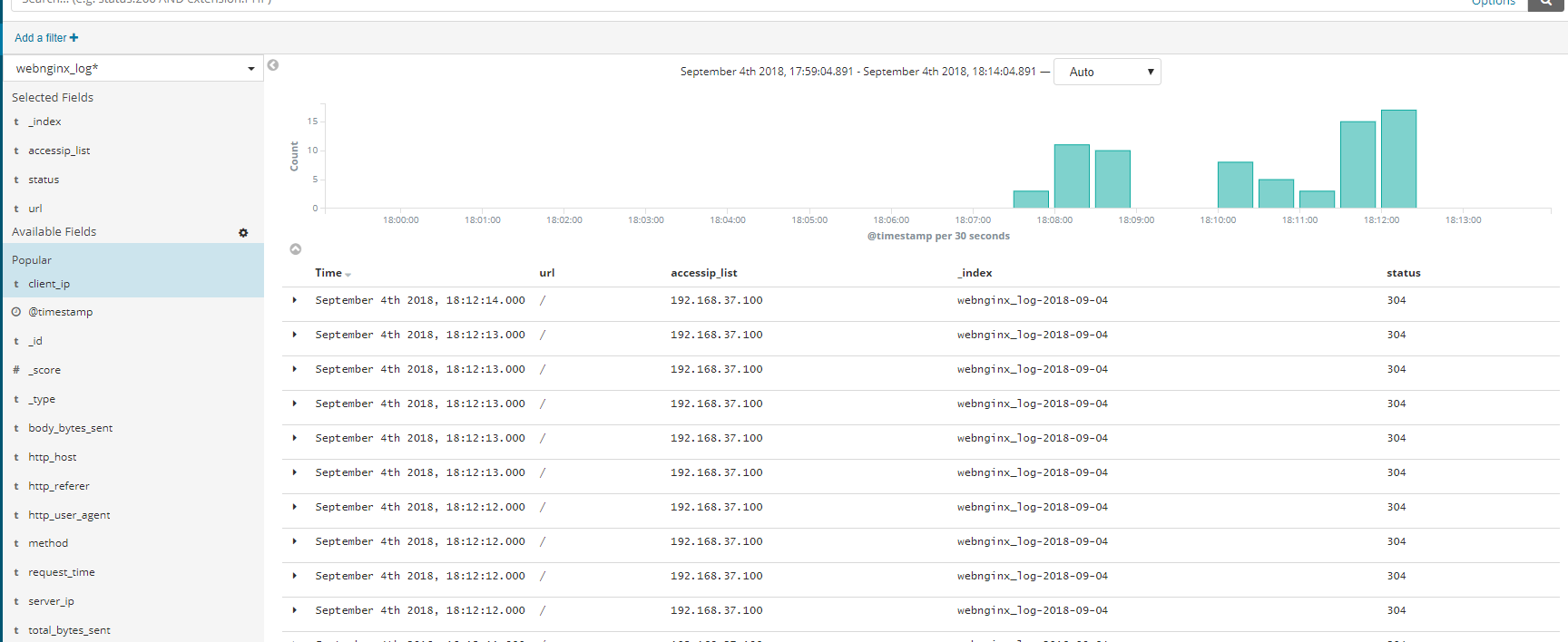
最后我们可以看到。从最开始的自定义日志格式,到索引存储,最终到Kibana展示,过程一点毛病都没有,展示的日志都 是我们自定义的样子,依旧是13个字段,很有条理性,我们还可以在左侧进行删选操作,这样更加的高效~ok,打完收工~

ELK收集Nginx自定义日志格式输出的更多相关文章
- ELK收集Nginx|Tomcat日志
1.Nginx 日志收集,先安装Nginx cd /usr/local/logstash/config/etc/,创建如下配置文件,代码如下 Nginx.conf input { file { typ ...
- 搭建ELK收集Nginx日志
众所周知,ELK是日志收集套装,这里就不多做介绍了. 画了一个粗略的架构图,如下: 这里实际用了三个节点,系统版本为CentOS6.6,ES版本为2.3.5,logstash版本为2.4.0,kiba ...
- logstash收集nginx访问日志
logstash收集nginx访问日志 安装nginx #直接yum安装: [root@elk-node1 ~]# yum install nginx -y 官方文档:http://nginx.org ...
- Nginx配置日志格式记录cookie
Nginx配置日志格式记录cookie1. 一般用来做UV统计,或者获取用户token等. 配置方式: 在nginx的配置文件中有个变量:$http_cookie来获取cookie的信息.配置方式很 ...
- ELK收集tomcat状态日志
1.先查看之前的状态日志输出格式:在logs/catalina.out这个文件中 最上面的日志格式我们可能不太习惯使用,所以能输出下面的格式是最好的,当然需要我们自定义日志格式,接下来看看如何修改 2 ...
- 场景2 nginx 错误日志格式:
nginx 错误日志格式: 2016/09/01 11:23:36 [error] 28388#0: *14549 open() "/var/www/zjzc-web-frontEnd/im ...
- Docker 部署 ELK 收集 Nginx 日志
一.简介 1.核心组成 ELK由Elasticsearch.Logstash和Kibana三部分组件组成: Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引 ...
- Logstash动态模板映射收集Nginx的Json格式日志
Logstash传输给ES的数据会自动映射为5索引,5备份,字段都为text的的索引.这样基本上无法进行数据分析.所以必须将Logstash的数据按照既定的格式存储在ES中,这时候就要使用到ES模板技 ...
- 收集Nginx的json格式日志(五)
一.配置nginx [root@linux-node1 ~]# vim /etc/nginx/nginx.conf #修改日志格式为json格式,并创建一个nginxweb的网站目录 log_form ...
随机推荐
- iOS post提交数据有嵌套数组的处理方法
2017年11月21日17:11:43 解决办法, 修改iOS框架里的代码: http://www.jianshu.com/p/130daa0c2fe7 确实有效, 要不然, 内层的每一个键值对都会 ...
- Android中验证输入是否为汉字、手机号及邮箱
1,验证是否为汉字 Code// 验证昵称 private boolean verifyNickname() { String nickname = edt_username.getText().to ...
- 【原创】数据库基础之Mysql(3)mysql删除历史binlog
mysql开启binlog后会在/var/lib/mysql下创建binlog文件,如果手工删除,则下次mysql启动会报错: mysqld: File './master-bin.000001' n ...
- 02 编程语言、python变量
一 编程语言介绍(***) 1.1机器语言:直接用计算机能理解的二进制指令编写程序,直接控制硬件 优点:执行效率高,跨平台性低 缺点:开发效率低 1.2汇编语言:用英文标签取代二进制指令编写程序,本质 ...
- js实现两种排序算法——冒泡、快速排序
* 一:冒牌排序1思想:冒泡排序思想:每一次对比相邻两个数据的大小,小的排在前面,如果前面的数据比后面的大就交换这两个数的位置要实现上述规则需要用到两层for循环,外层从第一个数到倒数第二个数,内层从 ...
- ASP.NET的路由系统:路由映射
总的来说,我们可以通过RouteTable的静态属性Routes得到一个基于应用的全局路由表,通过上面的介绍我们知道这是一个类型的RouteCollection的集合对象,我们可以通过调用它的MapP ...
- 对象的宽度、top位置,x坐标属性
DOM对象 DOM对象属性 对应css 说明 读/写 width obj.clientWidth=20 1. 内联样式 <p style="width:20px"&g ...
- IOS UINavigationController 更改返回按钮
UIButton *back = [UIButton buttonWithType:UIButtonTypeCustom]; back.titleLabel.font = [UIFont boldSy ...
- Oracle_plsql_开发工具搭建最小化客户端
一:资源下载获取路径: 二:配置方法 1:前提是安装好plsql开发工具 具体安装步骤略 2:配置 简化版的客户端工具. 具体格式:可以参照下文来修改编写使用. orcl_1521 = (DESCRI ...
- 断路器Feign
Feign是自带断路器,需要在配置文件中开启断路器 改造消费者项目(FeignDemo) 1.在application.yml配置文件中开启断路器 eureka: client: service-ur ...