Docker 安装Hadoop HDFS命令行操作
网上拉取Docker模板,使用singlarities/hadoop镜像
[root@localhost /]# docker pull singularities/hadoop
查看:
[root@localhost /]# docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/singularities/hadoop latest e213c9ae1b36 months ago 1.19 GB
创建docker-compose.yml文件,内容:
version: "" services:
namenode:
image: singularities/hadoop
command: start-hadoop namenode
hostname: namenode
environment:
HDFS_USER: hdfsuser
ports:
- "8020:8020"
- "14000:14000"
- "50070:50070"
- "50075:50075"
- "10020:10020"
- "13562:13562"
- "19888:19888"
datanode:
image: singularities/hadoop
command: start-hadoop datanode namenode
environment:
HDFS_USER: hdfsuser
links:
- namenode
执行:
[root@localhost hadoop]# docker-compose up -d
Creating network "hadoop_default" with the default driver
Creating hadoop_namenode_1 ... done
Creating hadoop_datanode_1 ... done
4个datanode:
[root@localhost hadoop]# docker-compose scale datanode=
WARNING: The scale command is deprecated. Use the up command with the --scale flag instead.
Starting hadoop_datanode_1 ... done
Creating hadoop_datanode_2 ... done
Creating hadoop_datanode_3 ... done
[root@localhost hadoop]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
19f9685e286f singularities/hadoop "start-hadoop data..." seconds ago Up seconds /tcp, /tcp, /tcp, /tcp, /tcp, /tcp, /tcp, /tcp, /tcp, /tcp, /tcp, /tcp, /tcp hadoop_datanode_3
e96b395f56e3 singularities/hadoop "start-hadoop data..." seconds ago Up seconds /tcp, /tcp, /tcp, /tcp, /tcp, /tcp, /tcp, /tcp, /tcp, /tcp, /tcp, /tcp, /tcp hadoop_datanode_2
5a26b1069dbb singularities/hadoop "start-hadoop data..." minutes ago Up minutes /tcp, /tcp, /tcp, /tcp, /tcp, /tcp, /tcp, /tcp, /tcp, /tcp, /tcp, /tcp, /tcp hadoop_datanode_1
a8656de09ecc singularities/hadoop "start-hadoop name..." minutes ago Up minutes 0.0.0.0:->/tcp, 0.0.0.0:->/tcp, 0.0.0.0:->/tcp, 0.0.0.0:->/tcp, /tcp, /tcp, 0.0.0.0:->/tcp, 0.0.0.0:->/tcp, /tcp, /tcp, /tcp, 0.0.0.0:->/tcp, /tcp hadoop_namenode_1
[root@localhost hadoop]#
效果图;
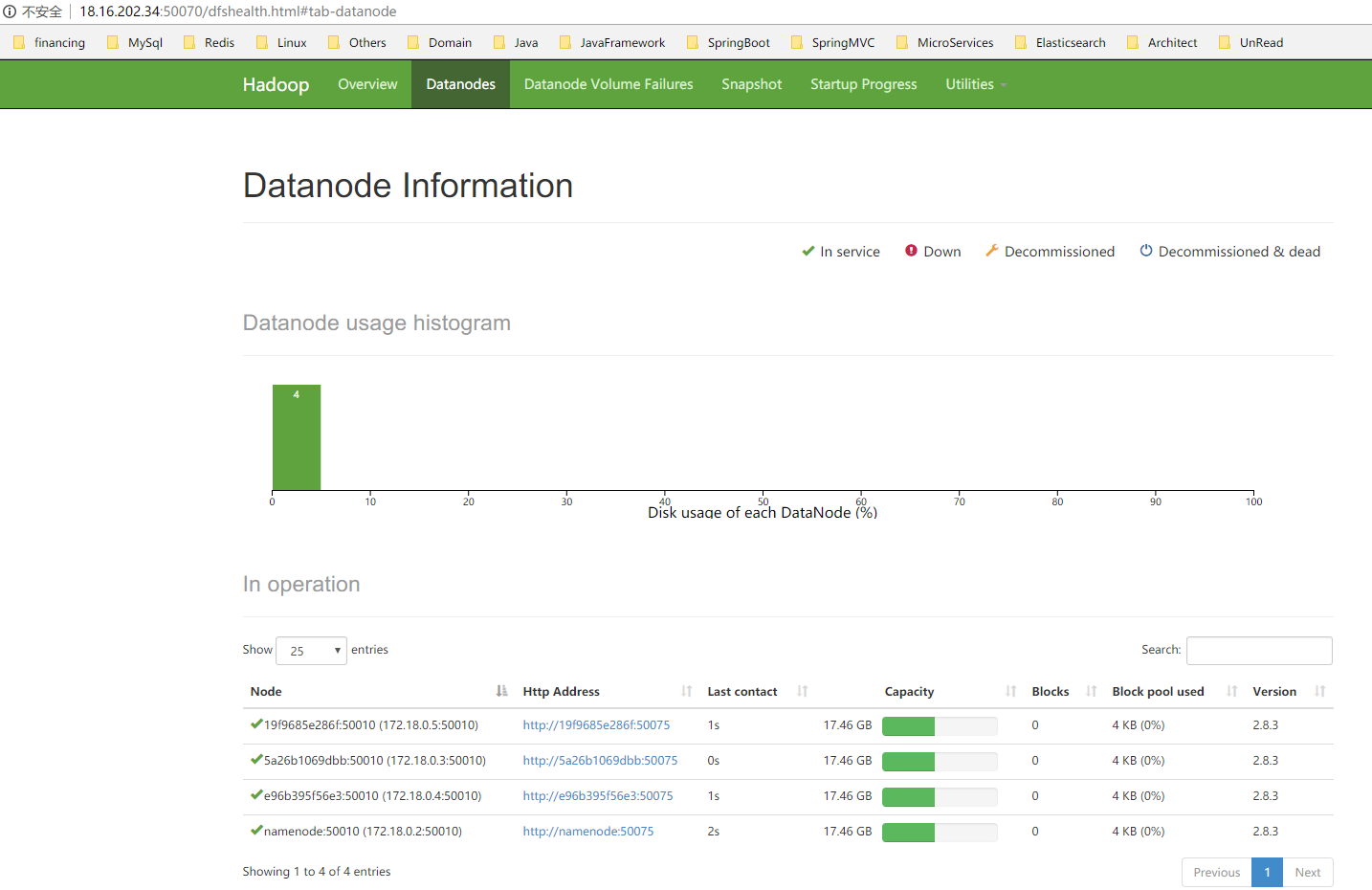
hdfs基础命令:
1、创建目录
hadoop fs -mkdir /hdfs #在根目录下创建hdfs文件夹
2、查看目录
>hadoop fs -ls / #列出跟目录下的文件列表
drwxr-xr-x - root supergroup -- : /hdfs
3、级联创建目录
>hadoop fs -mkdir -p /hdfs/d1/d2
4、级联列出目录
>hadoop fs -ls -R /
drwxr-xr-x - root supergroup -- : /hdfs
drwxr-xr-x - root supergroup -- : /hdfs/d1
drwxr-xr-x - root supergroup -- : /hdfs/d1/d2
5、上传本地文件到HDFS
>echo "hello hdfs" >>local.txt
>hadoop fs -put local.txt /hdfs/d1/d2
6、查看HDFS中文件的内容
>hadoop fs -cat /hdfs/d1/d2/local.txt
hello hdfs
7、下载hdfs上文件的内容
>hadoop fs -get /hdfs/d1/d2/local.txt
8、删除hdfs文件
>hadoop fs -rm /hdfs/d1/d2/local.txt
Deleted /hdfs/d1/d2/local.txt
9、删除hdfs中目录
>hadoop fs -rmdir /hdfs/d1/d2
10、修改文件的权限
>hadoop fs -ls /hdfs
drwxr-xr-x - root supergroup -- : /hdfs/d1 #注意文件的权限
>hadoop fs -chmod /hdfs/d1
drwxrwxrwx - root supergroup -- : /hdfs/d1 #修改后
11、修改文件所属的用户
>hadoop fs -chown admin /hdfs/d1 #修改文件所属用户为admin
>hadoop fs -ls /hdfs
drwxrwxrwx - admin supergroup -- : /hdfs/d1
12、修改文件的用户组
>hadoop fs -chgrp admin /hdfs/d1
>hadoop fs -ls /hdfs
drwxrwxrwx - admin admin -- : /hdfs/d1
查看所有命令方式:
root@master:/# hadoop fs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-x] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]] Generic options supported are
-conf <configuration file> specify an application configuration file
-D <property=value> use value for given property
-fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations.
-jt <local|resourcemanager:port> specify a ResourceManager
-files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster
-libjars <comma separated list of jars> specify comma separated jar files to include in the classpath.
-archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines. The general command line syntax is
command [genericOptions] [commandOptions]
进入一个容器内部进行上述操作,再进入其他的容器,可以发现数据同步了,另外一个节点的操作其他节点也可以看见。
参考:
https://github.com/SingularitiesCR/hadoop-docker
http://www.tianshouzhi.com/api/tutorials/hadoop/129
Docker 安装Hadoop HDFS命令行操作的更多相关文章
- 小记---------有关hadoop的HDFS命令行操作
HDFS命令操作 首先需要在xshell启动hadoop start-all.sh or start-hdfs.sh hadoop fs -ls / (显示当前目录下所有文件) h ...
- HDFS命令行操作
启动后可通过命令行使用hadoop. (1)所有命令 (先将$HADOOP_HOME/bin加入到.bashrc的$PATH变量中) [html] view plaincopy [hadoop@nod ...
- Git入门(安装及基础命令行操作)
一.安装 1.Mac 在Mac中安装Git的方法不止一种.最简单的要数通过Xcode命令行工具.对于Mavericks(10.9)或更高版本的操作系统,当你第一次尝试在终端执行git命令时,系统会自动 ...
- hadoop hdfs 命令行 设置文件夹大小的上限 quota:配额
>bin/hdfs dfs -put readme.txt /finance >bin/hdfs dfs -du -s /finance > /finance >bin/hdf ...
- Hadoop系列006-HDFS概念及命令行操作
本人微信公众号,欢迎扫码关注! HDFS概念及命令行操作 一.HDFS概念 1.1 概念 HDFS,它是一个文件系统,用于存储文件,通过目录树来定位文件:其次,它是分布式的,由很多服务器联合起来实现其 ...
- HDFS分布式文件系统的常用命令行操作
一.HDFS的客户端种类 1.网页形式 =>用于测试 网址为你的namenode节点的ip+50070的端口号,如: 192.168.50.128:50070 2.命令行形式 =>用于测 ...
- HDFS命令行及JAVA API操作
查看进程 jps 访问hdfs: hadoop-root:50070 hdfs bash命令: hdfs dfs <1> -help: 显示命令的帮助的信息 <2> - ...
- kafka工作流程| 命令行操作
1. 概述 数据层:结构化数据+非结构化数据+日志信息(大部分为结构化) 传输层:flume(采集日志--->存储性框架(如HDFS.kafka.Hive.Hbase))+sqoop(关系型数 ...
- docker安装hadoop集群
docker安装hadoop集群?图啥呢?不图啥,就是图好玩.本篇博客主要是来教大家如何搭建一个docker的hadoop集群.不要问 为什么我要做这么无聊的事情,答案你也许知道,因为没有女票.... ...
随机推荐
- List<String> 2List <Long>
public static List<Integer> CollStringToIntegerLst(List<String> inList){ List<Integer ...
- HAProxy实现mysql负载均衡
安装 yum install haproxy 修改配置 vi /etc/haproxy/haproxy.cfg 配置如下 global daemon nbproc 1 pidfile /var/r ...
- 在caffe-ssd安装编译环境运行make all时候报错:Makefile:572: recipe for target '.build_release/src/caffe/util/hdf5.o' failed make: *** [.build_release/src/caffe/util/hdf5.o] Error 1
解决办法: 修改:Makefile.config INCLUDE_DIRS /usr/include/hdf5/serial/ 修改:Makefile LIBRARIES hdf5_hl and hd ...
- Springboot整合Mybatis 之分页插件使用
1: 引入jar包 <!-- 引入MyBatis分页插件--> <dependency> <groupId>com.github.pagehelper</gr ...
- python中的IO操作
python中的基本IO操作: 1) 键盘输入函数:raw_input(string),不作处理的显示,与返回. input(string),可以接受一个python表达式作为返回,python内部得 ...
- PE结构图示
- 强化学习--DeepQnetwork 的一些改进
Double DQN 算Q值 与选Q值是分开的,2个网络. Multi-step Dueling DQN 如果更新了,即使有的action没有被采样到,也会更新Q值 Prioritized Reply ...
- MySql 学习参考目录
[1]< MySql 数据类型> [2]< MySql 基础 > [3]< MySql 存储过程 > PS:个人认为,如上总结超值. Good Good Study ...
- ext2文件系统的运行—superblock/inode/block
鸟哥私房菜书上内容: superblock:记录此 filesystem 的整体信息,包括inode/block的总量.使用量.剩余量, 以及文件系统的格式与相关信息等:inode:记录文件的属性,一 ...
- Linux CPU使用率含义及原理
相关概念 在Linux/Unix下,CPU利用率分为用户态.系统态和空闲态,分别表示CPU处于用户态执的时间,系统内核执行的时间,和空闲系统进程执行的时间. 下面是几个与CPU占用率相关的概念. CP ...