理解java容器底层原理--手动实现HashMap
HashMap结构
HashMap的底层是数组+链表,百度百科找了张图:

先写个链表节点的类
package com.xzlf.collection2;
public class Node {
int hash;
Object key;
Object value;
Node next;
}
自定义一个HashMap,实现了put方法增加键值对,并解决了键重复的时候覆盖相应的节点
package com.xzlf.collection2;
/**
* 自定义一个hashMap
* 实现了put方法增加键值对,并解决了键重复的时候覆盖相应的节点
* @author xzlf
*
*/
public class MyHashMap {
private Node[] table;//位桶 .bucket array
private int size;//存放键值对的个数
public MyHashMap() {
table = new Node[16];//长度一般定义成2的整数次幂
}
public void put(Object key, Object value) {
Node newNode = new Node();
newNode.hash = myHash(key.hashCode(), table.length);
newNode.key = key;
newNode.value = value;
Node tmp = table[newNode.hash];
Node iterLast = null;//正在遍历的最后一个元素
boolean keyRepeat = false;
if(tmp == null) {
//此处数组元素为空,则直接将新节点放进去
table[newNode.hash] = newNode;
}else {
//此处数组元素不为空。则遍历对应链表。。
while(tmp != null) {
// 判断是否有重复的键
if(key.equals(tmp.key)) {
keyRepeat = true;
// 键重复,直接覆盖value其他的值(hash,key,next)保持不变。
tmp.value = value;
break;
}else {
iterLast = tmp;
tmp = tmp.next;
}
}
if(!keyRepeat) {
//key没有重复的情况,则添加到链表最后。
iterLast.next = newNode;
}
}
}
public static int myHash(int v, int length) {
// System.out.println(v&(length - 1));
return v&(length - 1);// 位运算把元素散列到各位位置
}
我们在写个main() 方法测试一下:
目前还没有重写toString() 方法,我们先把计算位置的方法加一条打印语句,然后在最后的输出语句加上断点,用debug模式查看
public static int myHash(int v, int length) {
System.out.println(v&(length - 1));
return v&(length - 1);// 位运算把元素散列到各位位置
}
public static void main(String[] args) {
MyHashMap map = new MyHashMap();
map.put(10, "aa");
map.put(20, "bb");
map.put(30, "cc");
System.out.println(map);
}
debug模式运行代码,控制台输出了元素存放位置:

我们看下10 4 14 位置对应的值是否对应上 aa bb cc

debug模式中可以看到添加的变量,说明数据添加进去了
我们还要测试下键重复和桶位在同一位置情况
先用以下代码,找出在存放位置为索引8(可以自己定义)的键:
for (int i = 10; i < 100; i++) {
if (myHash(i,16) == 8) {
System.out.println(i + "---" + myHash(i, 16));//24, 40,56,72,88
}
}
找出来是24, 40,56,72,88:
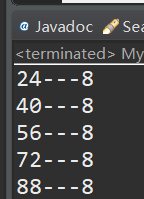
用以下代码测试键重复,和存放位置一直情况:
public static void main(String[] args) {
MyHashMap map = new MyHashMap();
map.put(10, "aa");
map.put(20, "bb");
map.put(30, "cc");
map.put(10, "ssss");
map.put(24, "dd");
map.put(56, "ee");
map.put(72, "ff");
map.put(56, "java");
System.out.println(map);
}
还是用debug模式测试:

8和10的位置都是预期效果。接下来我们可以去重写toString方法,以方便我们查看结果。
版本二:重写toString()
package com.xzlf.collection2;
/**
* 自定义一个hashMap
* 实现toString方法,方便查看Map中的键值对信息
* @author xzlf
*
*/
public class MyHashMap2 {
private Node[] table;//位桶 .bucket array
private int size;//存放键值对的个数
public MyHashMap2() {
table = new Node[16];//长度一般定义成2的整数次幂
}
public void put(Object key, Object value) {
Node newNode = new Node();
newNode.hash = myHash(key.hashCode(), table.length);
newNode.key = key;
newNode.value = value;
Node tmp = table[newNode.hash];
Node iterLast = null;//正在遍历的最后一个元素
boolean keyRepeat = false;
if(tmp == null) {
//此处数组元素为空,则直接将新节点放进去
table[newNode.hash] = newNode;
}else {
//此处数组元素不为空。则遍历对应链表。。
while(tmp != null) {
// 判断是否有重复的键
if(key.equals(tmp.key)) {
keyRepeat = true;
// 键重复,直接覆盖value其他的值(hash,key,next)保持不变。
tmp.value = value;
break;
}else {
iterLast = tmp;
tmp = tmp.next;
}
}
if(!keyRepeat) {
//key没有重复的情况,则添加到链表最后。
iterLast.next = newNode;
}
}
}
public static int myHash(int v, int length) {
// System.out.println(v&(length - 1));
return v&(length - 1);// 位运算把元素散列到各位位置
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder("{");
// 遍历位桶数组
for (int i = 0; i < table.length; i++) {
Node tmp = table[i];
//遍历链表
while(tmp != null) {
sb.append(tmp.key + ":" + tmp.value + ",");
tmp = tmp.next;
}
}
sb.setCharAt(sb.length() - 1, '}');
return sb.toString();
}
public static void main(String[] args) {
MyHashMap2 map = new MyHashMap2();
map.put(10, "aa");
map.put(20, "bb");
map.put(30, "cc");
map.put(10, "ssss");
map.put(24, "dd");
map.put(56, "ee");
map.put(72, "ff");
map.put(56, "java");
System.out.println(map);
}
}
运行测试:
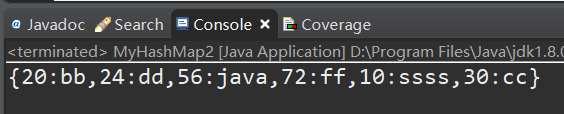
没有问题,继续添加get() 方法。
版本三:添加get方法
package com.xzlf.collection2;
/**
* 自定义一个hashMap
* 添加get方法
* @author xzlf
*
*/
public class MyHashMap3 {
private Node[] table;//位桶 .bucket array
private int size;//存放键值对的个数
public MyHashMap3() {
table = new Node[16];//长度一般定义成2的整数次幂
}
public void put(Object key, Object value) {
Node newNode = new Node();
newNode.hash = myHash(key.hashCode(), table.length);
newNode.key = key;
newNode.value = value;
Node tmp = table[newNode.hash];
Node iterLast = null;//正在遍历的最后一个元素
boolean keyRepeat = false;
if(tmp == null) {
//此处数组元素为空,则直接将新节点放进去
table[newNode.hash] = newNode;
}else {
//此处数组元素不为空。则遍历对应链表。。
while(tmp != null) {
// 判断是否有重复的键
if(key.equals(tmp.key)) {
keyRepeat = true;
// 键重复,直接覆盖value其他的值(hash,key,next)保持不变。
tmp.value = value;
break;
}else {
iterLast = tmp;
tmp = tmp.next;
}
}
if(!keyRepeat) {
//key没有重复的情况,则添加到链表最后。
iterLast.next = newNode;
}
}
}
public static int myHash(int v, int length) {
// System.out.println(v&(length - 1));
return v&(length - 1);// 位运算把元素散列到各位位置
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder("{");
// 遍历位桶数组
for (int i = 0; i < table.length; i++) {
Node tmp = table[i];
//遍历链表
while(tmp != null) {
sb.append(tmp.key + ":" + tmp.value + ",");
tmp = tmp.next;
}
}
sb.setCharAt(sb.length() - 1, '}');
return sb.toString();
}
public Object get(Object key) {
int hash = myHash(key.hashCode(), table.length);
Object value = null;
Node tmp = table[hash];
while(tmp != null) {
if(key.equals(tmp.key)) {//如果找到了,则返回对应的值
value = tmp.value;
break;
}else {
tmp = tmp.next;
}
}
return value;
}
public static void main(String[] args) {
MyHashMap3 map = new MyHashMap3();
map.put(10, "aa");
map.put(20, "bb");
map.put(30, "cc");
map.put(10, "ssss");
map.put(24, "dd");
map.put(56, "ee");
map.put(72, "ff");
map.put(56, "java");
System.out.println(map);
System.out.println(map.get(10));
System.out.println(map.get(30));
System.out.println(map.get(72));
System.out.println(map.get(78));
}
}
运行测试:

也没问题。
现在已经把hashMap的核心功能get put 实现了。
最后完善一下。
版本四:添加泛型,完善size计数
Node添加泛型:
package com.xzlf.collection2;
public class Node2<K, V> {
int hash;
K key;
V value;
Node2 next;
}
自定义hashmap添加泛型并完善size计数:
package com.xzlf.collection2;
/**
* 自定义一个hashMap
* 增加泛型,修复部分bug
* @author xzlf
*
*/
public class MyHashMap4<K, V> {
private Node2[] table;//位桶 .bucket array
private int size;//存放键值对的个数
public MyHashMap4() {
table = new Node2[16];//长度一般定义成2的整数次幂
}
public void put(K key, V value) {
Node2 newNode2 = new Node2();
newNode2.hash = myHash(key.hashCode(), table.length);
newNode2.key = key;
newNode2.value = value;
Node2 tmp = table[newNode2.hash];
Node2 iterLast = null;//正在遍历的最后一个元素
boolean keyRepeat = false;
if(tmp == null) {
//此处数组元素为空,则直接将新节点放进去
table[newNode2.hash] = newNode2;
size++;
}else {
//此处数组元素不为空。则遍历对应链表。。
while(tmp != null) {
// 判断是否有重复的键
if(key.equals(tmp.key)) {
keyRepeat = true;
// 键重复,直接覆盖value其他的值(hash,key,next)保持不变。
tmp.value = value;
break;
}else {
iterLast = tmp;
tmp = tmp.next;
}
}
if(!keyRepeat) {
//key没有重复的情况,则添加到链表最后。
iterLast.next = newNode2;
size++;
}
}
}
public static int myHash(int v, int length) {
// System.out.println(v&(length - 1));
return v&(length - 1);// 位运算把元素散列到各位位置
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder("{");
// 遍历位桶数组
for (int i = 0; i < table.length; i++) {
Node2 tmp = table[i];
//遍历链表
while(tmp != null) {
sb.append(tmp.key + ":" + tmp.value + ",");
tmp = tmp.next;
}
}
sb.setCharAt(sb.length() - 1, '}');
return sb.toString();
}
public V get(K key) {
int hash = myHash(key.hashCode(), table.length);
V value = null;
Node2 tmp = table[hash];
while(tmp != null) {
if(key.equals(tmp.key)) {//如果找到了,则返回对应的值
value = (V) tmp.value;
break;
}else {
tmp = tmp.next;
}
}
return value;
}
public static void main(String[] args) {
MyHashMap4<Integer, String> map = new MyHashMap4<>();
map.put(10, "aa");
map.put(20, "bb");
map.put(30, "cc");
map.put(10, "ssss");
map.put(24, "dd");
map.put(56, "ee");
map.put(72, "ff");
map.put(56, "java");
System.out.println(map);
System.out.println(map.get(10));
System.out.println(map.get(30));
System.out.println(map.get(72));
System.out.println(map.get(78));
}
}
运行测试:

泛型完毕。
至于扩容和remove方法可以参考我的另外两篇:
理解java容器底层原理–手动实现ArryList
https://mp.csdn.net/console/editor/html/105032218
和
理解java容器底层原理–手动实现LinkedList
理解java容器底层原理--手动实现HashMap的更多相关文章
- 理解java容器底层原理--手动实现HashSet
HashSet的底层其实就是HashMap,换句话说HashSet就是简化版的HashMap. 直接上代码: package com.xzlf.collection2; import java.uti ...
- 理解java容器底层原理--手动实现LinkedList
Node java 中的 LIinkedList 的数据结构是链表,而链表中每一个元素是节点. 我们先定义一下节点: package com.xzlf.collection; public class ...
- 理解java容器底层原理--手动实现ArrayList
为了照顾初学者,我分几分版本发出来 版本一:基础版本 实现对象创建.元素添加.重新toString() 方法 package com.xzlf.collection; /** * 自定义一个Array ...
- Java面试底层原理
面试发现经常有些重复的面试问题,自己也应该学会记录下来,最好自己能做成笔记,在下一次面的时候说得有条不紊,深入具体,面试官想必也很开心.以下是我个人总结,请参考: HashSet底层原理:(问了大几率 ...
- (前篇:NIO系列 推荐阅读) Java NIO 底层原理
出处: Java NIO 底层原理 目录 1.1. Java IO读写原理 1.1.1. 内核缓冲与进程缓冲区 1.1.2. java IO读写的底层流程 1.2. 四种主要的IO模型 1.3. 同步 ...
- Java 容器 & 泛型:五、HashMap 和 TreeMap的自白
Writer:BYSocket(泥沙砖瓦浆木匠) 微博:BYSocket 豆瓣:BYSocket Java 容器的文章这次应该是最后一篇了:Java 容器 系列. 今天泥瓦匠聊下 Maps. 一.Ma ...
- 10分钟看懂, Java NIO 底层原理
目录 写在前面 1.1. Java IO读写原理 1.1.1. 内核缓冲与进程缓冲区 1.1.2. java IO读写的底层流程 1.2. 四种主要的IO模型 1.3. 同步阻塞IO(Blocking ...
- 深入理解Java容器——HashMap
目录 存储结构 初始化 put resize 树化 get 为什么equals和hashCode要同时重写? 为何HashMap的数组长度一定是2的次幂? 线程安全 参考 存储结构 JDK1.8前是数 ...
- java容器的数据结构-ArrayList,LinkList,HashMap
ArrayList: 初始容量为10,底层实现是一个数组,Object[] elementData 自动扩容机制,当添加一个元素时,数组长度超过了elementData.leng,则会按照1.5倍进行 ...
随机推荐
- iOS hash
一.iOS hash 下图列出 Hash 在 iOS 中的应用分析整理 知乎上的一句话: 算法.数据结构.通信协议.文件系统.驱动等,虽然自己不写那些东西,但是了解其原理对于排错.优化自己的代码有很大 ...
- 浅谈服务架构“五脏六腑”之Spring Cloud
本文将从 Spring Cloud 出发,分两小节讲述微服务框架的「五脏六腑」: 第一小节「服务架构」旨在说明的包括两点,一服务架构是什么及其必要性:二是服务架构的基本组成.为什么第一节写服务架构而不 ...
- Java工程师常用Linux命令
本文所列的Linux常用命令包含:文件相关(目录操作,内容查看,查找与比较,压缩与解压),进程管理,网络操作,系统管理,性能监测与优化,Java常用工具多个方面概述. 文件目录基本操作 ls 命令用来 ...
- Centos7 中打开和关闭防火墙及端口
1.firewalld的基本使用 启动: systemctl start firewalld 关闭: systemctl stop firewalld 查看状态: systemctl status f ...
- jQuery学习笔记01
1.jQuery介绍 1.1什么是jQuery ? jQuery,顾名思义,也就是JavaScript和查询(Query),它就是辅助JavaScript开发的js类库. 1.2 jQuery核心思想 ...
- 实验七 MySQL语言结构
实验七 MySQL语言结构 一. 实验内容: 1. 常量的使用 2. 变量的使用 3. 运算符的使用 4. 系统函数的使用 二. 实验项目:员工管理数据库 用于企业管理的员工管理数据库,数据库名为 ...
- CSS实现文本,DIV垂直居中
https://blog.csdn.net/linayangoo/article/details/88528774 1.水平居中 1.行内元素水平居中 text-align:center; 利用tex ...
- CentOS 通过 expect 批量远程执行脚本和命令
我们有时可能会批量去操作服务器,比如批量在服务器上上传某个文件,安装软件,执行某个命令和脚本,重启服务,重启服务器等,如果人工去一台台操作的话会特别繁琐,并浪费人力. 这时我们可以使用expect,向 ...
- var、let和const的区别详解
let 和 const 是 ECMAScript6 新推出的特性,其中 let 是能够替代 var 的"标准",所以我们探讨 var.let 和 const 的区别,首先应该知 ...
- JavaScript 入门 (一)
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...