MapReduce-WordCount
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>hadoop</groupId>
<artifactId>root</artifactId>
<version>1.0-SNAPSHOT</version> <dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.9.2</version>
</dependency>
</dependencies> <repositories>
<repository>
<id>alimaven</id>
<name>aliyun maven</name>
<url>https://maven.aliyun.com/repository/central</url>
</repository>
</repositories> <build>
<plugins>
<!-- 指定jdk -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<encoding>UTF-8</encoding>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
Code
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.log4j.BasicConfigurator; import java.io.IOException; public class WordcountDriver { static {
try {
// 设置 HADOOP_HOME 环境变量
System.setProperty("hadoop.home.dir", "D:/DevelopTools/hadoop-2.9.2/");
// 日志初始化
BasicConfigurator.configure();
// 加载库文件
System.load("D:/DevelopTools/hadoop-2.9.2/bin/hadoop.dll");
// System.out.println(System.getProperty("java.library.path"));
// System.loadLibrary("hadoop.dll");
} catch (UnsatisfiedLinkError e) {
System.err.println("Native code library failed to load.\n" + e);
System.exit(1);
}
} public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
// 获取Job对象
Job job = Job.getInstance(conf);
// 设置 jar 存储位置
job.setJarByClass(WordcountDriver.class);
// 关联 Map 和 Reduce 类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
// 设置 Mapper 阶段输出数据的 key 和 value 类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置最终数据输出(不一定是 Mapper 的输出)的 key 和 value 类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 手动设置输入路径和输出路径,注意输出路径不能为已存在的文件夹
args = new String[]{"D://tmp/123.txt", "D://tmp/456/"};
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交job
// job.submit();
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
} // Map 阶段
// 前两个参数为输入数据 k-v 的类型
// 后两个参数为输出数据 k-v 的类型
class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { Text k = new Text();
IntWritable v = new IntWritable(1); // 多少行数据执行多少次 Map
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 获取一行
String line = value.toString();
// 以空格分割
String[] words = line.split(" ");
// 循环写出,k 为单词,v 为 1
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
} // Reducer 阶段
// 前两个参数为输入数据的 k-v 类型,即 Map 阶段输出数据的 k-v类型
// 后两个参数为输出数据的 k-v 类型
class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { IntWritable v = new IntWritable(); @Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
// 累加求和,把相同单词的 v 值相加
for (IntWritable value : values) {
sum += value.get();
}
v.set(sum);
context.write(key, v);
}
}
本地运行
input(123.txt)
aa aa bb aa xx xx cc cc
11 22 55 qs dd ds ds ds
ww ee rr tt yy ff gg hh
12 ads aa ss xx zz cc qq
we 12 23 sd fc gb gb dd
212as asd 212as ads we
output(part-r-00000)
11 1
12 2
212as 2
22 1
23 1
55 1
aa 4
ads 2
asd 1
bb 1
cc 3
dd 2
ds 3
ee 1
fc 1
ff 1
gb 2
gg 1
hh 1
qq 1
qs 1
rr 1
sd 1
ss 1
tt 1
we 2
ww 1
xx 3
yy 1
zz 1
打包在集群上运行
使用 maven-assembly-plugin 打包,使用方法:http://maven.apache.org/components/plugins/maven-assembly-plugin/usage.html
在 pom 中添加打包插件
<!-- 打包 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.1.1</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<!-- 启动入口 -->
<mainClass>com.mapreduce.wordcount.WordcountDriver</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
删除原来写死的输入输出路径和环境设置,注释掉如下几行代码
System.setProperty("hadoop.home.dir", "D:/DevelopTools/hadoop-2.9.2/");
System.load("D:/DevelopTools/hadoop-2.9.2/bin/hadoop.dll");
args = new String[]{"D://tmp/123.txt", "D://tmp/456/"};
在项目根目录执行打包命令 mvn clean install,或直接点击 install
执行完后会生成两个文件
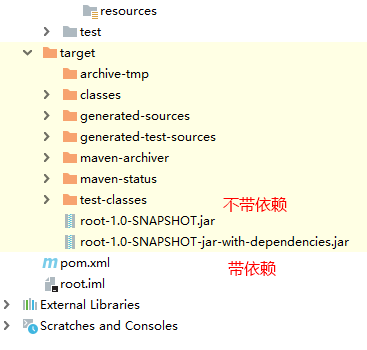
由于集群上已有环境,选择不带依赖 jar 包的即可,拷贝到集群执行
# 上传输入文件至 hdfs
hadoop fs -put 123.txt / # 运行
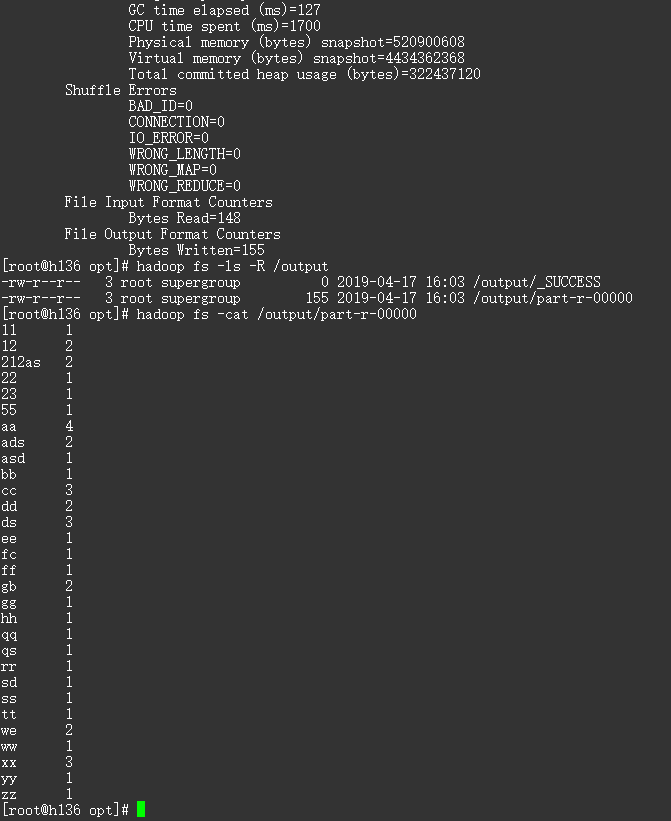
hadoop jar root-1.0-SNAPSHOT.jar com.mapreduce.wordcount.WordcountDriver /123.txt /output/ # 查看生成文件
hadoop fs -ls -R /output # 查看结果
hadoop fs -cat /output/part-r-00000
MapReduce-WordCount的更多相关文章
- MapReduce WordCount Combiner程序
MapReduce WordCount Combiner程序 注意使用Combiner之后的累加情况是不同的: pom.xml <project xmlns="http://maven ...
- [b0004] Hadoop 版hello word mapreduce wordcount 运行
目的: 初步感受一下hadoop mapreduce 环境: hadoop 2.6.4 1 准备输入文件 paper.txt 内容一般为英文文章,随便弄点什么进去 hadoop@ssmaster:~$ ...
- [b0013] Hadoop 版hello word mapreduce wordcount 运行(三)
目的: 不用任何IDE,直接在linux 下输入代码.调试执行 环境: Linux Ubuntu Hadoop 2.6.4 相关: [b0012] Hadoop 版hello word mapred ...
- [b0012] Hadoop 版hello word mapreduce wordcount 运行(二)
目的: 学习Hadoop mapreduce 开发环境eclipse windows下的搭建 环境: Winows 7 64 eclipse 直接连接hadoop运行的环境已经搭建好,结果输出到ecl ...
- Hadoop2.2.0 第一步完成MapReduce wordcount计算文本数量
1.完成Hadoop2.2.0单机版环境搭建之后需要利用一个例子程序来检验hadoop2 的mapreduce的功能 //启动hdfs和yarn sbin/start-dfs.sh sbin/star ...
- hadoop之MapReduce WordCount分析
MapReduce的设计思想 主要的思想是分而治之(divide and conquer),分治算法. 将一个大的问题切分成很多小的问题,然后在集群中的各个节点上执行,这既是Map过程.在Map过程结 ...
- Python初次实现MapReduce——WordCount
前言 Hadoop 本身是用 Java 开发的,所以之前的MapReduce代码小练都是由Java代码编写,但是通过Hadoop Streaming,我们可以使用任意语言来编写程序,让Hadoop 运 ...
- Python实现MapReduce,wordcount实例,MapReduce实现两表的Join
Python实现MapReduce 下面使用mapreduce模式实现了一个简单的统计日志中单词出现次数的程序: from functools import reduce from multiproc ...
- MapReduce wordcount 输入路径为目录 java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$POSIX.stat(Ljava/lang/String;)Lorg/apache/hadoop/io/nativeio/NativeIO$POSIX$Stat;
之前windows下执行wordcount都正常,今天执行的时候指定的输入路径是文件夹,然后就报了如题的错误,把输入路径改成文件后是正常的,也就是说目前的wordcount无法对多个文件操作 报的异常 ...
- Java实现MapReduce Wordcount案例
先改pom.xml: <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://ww ...
随机推荐
- Go语言变量和常量
一.变量相关 1.变量声明 C# : int a; Go : var a int; 需要在前面加一个var关键字,后面定义类型 可以使用 var( a int; b string;)减少var 2.变 ...
- POJ 2352 树状数组
学习自:链接以及百度百科 以及:https://www.bilibili.com/video/av18735440?from=search&seid=363548948825132979 理解 ...
- MT【154】拉格朗日配方
(清华2017.4.29标准学术能力测试24) 设$x,y\in\mathbb{R}$,函数$f(x,y)=x^2+6y^2-2xy-14x-6y+72$的值域为$M$,则______ A.$1\in ...
- [国家集训队]排队 [cdq分治]
题面 洛谷 和动态逆序对那道题没有什么区别 把一个交换换成两个删除和两个插入 #include <cstdio> #include <cstdlib> #include < ...
- Android 9.png图片的制作方法
在Android的设计过程中,为了适配不同的手机分辨率,图片大多需要拉伸或者压缩,这样就出现了可以任意调整大小的一种图片格式".9.png".这种图片是用于Android开发的一种 ...
- Codeforces | CF1010C 【Border】
这道题大致题意是给定\(n\)个十进制整数和一个进制数\(k\),可以用无数多个给定的十进制整数,问这些十进制整数的和在模k意义下有多少种不同的结果(\(k\)进制下整数的最后一位就是这个数模\(k\ ...
- 转----ui输入测试数据
jin'tHackChecker黑测工作室 - 专注于软件安全测试技术研究!(www.AutomationQA.com)常用安全测试用例 建立整体的威胁模型,测试溢出漏洞.信息泄漏.错误处理.SQL ...
- HDU6333 Harvest of Apples (杭电多校4B)
这莫队太强啦 先推公式S(n,m)表示从C(n, 0) 到 C(n, m)的总和 1.S(n, m) = S(n, m-1) + C(n, m) 这个直接可以转移得到 2.S(n, m) = ...
- LaTeX教程与下载
LaTeX教程与下载如下: 其实,下载好CTEX 的步骤只有三步.第一步下载好CTEX ,第二步下载编辑器Texstudio ,第三步安装配置TexStudio 详细步骤: 第一步:下载CTEX La ...
- hdu3038How Many Answers Are Wrong(带权并查集)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=3038 题解转载自:https://www.cnblogs.com/liyinggang/p/53270 ...