MapReduce-WordCount
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>hadoop</groupId>
<artifactId>root</artifactId>
<version>1.0-SNAPSHOT</version> <dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.9.2</version>
</dependency>
</dependencies> <repositories>
<repository>
<id>alimaven</id>
<name>aliyun maven</name>
<url>https://maven.aliyun.com/repository/central</url>
</repository>
</repositories> <build>
<plugins>
<!-- 指定jdk -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<encoding>UTF-8</encoding>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
Code
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.log4j.BasicConfigurator; import java.io.IOException; public class WordcountDriver { static {
try {
// 设置 HADOOP_HOME 环境变量
System.setProperty("hadoop.home.dir", "D:/DevelopTools/hadoop-2.9.2/");
// 日志初始化
BasicConfigurator.configure();
// 加载库文件
System.load("D:/DevelopTools/hadoop-2.9.2/bin/hadoop.dll");
// System.out.println(System.getProperty("java.library.path"));
// System.loadLibrary("hadoop.dll");
} catch (UnsatisfiedLinkError e) {
System.err.println("Native code library failed to load.\n" + e);
System.exit(1);
}
} public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
// 获取Job对象
Job job = Job.getInstance(conf);
// 设置 jar 存储位置
job.setJarByClass(WordcountDriver.class);
// 关联 Map 和 Reduce 类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
// 设置 Mapper 阶段输出数据的 key 和 value 类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置最终数据输出(不一定是 Mapper 的输出)的 key 和 value 类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 手动设置输入路径和输出路径,注意输出路径不能为已存在的文件夹
args = new String[]{"D://tmp/123.txt", "D://tmp/456/"};
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交job
// job.submit();
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
} // Map 阶段
// 前两个参数为输入数据 k-v 的类型
// 后两个参数为输出数据 k-v 的类型
class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { Text k = new Text();
IntWritable v = new IntWritable(1); // 多少行数据执行多少次 Map
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 获取一行
String line = value.toString();
// 以空格分割
String[] words = line.split(" ");
// 循环写出,k 为单词,v 为 1
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
} // Reducer 阶段
// 前两个参数为输入数据的 k-v 类型,即 Map 阶段输出数据的 k-v类型
// 后两个参数为输出数据的 k-v 类型
class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { IntWritable v = new IntWritable(); @Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
// 累加求和,把相同单词的 v 值相加
for (IntWritable value : values) {
sum += value.get();
}
v.set(sum);
context.write(key, v);
}
}
本地运行
input(123.txt)
aa aa bb aa xx xx cc cc
11 22 55 qs dd ds ds ds
ww ee rr tt yy ff gg hh
12 ads aa ss xx zz cc qq
we 12 23 sd fc gb gb dd
212as asd 212as ads we
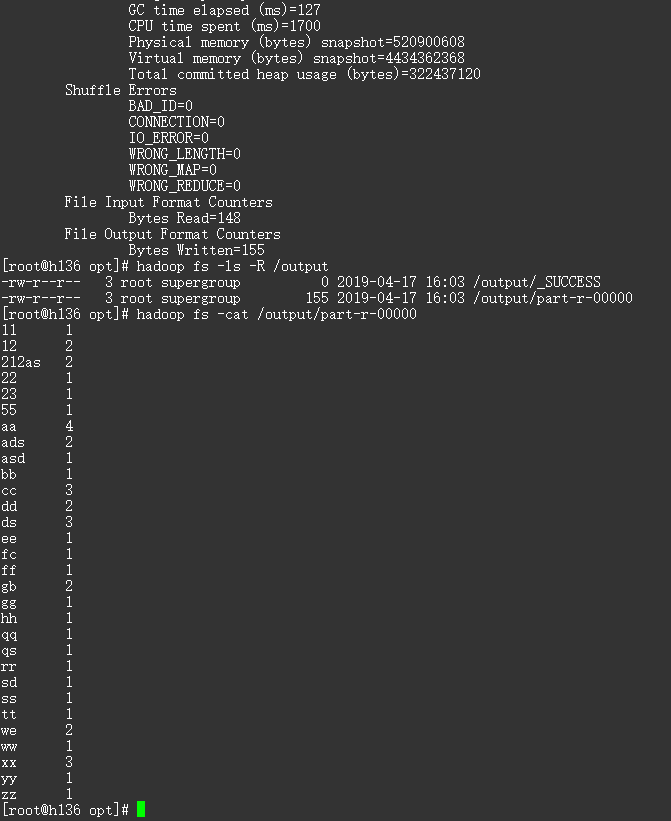
output(part-r-00000)
11 1
12 2
212as 2
22 1
23 1
55 1
aa 4
ads 2
asd 1
bb 1
cc 3
dd 2
ds 3
ee 1
fc 1
ff 1
gb 2
gg 1
hh 1
qq 1
qs 1
rr 1
sd 1
ss 1
tt 1
we 2
ww 1
xx 3
yy 1
zz 1
打包在集群上运行
使用 maven-assembly-plugin 打包,使用方法:http://maven.apache.org/components/plugins/maven-assembly-plugin/usage.html
在 pom 中添加打包插件
<!-- 打包 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.1.1</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<!-- 启动入口 -->
<mainClass>com.mapreduce.wordcount.WordcountDriver</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
删除原来写死的输入输出路径和环境设置,注释掉如下几行代码
System.setProperty("hadoop.home.dir", "D:/DevelopTools/hadoop-2.9.2/");
System.load("D:/DevelopTools/hadoop-2.9.2/bin/hadoop.dll");
args = new String[]{"D://tmp/123.txt", "D://tmp/456/"};
在项目根目录执行打包命令 mvn clean install,或直接点击 install
执行完后会生成两个文件
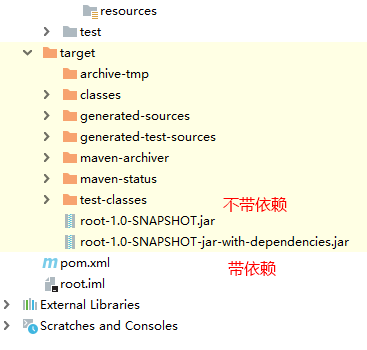
由于集群上已有环境,选择不带依赖 jar 包的即可,拷贝到集群执行
# 上传输入文件至 hdfs
hadoop fs -put 123.txt / # 运行
hadoop jar root-1.0-SNAPSHOT.jar com.mapreduce.wordcount.WordcountDriver /123.txt /output/ # 查看生成文件
hadoop fs -ls -R /output # 查看结果
hadoop fs -cat /output/part-r-00000
MapReduce-WordCount的更多相关文章
- MapReduce WordCount Combiner程序
MapReduce WordCount Combiner程序 注意使用Combiner之后的累加情况是不同的: pom.xml <project xmlns="http://maven ...
- [b0004] Hadoop 版hello word mapreduce wordcount 运行
目的: 初步感受一下hadoop mapreduce 环境: hadoop 2.6.4 1 准备输入文件 paper.txt 内容一般为英文文章,随便弄点什么进去 hadoop@ssmaster:~$ ...
- [b0013] Hadoop 版hello word mapreduce wordcount 运行(三)
目的: 不用任何IDE,直接在linux 下输入代码.调试执行 环境: Linux Ubuntu Hadoop 2.6.4 相关: [b0012] Hadoop 版hello word mapred ...
- [b0012] Hadoop 版hello word mapreduce wordcount 运行(二)
目的: 学习Hadoop mapreduce 开发环境eclipse windows下的搭建 环境: Winows 7 64 eclipse 直接连接hadoop运行的环境已经搭建好,结果输出到ecl ...
- Hadoop2.2.0 第一步完成MapReduce wordcount计算文本数量
1.完成Hadoop2.2.0单机版环境搭建之后需要利用一个例子程序来检验hadoop2 的mapreduce的功能 //启动hdfs和yarn sbin/start-dfs.sh sbin/star ...
- hadoop之MapReduce WordCount分析
MapReduce的设计思想 主要的思想是分而治之(divide and conquer),分治算法. 将一个大的问题切分成很多小的问题,然后在集群中的各个节点上执行,这既是Map过程.在Map过程结 ...
- Python初次实现MapReduce——WordCount
前言 Hadoop 本身是用 Java 开发的,所以之前的MapReduce代码小练都是由Java代码编写,但是通过Hadoop Streaming,我们可以使用任意语言来编写程序,让Hadoop 运 ...
- Python实现MapReduce,wordcount实例,MapReduce实现两表的Join
Python实现MapReduce 下面使用mapreduce模式实现了一个简单的统计日志中单词出现次数的程序: from functools import reduce from multiproc ...
- MapReduce wordcount 输入路径为目录 java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$POSIX.stat(Ljava/lang/String;)Lorg/apache/hadoop/io/nativeio/NativeIO$POSIX$Stat;
之前windows下执行wordcount都正常,今天执行的时候指定的输入路径是文件夹,然后就报了如题的错误,把输入路径改成文件后是正常的,也就是说目前的wordcount无法对多个文件操作 报的异常 ...
- Java实现MapReduce Wordcount案例
先改pom.xml: <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://ww ...
随机推荐
- 【BZOJ3669】【NOI2014】魔法森林 LCT
题目描述 给你一个\(n\)个点\(m\)条边的图,每条边有两个边权\(a,b\).请你找出从\(1\)到\(n\)一条路径,使得这条路径上边权\(a\)的最大值\(+\)边权\(b\)的最大值最小. ...
- git errot
常用 git 基础命令 1.错误信息 使用TortoiseGit执行pull命令时显示 git.exe pull --progress --no-rebase -v "origin" ...
- MT【271】一道三角最值问题
若不等式$k\sin^2B+\sin A\sin C>19\sin B\sin C$对任意$\Delta ABC$都成立,则$k$的最小值为_____ 分析:由正弦定理得$k>\dfrac ...
- thusc2017
巧克力 题目描述 "人生就像一盒巧克力,你永远不知道吃到的下一块是什么味道." 明明收到了一大块巧克力,里面有若干小块,排成
- 【题解】 bzoj2462: [BeiJing2011]矩阵模板
题面戳我 Solution 二维矩阵\(hash\),判断即可 自己YY了一个方法,\(bzoj\)T到飞,(一开始还用的三\(hash\)),交到luogu貌似跑的不慢啊qwq (我是不会告诉你全输 ...
- 【CF487E】Tourists(圆方树)
[CF487E]Tourists(圆方树) 题面 UOJ 题解 首先我们不考虑修改,再来想想这道题目. 我们既然要求的是最小值,那么,在经过一个点双的时候,走的一定是具有较小权值的那一侧. 所以说,我 ...
- Bootloader升级方式一————擦、写flash在RAM中运行
在汽车ECU软件运行中,软件代码运行安全性是第一,在代码中尽可能的不要固化有flash_erase.flash_write操作存在,主要是防止当出现异常情况时,程序跑飞,误调用erase.write对 ...
- highstock+websocket实现动态展现
效果:从后台获取回测数据,在前端动态展现,和聚宽实现的回测效果相仿 大体思路:先传一个[[int,0],[int,0],[int,0],[int,0],[int,0],...]格式的死数据到前端渲染x ...
- A1119. Pre- and Post-order Traversals
Suppose that all the keys in a binary tree are distinct positive integers. A unique binary tree can ...
- A1072. Gas Station
A gas station has to be built at such a location that the minimum distance between the station and a ...