【底层原理】深入理解Cache (上)
存储器是分层次的,离CPU越近的存储器,速度越快,每字节的成本越高,同时容量也因此越小。寄存器速度最快,离CPU最近,成本最高,所以个数容量有限,其次是高速缓存(缓存也是分级,有L1,L2等缓存),再次是主存(普通内存),再次是本地磁盘。
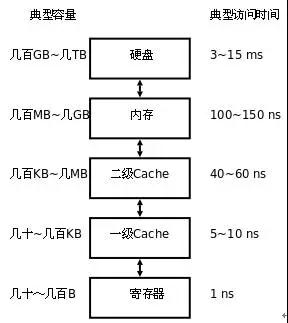
寄存器的速度最快,可以在一个时钟周期内访问,其次是高速缓存,可以在几个时钟周期内访问,普通内存可以在几十个或几百个时钟周期内访问。

存储器分级,利用的是局部性原理。我们可以以经典的阅读书籍为例。我在读的书,捧在手里(寄存器),我最近频繁阅读的书,放在书桌上(缓存),随时取来读。当然书桌上只能放有限几本书。我更多的书在书架上(内存)。如果书架上没有的书,就去图书馆(磁盘)。我要读的书如果手里没有,那么去书桌上找,如果书桌上没有,去书架上找,如果书架上没有去图书馆去找。可以对应寄存器没有,则从缓存中取,缓存中没有,则从内存中取到缓存,如果内存中没有,则先从磁盘读入内存,再读入缓存,再读入寄存器。
本系列的文章重点介绍缓存cache。了解如何获取cache的参数,了解缓存的组织结构,了解cache对程序的影响,了解如何利用cache提升性能。
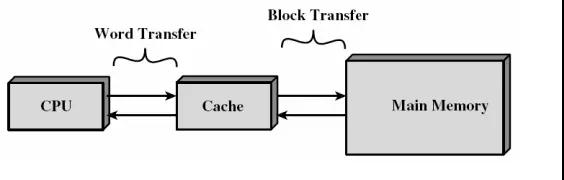
本文作为系列文章的第一篇,讲述的如何获取cache的组成结构和如何获取cache的参数。
cache分成多个组,每个组分成多个行,linesize是cache的基本单位,从主存向cache迁移数据都是按照linesize为单位替换的。比如linesize为32Byte,那么迁移必须一次迁移32Byte到cache。 这个linesize比较容易理解,想想我们前面书的例子,我们从书架往书桌搬书必须以书为单位,肯定不能把书撕了以页为单位。书就是linesize。当然了现实生活中每本书页数不同,但是同个cache的linesize总是相同的。
所谓8路组相连( 8-way set associative)的含义是指,每个组里面有8个行。
我们知道,cache的容量要远远小于主存,主存和cache肯定不是一一对应的,那么主存中的地址和cache的映射关系是怎样的呢?
拿到一个地址,首先是映射到一个组里面去。如何映射?取内存地址的中间几位来映射。
举例来说,data cache: 32-KB, 8-way set associative, 64-byte line size表示Cache总大小为32KB,8路组相连(每组有8个line),每个line的大小linesize为64Byte,OK,我们可以很轻易的算出一共有32K/8/64=64 个组。
对于32位的内存地址,每个line有2^6 = 64Byte,所以地址的【0,5】区分line中的那个字节。一共有64个组。我们取内存地址中间6为来hash查找地址属于那个组。即内存地址的【6,11】位来确定属于64组的哪一个组。组确定了之后,【12,31】的内存地址与组中8个line挨个比对,如果【12,31】为与某个line一致,并且这个line为有效,那么缓存命中。
OK,cache分成三类:
- 直接映射高速缓存,这个简单,即每个组只有一个line,选中组之后不需要和组中的每个line比对,因为只有一个line。
- 组相联高速缓存,这个就是我们前面介绍的cache。 S个组,每个组E个line。
- 全相联高速缓存,这个简单,只有一个组,就是全相联。不用hash来确定组,直接挨个比对高位地址,来确定是否命中。可以想见这种方式不适合大的缓存。想想看,如果4M 的大缓存
描述一个cache需要以下参数:
- cache分级,L1 cache, L2 cache, L3 cache,级别越低,离cpu越近
- cache的容量
- cache的linesize
- cache 每组的行个数.
组的个数完全可以根据上面的参数计算出来,所以没有列出来.Intel手册中用这样的句子来描述cache:8-MB L3 Cache, 16-way set associative, 64-byte line size ,如何获取cache的参数呢,到了我们的老朋友cpuid指令,当eax为0x2的时候,cpuid指令获取到cache的参数. 下面给出代码:


我的电脑上运行结果如上图,查看intel的手册可知

【底层原理】深入理解Cache (上)的更多相关文章
- 【底层原理:深入理解计算机系统】#1 一切从"hello world"说起 (一)
计算机系统是由硬件和系统软件组成的,他们共同工作来运行应用程序.虽然系统的具体实现方式随着时间不断的在变化,但是系统的内在概念却没有改变的. 所有的计算机硬件和软件有着相似的结构和功能.这个系列专题便 ...
- 理解java容器底层原理--手动实现HashMap
HashMap结构 HashMap的底层是数组+链表,百度百科找了张图: 先写个链表节点的类 package com.xzlf.collection2; public class Node { int ...
- Linux从头学06:16张结构图,彻底理解【代码重定位】的底层原理
作 者:道哥,10+年的嵌入式开发老兵. 公众号:[IOT物联网小镇],专注于:C/C++.Linux操作系统.应用程序设计.物联网.单片机和嵌入式开发等领域. 公众号回复[书籍],获取 Linux. ...
- 【T-SQL进阶】02.理解SQL查询的底层原理
本系列[T-SQL]主要是针对T-SQL的总结. [T-SQL基础]01.单表查询-几道sql查询题 [T-SQL基础]02.联接查询 [T-SQL基础]03.子查询 [T-SQL基础]04.表表达式 ...
- 理解SQL查询的底层原理
阅读目录 一.SQL Server组成部分 二.查询的底层原理 本系列[T-SQL]主要是针对T-SQL的总结. T-SQL基础 [T-SQL基础]01.单表查询-几道sql查询题 [T-SQL基础] ...
- 并发之volatile底层原理
15.深入分析Volatile的实现原理 14.java多线程编程底层原理剖析以及volatile原理 13.Java中Volatile底层原理与应用 12.Java多线程-java.util.con ...
- MVC底层原理
窥探ASP.Net MVC底层原理 实现跨越Session的分布式TempData 1.问题的引出 我相信大家在项目中都使用过TempData,TempData是一个字典集合,一般用于两个请求之间临时 ...
- 抛开 Spring ,你知道 MyBatis 加载 Mapper 的底层原理吗?
原文链接:抛开 Spring ,你知道 MyBatis 加载 Mapper 的底层原理吗? 大家都知道,利用 Spring 整合 MyBatis,我们可以直接利用 @MapperScan 注解或者 @ ...
- HBase 底层原理详解(深度好文,建议收藏)
HBase简介 HBase 是一个分布式的.面向列的开源数据库.建立在 HDFS 之上.Hbase的名字的来源是 Hadoop database,即 Hadoop 数据库.HBase 的计算和存储能力 ...
- Neo4j图数据库简介和底层原理
现实中很多数据都是用图来表达的,比如社交网络中人与人的关系.地图数据.或是基因信息等等.RDBMS并不适合表达这类数据,而且由于海量数据的存在,让其显得捉襟见肘.NoSQL数据库的兴起,很好地解决了海 ...
随机推荐
- MFC编程之数值调节按钮
MFC编程之数值调节按钮 一丶数值调节按钮使用的注意事项 CSpinButtonCtrl类是MFC封装的数值调节按钮. 我们要使用数值调节按钮需要注意的事项. 1.数值调节按钮跟一个编辑框配合使用. ...
- ARM 处理器寻址方式之间接寻址的几种表达
我们以 LDR 指令为例来分别举例分析. LDR 指令的格式为: LDR{条件} 目的寄存器,<存储器地址> LDR 指令是字加载指令,用于从存储器中将一个 32 位的字数据送到目的寄存器 ...
- IE的浏览器模式、文本模式
最近在部署网页的时候,发现IE下的布局完成混乱. 在改变IE的文本模式后,显示就正常了. IE的浏览器模式,用于切换IE针对该网页的默认文本模式.对不同版本浏览器的条件注释解析.决定请求头里userA ...
- C- unsigned :1之位域分析
1.首先回忆结构体 我们都知道定义一个结构体可以这样的方式定义: struct Point { float x; float y; } point; //等价于: struct Point point ...
- JSJ—案例谈面向对象
有人告诉我那里遍地都是对象——我们把所有的程序代码放在main()里面,事实上,那根本就不是面向对象的做法,在Java的面向对象中,我们也会看到类和对象的不同,以及对象是如何让你的生活更美好(至少程序 ...
- 如何用ftp上传静态网站到虚拟空间
ftp是一种网络传输协议,你要上传网站到空间首先你要安装一个FTP软件,你申请的空间有一个网址.账号.密码之类的,你打开FTP输入这些链接就可以准备上传网站了,软件打开有一个本地界面,还有一个空间界面 ...
- Linux 系统的安装 (最全收集)
在几年前,我曾经多次萌生抛弃Win系统,从而使用Linux系统-----(Ubuntu),但是我每次都会遇到同一个问题,TM怎么安装啊. 不是安装奇慢就是不知道安装的方法. 怎样安装Ubuntu操作系 ...
- mediainfo使用
1.linux安装mediainfo yum install mediainfo(epel源安装) 2.输出文件信息到xml文件 mediainfo --OUTPUT=XML -f ftp ...
- Android Service解析
Android Service是一个可以在后台执行长时间运行操作而不提供用户界面的应用组件,它分为两种工作状态,一种是启动状态,主要用于执行后台计算:另一种是绑定状态,主要用于其他组件和Service ...
- Java马士兵高并发编程视频学习笔记(二)
1.ReentrantLock的简单使用 Reentrant n.再进入 ReentrantLock 一个可重入互斥Lock具有与使用synchronized方法和语句访问的隐式监视锁相同的基本行为和 ...