python算法之快速排序
快速排序
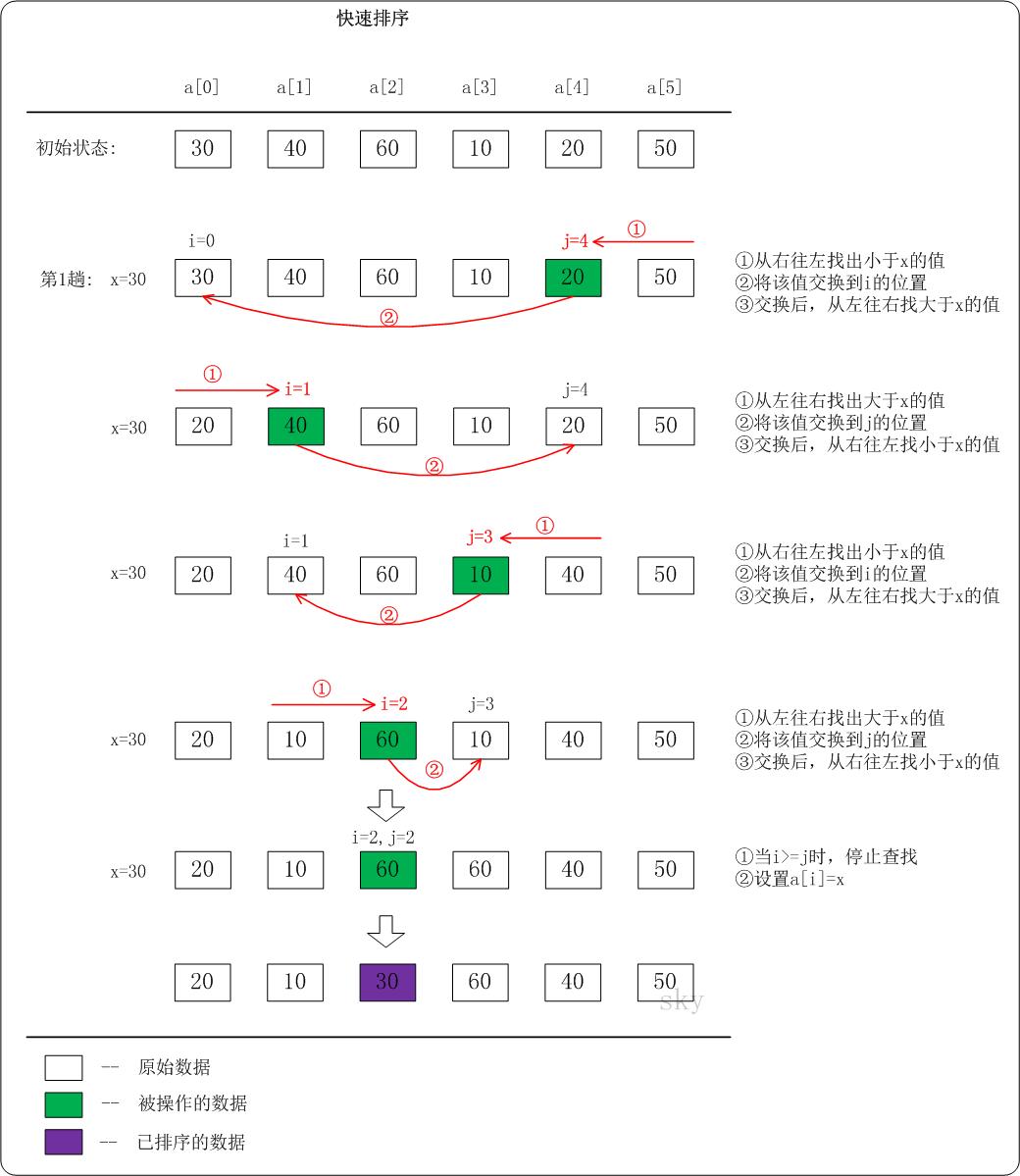
快速排序(英语:Quicksort),又称划分交换排序(partition-exchange sort),通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
步骤为:
- 从数列中挑出一个元素,称为"基准"(pivot),
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
递归的最底部情形,是数列的大小是零或一,也就是永远都已经被排序好了。虽然一直递归下去,但是这个算法总会结束,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。
快速排序的分析
def quick_sort(alist, start, end):
"""快速排序""" # 递归的退出条件
if start >= end:
return # 设定起始元素为要寻找位置的基准元素
mid = alist[start] # low为序列左边的由左向右移动的游标
low = start # high为序列右边的由右向左移动的游标
high = end while low < high:
# 如果low与high未重合,high指向的元素不比基准元素小,则high向左移动
while low < high and alist[high] >= mid:
high -= 1
# 将high指向的元素放到low的位置上
alist[low] = alist[high] # 如果low与high未重合,low指向的元素比基准元素小,则low向右移动
while low < high and alist[low] < mid:
low += 1
# 将low指向的元素放到high的位置上
alist[high] = alist[low] # 退出循环后,low与high重合,此时所指位置为基准元素的正确位置
# 将基准元素放到该位置
alist[low] = mid # 对基准元素左边的子序列进行快速排序
quick_sort(alist, start, low-1) # 对基准元素右边的子序列进行快速排序
quick_sort(alist, low+1, end) alist = [54,26,93,17,77,31,44,55,20]
quick_sort(alist,0,len(alist)-1)
print(alist)
时间复杂度
- 最优时间复杂度:O(nlogn)
- 最坏时间复杂度:O(n2)
- 稳定性:不稳定
从一开始快速排序平均需要花费O(n log n)时间的描述并不明显。但是不难观察到的是分区运算,数组的元素都会在每次循环中走访过一次,使用O(n)的时间。在使用结合(concatenation)的版本中,这项运算也是O(n)。
在最好的情况,每次我们运行一次分区,我们会把一个数列分为两个几近相等的片段。这个意思就是每次递归调用处理一半大小的数列。因此,在到达大小为一的数列前,我们只要作log n次嵌套的调用。这个意思就是调用树的深度是O(log n)。但是在同一层次结构的两个程序调用中,不会处理到原来数列的相同部分;因此,程序调用的每一层次结构总共全部仅需要O(n)的时间(每个调用有某些共同的额外耗费,但是因为在每一层次结构仅仅只有O(n)个调用,这些被归纳在O(n)系数中)。结果是这个算法仅需使用O(n log n)时间。
快速排序演示

python算法之快速排序的更多相关文章
- Algorithm: quick sort implemented in python 算法导论 快速排序
import random def partition(A, lo, hi): pivot_index = random.randint(lo, hi) pivot = A[pivot_index] ...
- Python之排序算法:快速排序与冒泡排序
Python之排序算法:快速排序与冒泡排序 转载请注明源地址:http://www.cnblogs.com/funnyzpc/p/7828610.html 入坑(简称IT)这一行也有些年头了,但自老师 ...
- Python实现排序算法之快速排序
Python实现排序算法:快速排序.冒泡排序.插入排序.选择排序.堆排序.归并排序和希尔排序 Python实现快速排序 原理 首先选取任意一个数据(通常选取数组的第一个数)作为关键数据,然后将所有比它 ...
- 基础排序算法之快速排序(Quick Sort)
快速排序(Quick Sort)同样是使用了分治法的思想,相比于其他的排序方法,它所用到的空间更少,因为其可以实现原地排序.同时如果随机选取中心枢(pivot),它也是一个随机算法.最重要的是,快速排 ...
- Python算法:推导、递归和规约
Python算法:推导.递归和规约 注:本节中我给定下面三个重要词汇的中文翻译分别是:Induction(推导).Recursion(递归)和Reduction(规约) 本节主要介绍算法设计的三个核心 ...
- GitHub标星2.6万!Python算法新手入门大全
今天推荐一个Python学习的干货. 几个印度小哥,在GitHub上建了一个各种Python算法的新手入门大全,现在标星已经超过2.6万.这个项目主要包括两部分内容:一是各种算法的基本原理讲解,二是各 ...
- 安装Python算法库
安装Python算法库 主要包括用NumPy和SciPy来处理数据,用Matplotlib来实现数据可视化.为了适应处理大规模数据的需求,python在此基础上开发了Scikit-Learn机器学习算 ...
- Java常见排序算法之快速排序
在学习算法的过程中,我们难免会接触很多和排序相关的算法.总而言之,对于任何编程人员来说,基本的排序算法是必须要掌握的. 从今天开始,我们将要进行基本的排序算法的讲解.Are you ready?Let ...
- 常用排序算法之——快速排序(C语言+VC6.0平台)
经典排序算法中快速排序具有较好的效率,但其实现思路相对较难理解. #include<stdio.h> int partition(int num[],int low,int high) / ...
随机推荐
- javascript的slice()与splice()方法
(1)数组和String对象都有slice()方法. //Array var list = ['A','B','C','D','DS']; console.log(list.slice(,));//截 ...
- 让你真正了解chmod和chown命令的用法
问题导读:1.chown的英语含义是什么?2.chmod英语含义是什么?3.chown改变的是什么权限?4.chmod改变的是什么权限? 这两个对于初学者很容易混肴,这里ch,其实是change的简写 ...
- python(八):反射
反射机制是通过python3内置的hasattr.getattr.setattr来实现的.即根据变量名的字符串形式来获取变量名的属性或方法. 一.通过反射查看已知对象的属性和方法 getattr(ob ...
- HTMLTestRunner显示用例打印内容
我们知道默认的HTMLTestRunner运行时成功只会显示...,失败也只是显示E suite = unittest.TestLoader().loadTestsFromTestCase(MyTes ...
- svn 操作命令
1.第一次提交代码到svn svn import project_directory PATH 2.将文件checkout到本地svn checkout path(path是服务器上的目录) 例如:s ...
- Epub格式的电子书——文件组成
epub格式电子书遵循IDPF推出的OCF规范,OCF规范遵循ZIP压缩技术,即epub电子书本身就是一个ZIP文件,我们将epub格式电子书的后缀.epub修改为.zip后,可以通过解压缩软件(例如 ...
- dockerize 容器工具集基本使用
基本功能: * 在启动的时候根据环境变量或者模版生成配置文锦啊 * 多日志文件重定向到标准输入输出 * 等待其他服务(tcp,http unix)起来之后在启动主进程 1. 安装 直 ...
- HDFS(三)
DataNode 下面的数据文件有两种类型,一种是数据块,一种是数据块的描述文件(元数据文件),后者文件后面带有.meta后缀: Version文件字段内容其实和NameNode里面涵义是一致的: 安 ...
- 什么是spark(六)Spark中的对象
Spark中的对象 Spark的Conf,极简化的场景,可以设置一个空conf给sparkContext,在执行spark-submit的时候,系统会默认给sparkContext赋一个SparkCo ...
- MySQL主从报错解决:Failed to initialize the master info structure
大清早收到一个MySQL的自定义语言告警 :replication interrupt,看来是主从同步报错了. 登陆MySQL,执行 show slave status \G 发现salve已经停止了 ...