scrapy爬取某网站,模拟登陆过程中遇到的那些坑
本节内容
在访问网站的时候,我们经常遇到有些页面必须用户登录才能访问。这个时候我们之前写的傻傻的爬虫就被ban在门外了。所以本节,我们给爬虫配置cookie,使得爬虫能保持用户已登录的状态,达到获得那些需登录才能访问的页面的目的。
由于本节只是单纯的想保持一下登陆状态,所以就不写复杂的获取页面了,还是像本教程的第一部分一样,下载个网站主页验证一下就ok了。本节github戳此处。
原理
一般情况下,网站通过存放在客户端的一个被称作cookie的小文件来存放用户的登陆信息。在浏览器访问网站的时候,会把这个小文件发往服务器,然后服务器根据这个小文件确定你的身份,然后返回给你特定的信息。
我们要做的就是尽量模拟浏览器的行为,在使用爬虫访问网站时也带上cookie来访问。
前提
前提当然是你有个账号了,目前本教程一直使用的论坛心韵论坛是我本人搭建的,已经被各种爬虫发的广告水的不要不要的了,为了本教程,仍然是开放注册并一直开着服。但不保证会一直开着,不过根据本教程的讲解,爬取别的Discuz框架论坛一般是没问题的。扯远了……
获取cookie
按照以下步骤操作
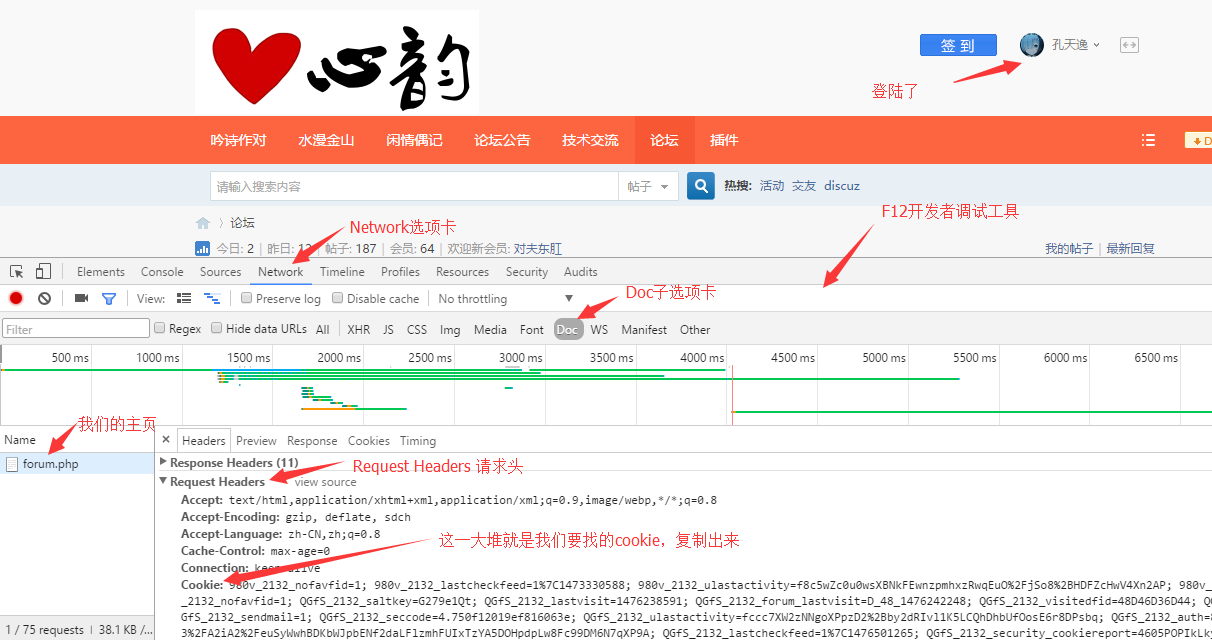
- 登陆论坛,进入主页
- 按F12进入Chrome或Firefox的开发者调试工具,选择Network选项卡
- 按F5刷新一下页面
- 选择Doc子选项卡
- 找到主页的请求和返回情况
- 找到Request Headers
- 复制出cookie
如图:
把cookie转化格式
在scrapy中,设置cookie需要是字典格式的,可是我们从浏览器Copy出来的是字符串格式的,所以我们需要写个小程序来转化一下
transCookie.py
# -*- coding: utf-8 -*-
class transCookie:
def __init__(self, cookie):
self.cookie = cookie
def stringToDict(self):
'''
将从浏览器上Copy来的cookie字符串转化为Scrapy能使用的Dict
:return:
'''
itemDict = {}
items = self.cookie.split(';')
for item in items:
key = item.split('=')[0].replace(' ', '')
value = item.split('=')[1]
itemDict[key] = value
return itemDict
if __name__ == "__main__":
cookie = "你复制出的cookie"
trans = transCookie(cookie)
print trans.stringToDict()运行的效果如图
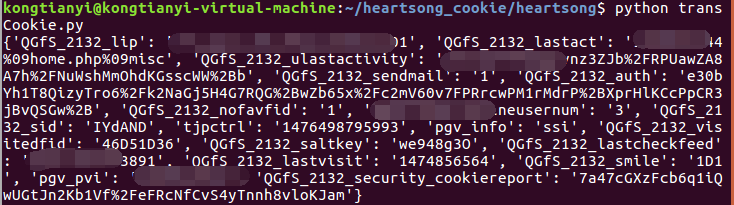
然后把这个字典复制出来。
给scrapy配置cookie
首先把刚才得到的cookie放到settings.py里
settings.py
# -*- coding: utf-8 -*-
BOT_NAME = 'heartsong'
SPIDER_MODULES = ['heartsong.spiders']
NEWSPIDER_MODULE = 'heartsong.spiders'
ROBOTSTXT_OBEY = False # 不遵守Robot协议
# 使用transCookie.py翻译出的Cookie字典
COOKIE = {'key1': 'value1', 'key2': 'value2'}然后编写爬虫文件
heartsong_spider.py
# -*- coding: utf-8 -*-
# import scrapy # 可以用这句代替下面三句,但不推荐
from scrapy.spiders import Spider
from scrapy import Request
from scrapy.conf import settings
class HeartsongSpider(Spider):
name = "heartsong"
allowed_domains = ["heartsong.top"] # 允许爬取的域名,非此域名的网页不会爬取
start_urls = [
# 主页,此例只下载主页,看是否有登录信息
"http://www.heartsong.top/forum.php"
]
cookie = settings['COOKIE'] # 带着Cookie向网页发请求
# 发送给服务器的http头信息,有的网站需要伪装出浏览器头进行爬取,有的则不需要
headers = {
'Connection': 'keep - alive', # 保持链接状态
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.82 Safari/537.36'
}
# 对请求的返回进行处理的配置
meta = {
'dont_redirect': True, # 禁止网页重定向
'handle_httpstatus_list': [301, 302] # 对哪些异常返回进行处理
}
# 爬虫的起点
def start_requests(self):
# 带着cookie向网站服务器发请求,表明我们是一个已登录的用户
yield Request(self.start_urls[0], callback=self.parse, cookies=self.cookie,
headers=self.headers, meta=self.meta)
# Request请求的默认回调函数
def parse(self, response):
with open("check.html", "wb") as f:
f.write(response.body) # 把下载的网页存入文件总的来说一句话,就是带着cookie发起Request请求。
运行之后会将主页保存,我们打开文件查看一下效果
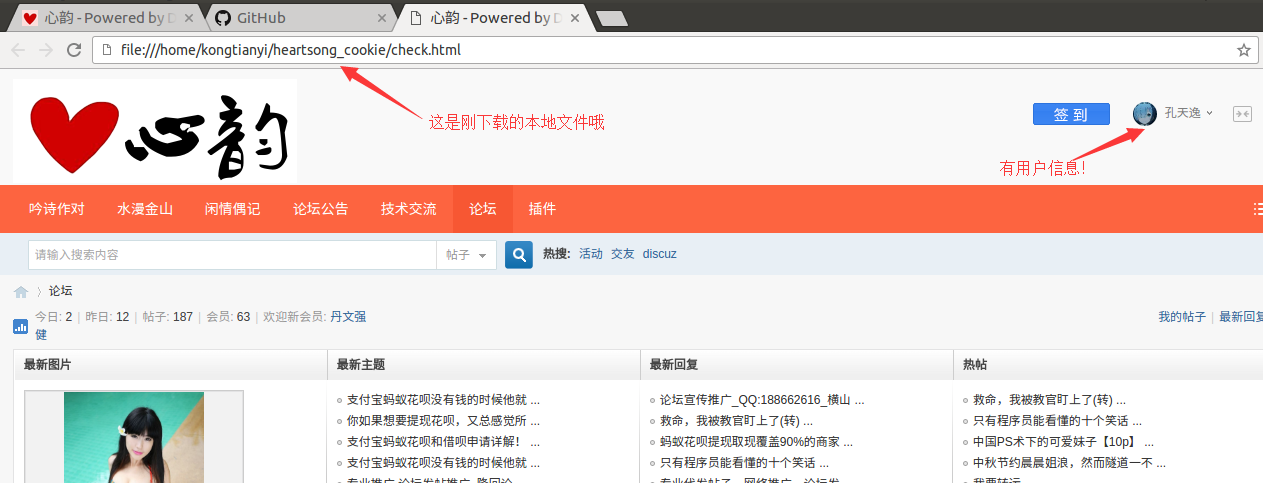
小结
本节介绍了cookie的获取方法和如何给scrapy设置cookie,下节我会介绍如果带着登陆状态去回复主题帖。

scrapy爬取某网站,模拟登陆过程中遇到的那些坑的更多相关文章
- 使用webdriver+urllib爬取网页数据(模拟登陆,过验证码)
urilib是python的标准库,当我们使用Python爬取网页数据时,往往用的是urllib模块,通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获得ur ...
- Python 爬取 "王者荣耀.英雄壁纸" 过程中的矛和盾
1. 前言 学习爬虫,最好的方式就是自己编写爬虫程序. 爬取目标网站上的数据,理论上讲是简单的,无非就是分析页面中的资源链接.然后下载.最后保存. 但是在实施过程却会遇到一些阻碍. 很多网站为了阻止爬 ...
- 1.scrapy爬取的数据保存到es中
先建立es的mapping,也就是建立在es中建立一个空的Index,代码如下:执行后就会在es建lagou 这个index. from datetime import datetime fr ...
- 使用Scrapy爬取图书网站信息
重难点:使用scrapy获取的数值是unicode类型,保存到json文件时需要特别注意处理一下,具体请参考链接:https://www.cnblogs.com/sanduzxcvbnm/p/1030 ...
- Scrapy 爬取某网站图片
1. 创建一个 Scrapy 项目,在命令行或者 Pycharm 的 Terminal 中输入: scrapy startproject imagepix 自动生成了下列文件: 2. 在 imagep ...
- scrapy爬取招聘网站,items转换成dict遇到的问题
pipelines代码 1 import json 2 3 class TencentJsonPipeline(object): 4 def __init__(self): 5 self.file = ...
- scrapy爬取美女图片
使用scrapy爬取整个网站的图片数据.并且使用 CrawlerProcess 启动. 1 # -*- coding: utf-8 -* 2 import scrapy 3 import reques ...
- Python网络爬虫 | Scrapy爬取妹子图网站全站照片
根据现有的知识,写了一个下载妹子图(meizitu.com)Scrapy脚本,把全站两万多张照片下载到了本地. 网站的分析 网页的网址分析 打开网站,发现网页的网址都是以 http://www.mei ...
- scrapy爬取西刺网站ip
# scrapy爬取西刺网站ip # -*- coding: utf-8 -*- import scrapy from xici.items import XiciItem class Xicispi ...
随机推荐
- Oracle varchar与varchar2的区别
varchar -- 存放定長的字符数据,最长2000個字符:varchar2 -- 存放可变长字符数据,最大长度为4000字符. varchar2是oracle提供的独特的数据类型oracle保证在 ...
- Tomcat增加虚拟内存(转)
程序要遍历读取xml并写入数据库,需要占用大量内存 如果数据量大则报错 Exception in thread "Timer-0" java.lang.OutOfMemoryErr ...
- 字节码 反编译 APKTool 重新打jar包 MD
Markdown版本笔记 我的GitHub首页 我的博客 我的微信 我的邮箱 MyAndroidBlogs baiqiantao baiqiantao bqt20094 baiqiantao@sina ...
- 如何成为一名Top DevOps Engineer
软件世界的战场 如果你对devops的概念不是很了解的话,没有关系,可以先跳到维基百科阅读一下DevOps条目.有了模模糊糊的概念之后, 我们先抛开所有市面上对于devops的各种夸大和炒作,首先来思 ...
- WPF获取当前用户控件的父级窗体
方式一.通过当前控件名获取父级窗体 Window targetWindow = Window.GetWindow(button); 方式二.通过当前控件获取父级窗体 Window parentWind ...
- JAVA中通过JavaCV实现跨平台视频/图像处理-调用摄像头
一.简介 JavaCV使用来自计算机视觉领域(OpenCV, FFmpeg, libdc1394, PGR FlyCapture, OpenKinect, librealsense, CL PS3 E ...
- Spark GraphX实例(3)
7. 图的聚合操作 图的聚合操作主要的方法有: (1) Graph.mapReduceTriplets():该方法有一个mapFunc和一个reduceFunc,mapFunc对图中的每一个EdgeT ...
- Windows下Kettle定时任务执行并发送错误信息邮件
Windows下Kettle定时任务执行并发送错误信息邮件 1.首先安装JDK 2.配置JDK环境 3.下载并解压PDI(kettle) 目前我用的是版本V7的,可以直接百度搜索下载社区版,企业版收费 ...
- 各种软件的安装教程centos mysql tomcat nginx jenkins jira 等等
464 Star3,606 Fork 1,460 judasn/Linux-Tutorial 作者: https://github.com/judasn Linux-Tutorial/markdow ...
- Roller5.0.3安装配置部署 step by step
一.下载roller 下载地址:http://roller.apache.org/downloads/downloads.html下载下来之后,解压包含两部份doc.webapps 二.准备环境 1. ...