Python初次实现MapReduce——WordCount
前言
Hadoop 本身是用 Java 开发的,所以之前的MapReduce代码小练都是由Java代码编写,但是通过Hadoop Streaming,我们可以使用任意语言来编写程序,让Hadoop 运行。
本文用Python语言实现了词频统计功能,最后通过Hadoop Streaming使其运行在Hadoop上。
Python写MapReduce代码
使用Python写MapReduce的“诀窍”是利用Hadoop流的API,通过STDIN(标准输入)、STDOUT(标准输出)在Map函数和Reduce函数之间传递数据。
我们唯一需要做的是利用Python的sys.stdin读取输入数据,并把我们的输出传送给sys.stdout。Hadoop流将会帮助我们处理别的任何事情。
Map阶段:mapper.py
#!/usr/bin/env python3
import sys
for line in sys.stdin:
line = line.strip()
words = line.split()
for word in words:
print("%s\t%s" % (word, 1))
Reducer阶段:reducer.py
#!/usr/bin/env python3
from operator import itemgetter
import sys current_word = None
current_count = 0
word = None for line in sys.stdin:
line = line.strip()
word, count = line.split('\t', 1)
try:
count = int(count)
except ValueError: #count如果不是数字的话,直接忽略掉
continue
if current_word == word:
current_count += count
else:
if current_word:
print("%s\t%s" % (current_word, current_count))
current_count = count
current_word = word if word == current_word: #最后一个单词
print("%s\t%s" % (current_word, current_count))
python代码放在本地即可,不需上传到HDFS。由于后面需要执行这两段代码,所以为它们增加可执行权限,即:
chmod +x mapper.py
chmod +x reducer.py
本地测试
用Hadoop Streaming的好处之一就是因为代码没有库的依赖,调试方便,可以脱离Hadoop先在本地用管道模拟调试,所以我们先在本地进行测试。
mapper.py

reducer.py

Hadoop运行
数据准备
测试文件in.txt文件内容为:
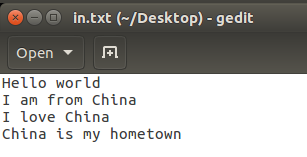
需要将其上传至HDFS,上传命令为:
bin/hadoop -copyFromLocal in.txt in.txt
Hadoop Streaming简介
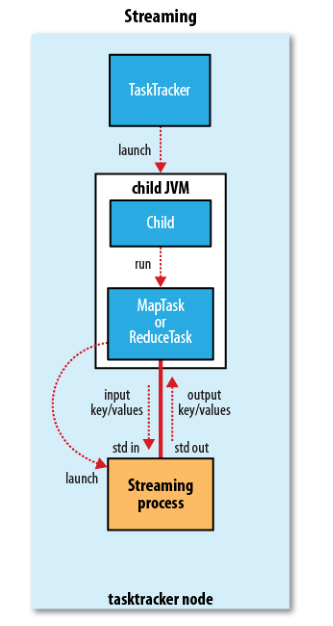
Hadoop Streaming框架,最大的好处是,让任何语言编写的map, reduce程序能够在hadoop集群上运行,map/reduce程序只要遵循从标准输入stdin读,写出到标准输出stdout即可。
它通过将其他语言编写的 mapper 和 reducer 通过参数传给一个事先写好的 Java 程序(Hadoop 自带的 *-streaming.jar),这个 Java 程序会负责创建 MR 作业,另开一个进程来运行 mapper,将得到的输入通过 stdin 传给它,再将 mapper 处理后输出到 stdout 的数据交给 Hadoop,经过 partition 和 sort 之后,再另开进程运行 reducer,同样通过 stdin/stdout 得到最终结果。因此,我们只需要在其他语言编写的程序中,通过 stdin 接收数据,再将处理过的数据输出到 stdout,Hadoop Streaming 就能通过这个 Java 的 wrapper 帮我们解决中间繁琐的步骤,运行分布式程序。
优点:
1. 可以使用自己喜欢的语言来编写 MapReduce 程序(不必非得使用 Java)
2. 不需要像写 Java 的 MR 程序那样 import 一大堆库,在代码里做很多配置,很多东西都抽象到了 stdio 上,代码量显著减少。
3. 因为没有库的依赖,调试方便,并且可以脱离 Hadoop 先在本地用管道模拟调试。
缺点:
1. 只能通过命令行参数来控制 MapReduce 框架,不像 Java 的程序那样可以在代码里使用 API,控制力比较弱。
2. 因为中间隔着一层处理,效率会比较慢。
3. 所以 Hadoop Streaming 比较适合做一些简单的任务,比如用 Python 写只有一两百行的脚本。如果项目比较复杂,或者需要进行比较细致的优化,使用 Streaming 就容易出现一些束手束脚的地方。
Hadoop Streaming运行
首先需要找到hadoop-streaming的位置,我的hadoop是2.x版本的,该包的位置在:
在执行的过程中遇到了权限不够的问题:

解决办法是扩大权限:

为了方便起见,接下来我就把hadoop-streaming-2.9.2.jar放在了/usr/local/hadoop目录下,所以在下面的命令中大家注意一下。
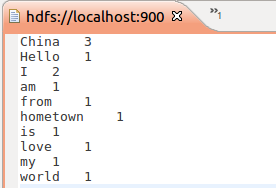
最后输入如下命令:
bin/hadoop jar /usr/local/hadoop/hadoop-streaming-2.9.2.jar\
-mapper /usr/local/hadoop/mapper.py\
-file /usr/local/hadoop/mapper.py\
-reducer /usr/local/hadoop/reducer.py\
-file /usr/local/hadoop/reducer.py\
-input in.txt\
-output out
第一行是告诉Hadoop运行Streaming的Jav 程序,后面的mapper.py 和 reducer.py 是 mapper 所对应 Python 程序的路径。为了让Hadoop 将程序分发给其他机器,需要再加一个 -file 参数用于指明要分发的程序放在哪里。

Python代码优化
使用 Python 编写 Hadoop Streaming 时,在能使用 iterator 的情况下,尽量使用 iterator,避免将 stdin 的输入大量储存在内存里,否则会严重降低性能。
参考:
[1] 用python写MapReduce函数——以WordCount为例
[2] 使用Python实现Hadoop MapReduce程序
[5] 使用hadoop-streaming初体验mapreduce
[6] 使用python+hadoop-streaming编写hadoop处理程序
Python初次实现MapReduce——WordCount的更多相关文章
- Python实现MapReduce,wordcount实例,MapReduce实现两表的Join
Python实现MapReduce 下面使用mapreduce模式实现了一个简单的统计日志中单词出现次数的程序: from functools import reduce from multiproc ...
- 使用Python实现Hadoop MapReduce程序
转自:使用Python实现Hadoop MapReduce程序 英文原文:Writing an Hadoop MapReduce Program in Python 根据上面两篇文章,下面是我在自己的 ...
- [python]使用python实现Hadoop MapReduce程序:计算一组数据的均值和方差
这是参照<机器学习实战>中第15章“大数据与MapReduce”的内容,因为作者写作时hadoop版本和现在的版本相差很大,所以在Hadoop上运行python写的MapReduce程序时 ...
- MapReduce WordCount Combiner程序
MapReduce WordCount Combiner程序 注意使用Combiner之后的累加情况是不同的: pom.xml <project xmlns="http://maven ...
- [b0004] Hadoop 版hello word mapreduce wordcount 运行
目的: 初步感受一下hadoop mapreduce 环境: hadoop 2.6.4 1 准备输入文件 paper.txt 内容一般为英文文章,随便弄点什么进去 hadoop@ssmaster:~$ ...
- [b0013] Hadoop 版hello word mapreduce wordcount 运行(三)
目的: 不用任何IDE,直接在linux 下输入代码.调试执行 环境: Linux Ubuntu Hadoop 2.6.4 相关: [b0012] Hadoop 版hello word mapred ...
- [b0012] Hadoop 版hello word mapreduce wordcount 运行(二)
目的: 学习Hadoop mapreduce 开发环境eclipse windows下的搭建 环境: Winows 7 64 eclipse 直接连接hadoop运行的环境已经搭建好,结果输出到ecl ...
- Hadoop2.2.0 第一步完成MapReduce wordcount计算文本数量
1.完成Hadoop2.2.0单机版环境搭建之后需要利用一个例子程序来检验hadoop2 的mapreduce的功能 //启动hdfs和yarn sbin/start-dfs.sh sbin/star ...
- hadoop之MapReduce WordCount分析
MapReduce的设计思想 主要的思想是分而治之(divide and conquer),分治算法. 将一个大的问题切分成很多小的问题,然后在集群中的各个节点上执行,这既是Map过程.在Map过程结 ...
随机推荐
- [转]GO 开发rest api 接口
注明出处:https://blog.csdn.net/haowenqi008/article/details/79150705 最近在研究Go,打算基于Go做点Web API,于是经过初步调研,打算用 ...
- 学号20175313 《Arrays和String单元测试》第八周
目录 Arrays和String单元测试 一.String类相关方法的单元测试 二.Arrays类相关方法的单元测试 三.测试过程中遇到的问题及其解决方法 四.码云链接 五.参考资料 Arrays和S ...
- ADB——adb devices unauthorized
我们只有在手机打开USB调试,并且允许电脑对其进行调试的前提下才可以用ADB进行自动化操作手机,如果出现unauthorized提示的话就是说明手机没有允许电脑对其调试 这个时候通常手机回弹出允许调试 ...
- vghyj
2017*****1012:我是康迪:我的爱好是计算机:我的码云个人主页是:https://gitee.com/kdkdkdkd我的第一个项目地址是:https://gitee.com/kdkdkdk ...
- java深拷贝的实现
深拷贝实现的工具类 package com.Utils; import java.io.ByteArrayInputStream; import java.io.ByteArrayOutputStre ...
- java实现栈的简单操作
public class stract { public static void main(String[] args) { MyStack stack = new MyStack(20); stac ...
- redis----------基本命令使用
1.查看全部缓存数据的key keys * 2.清空当前redis数据库缓存 flushdb (redis默认由16个库(0~15号). 且默认使用的是0号库.库之间的切换使用select命令例如: ...
- [python 练习] 计算个税
题目:利用python计算个税 说明:python有序字典的使用 代码: # -*- coding: utf-8 -*- from collections import OrderedDict # 税 ...
- elastic-job集成到springboot教程,和它的一个异常处理办法:Sharding item parameters '1' format error, should be int=xx,int=xx
先说这个Sharding item parameters '1' format error, should be int=xx,int=xx异常吧,这是在做动态添加调度任务的时候出现的,网上找了一会没 ...
- logback 按时间和大小生成日志不生效的问题
服务器要记录所有的日志,这些日志输入到一个文件中太大了,就需要按大小和时间还分割,比如每小时产生一个文件或当文件大小大于200MB的时候生成一个文件. 第一版这样版本,但是服务器启动之后没有生成日志文 ...