Reshape以及向量机分类学习和等高线绘制代码
首先科普一下python里面对于数组的处理,就是如果获取数组大小,以及数组元素数量,这个概念是不一样的,就是一个size和len处理不用。老规矩,上代码:
arr2 = np.array([-19.51679711, -18.06166131, -16.65282549, 8.70287809,9.9485567 , 11.23867649, 3,4])
pprint(arr2.size)
pprint(len(arr2))
>>8
>>8
貌似两者没啥区别,但是真的是这样吗?
Code:
arr2 = np.array([[-19.51679711, -18.06166131, -16.65282549, 8.70287809,9.9485567 , 11.23867649, 3,4]])
pprint(arr2.size)
pprint(len(arr2))
>>8
>>1
在多维数组中,size代表的是所有的最小单元的总和,len则是代表多维数组元素的数量。
接着我们讲一下reshape,重新塑形,简单的讲就是将一个一维数组,打成多维数组:
arr = np.arange(6)
brr = arr.reshape((3,2))
pprint(brr)
>> array([[0, 1], [2, 3], [4, 5]])
介绍完了基础知识,我们再来看一下SVM的分类学习
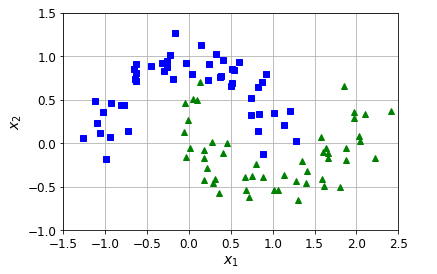
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=100, noise=0.15, random_state=42) def plot_dataset(X, y, axes):
plt.plot(X[y==0, 0], X[y==0, 1], "bs")
plt.plot(X[y==1, 0], X[y==1, 1], "g^")
plt.axis(axes)
plt.grid(True, which="both") #这个双引号行吗?没问题
plt.xlabel("$x_1$")
plt.ylabel("$x_2$") plot_dataset(X, y, [-1.5, 2.5, -1, 1.5])
plt.show()
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures polynomial_svm_clf=Pipeline((
("ploy_feature", PolynomialFeatures(degree=3)), # 这里为什么需要多项式?有什么影响?
("ploy_scale", StandardScaler()), # 缩小,减小离群点对于整体影响;
("svm", LinearSVC(C=10, loss="hinge"))
)) polynomial_svm_clf.fit(X, y)
# 基于坐标范围,形成点群(X)以及每个点的分类(y,等高线就是根据y值绘制的);所以可以看到每个点其实是有三个属性,坐标(x, y)以及分类
# 这个函数就是要生成这样的点,然后根据分类绘制等高线,这批套路非常重要
def plot_prediction(clf, axes):
x0s = np.linspace(axes[0], axes[1], 100) # 根据坐标范围等分点
x1s = np.linspace(axes[2], axes[3], 100)
# 这个是做什么的? meshgrid之后将会形成两套矩阵, 有大量容易,其实都是根据第一行(x0))和第一列(x1)进行衍生
x0, x1 = np.meshgrid(x0s, x1s)
# 这个又是在做什么?将衍生的矩阵里面的向量进行拉伸,通过np.c_进行整合,将会得到一个矩阵,矩阵里面每个向量都是两个元素(代表一个坐标),
# 来自于拉伸的两个矩阵的组合
X = np.c_[x0.ravel(), x1.ravel()]
plt.plot(X[501:600,0], X[501:600,1], "ys") # 这是我写的一段测试代码,打印出来的是X的部分点集,这里注意多维数组[:,:]中第一个参数代表行范围,第二个参数代表列范围
# 获取的完了predict为什么要reshape一下?clf.predict(X)返回的只是一个一维数组,每个数组对应X的一个向量(每个向量都是一个点),
# reshape之后,将会复制N行并返回N行的矩阵(N的值和X的行向量数量是一样的)
y_pred = clf.predict(X).reshape(x0.shape)
# decsion_function干嘛,为啥完事后有reshape一下?decision_function代表参数实例(各个元素)到分类平面(超平面)的距离,所以其数量
# 是等于X中向量的数量:10000,x0.shape是(100,100),于是reshape之后将会成为100行100列的多维数组
y_decision = clf.decision_function(X).reshape(x0.shape)
# 绘制分类(等高)线
plt.contourf(x0, x1, y_pred, cmap=plt.cm.brg, alpha=0.2)
# 绘制距离线
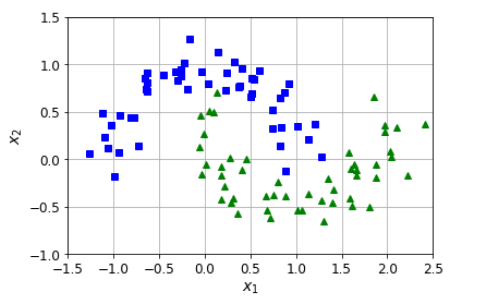
plt.contourf(x0, x1, y_decision, cmap=plt.cm.brg, alpha=0.1) plot_prediction(polynomial_svm_clf, [-1.5, 2.5, -1, 1.5]) #花了两条等高线
plot_dataset(X, y, [-1.5, 2.5, -1, 1.5]) # 换了两个交互的半环
plt.show()
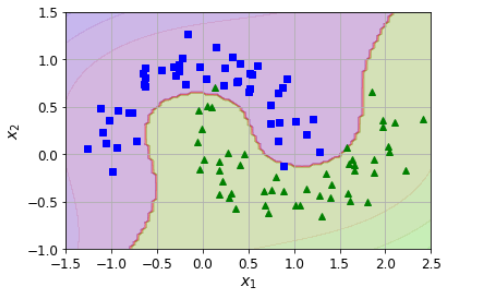
这段代码基本思路如下:
我先有数据,一个月牙环形数据(左侧图);然后我用这个数据,训练出来一个向量机(SVM),因为数据是曲线的,所以需要高次公式,于是搞了一个Pipeline,整合了Scalar和SVM来进行学习;通过fit函数,把模型的参数都搞掂了;然后我利用这个向量机来进行绘制边界线,怎么来绘制呢?首先在坐标中获取10000个点,均匀的散播在整个坐标系中;我再把这些点扔到SVM中,让他根据之前学习的结果获取分类,contours英文意思就是轮廓,在matlibplot中,contourf这个函数将会把轮廓画出来,并且填充颜色;简单讲就是同类别同颜色,然后会在不同类别之间画出一条分界线。
这段代码意义在于讲清楚了SVM的学习能力;通过针对半月环形数据的学习掌握了参数,具备了对于点判断分类的能力;未来当有海量的数据需要判断的时候,会基于之前的学习模型,来进行判断,分类,在右图海量数据作为测试数据的场景下,通过轮廓线说明了SVM所具备的学习能力。
Reshape以及向量机分类学习和等高线绘制代码的更多相关文章
- SVM学习笔记-线性支撑向量机
对于PLA算法来说,最终得到哪一条线是不一定的,取决于算法scan数据的过程. 从VC bound的角度来说,上述三条线的复杂度是一样的 Eout(w)≤Ein0+Ω(H)dvc= ...
- SVM-支持向量机(一)线性SVM分类
SVM-支持向量机 SVM(Support Vector Machine)-支持向量机,是一个功能非常强大的机器学习模型,可以处理线性与非线性的分类.回归,甚至是异常检测.它也是机器学习中非常热门的算 ...
- 支撑向量机(SVM)
转载自http://blog.csdn.net/passball/article/details/7661887,写的很好,虽然那人也是转了别人的做了整理(最原始文章来自http://www.blog ...
- SVM-支持向量机算法概述
(一)SVM的背景简单介绍 支持向量机(Support Vector Machine)是Cortes和Vapnik于1995年首先提出的,它在解决小样本.非线性及高维模式识别中表现出很多特有的优势,并 ...
- 文本分类学习 (五) 机器学习SVM的前奏-特征提取(卡方检验续集)
前言: 上一篇比较详细的介绍了卡方检验和卡方分布.这篇我们就实际操刀,找到一些训练集,正所谓纸上得来终觉浅,绝知此事要躬行.然而我在躬行的时候,发现了卡方检验对于文本分类来说应该把公式再变形一般,那样 ...
- 文本分类学习 (十)构造机器学习Libsvm 的C# wrapper(调用c/c++动态链接库)
前言: 对于SVM的了解,看前辈写的博客加上读论文对于SVM的皮毛知识总算有点了解,比如线性分类器,和求凸二次规划中用到的高等数学知识.然而SVM最核心的地方应该在于核函数和求关于α函数的极值的方法: ...
- 统计学习方法:支撑向量机(SVM)
作者:桂. 时间:2017-05-13 21:52:14 链接:http://www.cnblogs.com/xingshansi/p/6850684.html 前言 主要记录SVM的相关知识,参考 ...
- 8.支撑向量机SVM
1.什么是SVM 下面我们就来介绍一些SVM(Support Vector Machine),首先什么是SVM,它是做什么的?SVM,中文名是支撑向量机,既可以解决分类问题,也可以解决回归问题,我们来 ...
- 文本分类学习 (七)支持向量机SVM 的前奏 结构风险最小化和VC维度理论
前言: 经历过文本的特征提取,使用LibSvm工具包进行了测试,Svm算法的效果还是很好的.于是开始逐一的去了解SVM的原理. SVM 是在建立在结构风险最小化和VC维理论的基础上.所以这篇只介绍关于 ...
随机推荐
- wx小程序用canvas生成图片流程与注意事项
1.需要画入canvas的 图片都需要先缓存到本地 let ps = [] ps.push(that.loadImageFun(this.statusInfo.avatar_url, "he ...
- vue mapbox 地图 demo
执行以下命令: npm install --save mapbox-gl// cnpm install --save mapbox-gl <template> <div style= ...
- 2019 flag
学习 1.学会一种新的编程语言或脚本语言,并编写不少于十个应用 2.读5-8本其他学科书籍,(经济,心里学等) 3.坚持每个月最少更新8-10篇博客(技术,学习) 4.阅读并理解和应用两个开源lib ...
- SSM整合框架实现ajax校验
SSM整合框架实现ajax校验 刚学习了ssm框架,ajax校验成功,分享下 1.导入jar包
- 【转载】 pytorch之添加BN
原文地址: https://blog.csdn.net/weixin_40123108/article/details/83509838 ------------------------------- ...
- Deinstall卸载RAC之Oracle软件及数据库+GI集群软件
Deinstall卸载Oracle软件及数据库+GI集群软件 1. 本篇文档应用场景: 需要安装新的ORACLE RAC产品,系统没有重装,需要对原环境中的RAC进行卸载: #本篇文档,在AIX 6. ...
- multi-thread debug
1.不要去解锁一个未被加锁的mutex锁: 2.不要一个线程中加锁而在另一个线程中解锁: 3.使用mutex锁用于保护临界资源,严格按照“加锁-->写入/读取临界资源-->解锁”的流程执行 ...
- Python之路PythonThread,第二篇,进程2
python3 进程2 僵尸进程处理方法: 3,创建二级子进程处理 4,在父进程中使用信号处理的方法忽略子进程发来的信号: signal(SIGCHLD,DIG,IGN) # 创建二级子进场解决僵 ...
- Seaweedfs-启动脚本
#!/bin/bash if [ ! -e /sunlight/shell/main.sh ];then echo " [ Error ] file /sunlight/shell/main ...
- lecture4特征提取-七月在线-cv
霍夫变换 http://blog.csdn.net/sudohello/article/details/51335237 http://blog.csdn.net/glouds/article/det ...