hadoop杂记-为什么会有Map-reduce v2 (Yarn)
转自:http://www.cnblogs.com/LeftNotEasy/archive/2012/02/18/why-yarn.html
前言:
有一段时间没有写博客了(发现这是我博客最常见的开头,不过这次间隔真的好长),前段时间事情比较多,所以耽搁得也很多。
现在准备计划写一个新的专题,叫做《hadoop杂记》,里面的文章有深有浅,文章不是按入门-中级-高级的顺序组织的,如果想看看从入门到深入的书,比较推荐《the definitive guide of hadoop》。
今天主要想写写关于map-reduce v2(或者叫map-reduce next generation,或者叫YARN)与之前的map-reduce有什么不同。最近在学习Yarn的过程中,也参考了很多人的博客,里面的介绍都各有所长。不过一个很重要的问题是,为什么需要一个Yarn,初看之后,也不觉得Yarn有什么特别的,就是把之前设计中的一块拆成了几块,仔细想想,方才明白其中的奥妙。
理解本文需要对老的Map-reduce框架有一定的了解。有朋友如果对hadoop以及大数据处理的架构、应用的咨询、讨论等等可以按下一段的联系方式与我联系。
版权声明:本文由leftnoteasy发布于http://leftnoteasy.cnblogs.com,本文可以部分或者全部的被引用,但请注明出处,可以联系wheeleast (at) gmail.com, 也可以加我weibo: http://weibo.com/leftnoteasy
Why Yarn:
Map-reduce老矣,尚能饭否?
第一次看到Yarn的问题,就需要问问,为什么要重新设计之前这样一个成熟的架构。
“The Apache Hadoop Map-reduce framework is showing it’s age, clearly”, 社区的Yarn设计文档 ”MapReduce_NextGen-Architecture”如是说。
目前的Map-reduce framework碰到了很多的问题,比如说过于大的内存消耗、不合理的线程模型设计、当集群规模增大后,扩展性/稳定性/性能的不足。这是目前hadoop的集群一直停留在Yahoo公布出来的3000台这个数量级上。
为了克服之前说道的问题,就需要对目前架构上进行重新思考,之后我会对新老Map-reduce架构上进行比较。
Yarn的设计需求
这里放上设计需求不是为了凑字数的,最近越来越发现设计需求是软件开发的灵魂,虽然需求常常变化可以唤醒植物人,不过一份好的设计需求可以让之后怎么走变得非常清晰。参考自Yarn设计文档:
最优先的需求:
· Reliability
· Availability
· Scalability - Clusters of 10000 nodes and 200,000 cores
· Backward Compatibility - Ensure customers’ Map-Reduce applications can run unchanged in the nextversion of the framework. Also implies forward compatibility. (向前兼容)
· Evolution – Ability for customers to control upgrades to the grid software stack.
· Predictable Latency – A major customer concern.
· Cluster utilization
The second tier of requirements is(优先级低一点的需求):
· Support for alternate programming paradigms to Map-Reduce
· Support for limited, short-lived services
这里解释一下这份需求,首先是可以支持非常大的集群规模,200k cores这个数字的确很惊人。
然后是向前兼容,之前大家都写了很多在map-reduce上面的程序,如果不能支持这些老的程序,老的用户怎么都不愿意切换到新版本上去。
另外集群资源最大化利用,这个之后会提一下
然后值得一提的是,支持增加除了Map-Reduce之外的计算模型,这个彰显了Hadoop想做领域霸主的决心,之前的Hadoop基本上就与Map-Reduce划上了等号,Map-Reduce干不了的事情,Hadoop基本上就干不了。Map-Reduce能做的事情有限(可以参考一下我之前的一篇文章,在”hadoop的劣势”部分),简单的说就是,数据多,但是计算简单的时候,hadoop威力强大。如果计算逻辑复杂,需要搞个迭代至收敛之类的算法之类的,hadoop就玩不动了。如果能够在Hadoop上加入其他的计算模型,支持这种数据量不那么大,但是计算量大的场景,就防止一些挑剔的客户在这个问题上jjyy了。
最后说的支持limited, short-lived services还没有看到过更详细的说明,如果有人明白欢迎补充
老的Map-reduce设计
下面给出一个设计图,
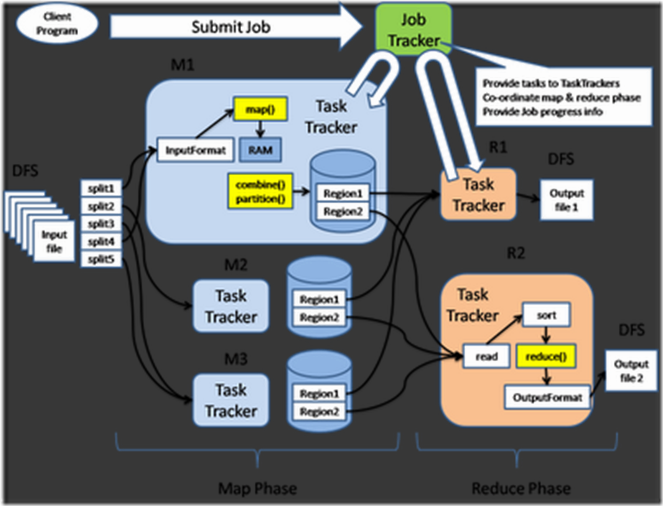
简单的介绍一下
1. 首先用户程序(Client Program)提交了一个job,job的信息会发送到Job Tracker中,Job Tracker是Map-reduce框架的中心,他需要与集群中的机器定时通信(heartbeat), 需要管理哪些程序应该跑在哪些机器上,需要管理所有job失败、重启等操作。
2. TaskTracker是Map-reduce集群中每台机器都有的一个部分,他做的事情主要是监视自己所在机器的资源情况(资源的表示是“本机还能起多少个map-task,多少个reduce-task”,每台机器起map/reduce task的上限是在建立集群的时候配置的),另外TaskTracker也会监视当前机器的tasks运行状况。
TaskTracker需要把这些信息通过heartbeat发送给JobTracker,JobTracker会搜集这些信息以给新提交的job分配运行在哪些机器上。上图回形针一样的箭头就是表示消息的发送-接收的过程。
够简单吧?当前的架构这么两句话就概括出来了,不过当你去看代码的时候,发现代码非常的难读,因为常常一个类3000多行,因为一个class做了太多的事情,这样会造成class的任务不清楚。另外,从我的理解来说,上面的设计至少有下面的几个问题,
1. JobTracker是Map-reduce的单点,看起来多多少少让人不爽
2. JobTracker完成了太多的任务,造成了过多的资源消耗,当map-reduce job非常多的时候,会造成很大的内存开销,潜在来说,也增加了很多JobTracker fail的风险
3. 在TaskTracker端,以map/reduce task的数目作为资源的表示过于简单,没有考虑到cpu/内存的占用情况,如果两个大内存消耗的task被调度到了一块,很容易出现OOM
4. 在TaskTracker端,把资源强制划分为map task slot和reduce task slot, 如果当系统中只有map task或者只有reduce task的时候,会造成资源的浪费,也就是前面提过的集群资源利用的问题

上面提到的4个问题,在Yarn中,除了第一个属于“部分完成”以外,其他的几个问题都已经解决掉了
看看Map-reduce v2的设计:

首先User还是User,JobTracker和TaskTracker不见了,取而代之的是ResourceManager, Application Master与Node Manager三个部分。我详细的说一下。
首先Resource Manager是一个中心的服务,它做的事情是调度、启动每一个Job所属的ApplicationMaster、另外监控ApplicationMaster的存在情况。
细心的朋友已经发现少了点什么,对!Job里面所在的task的监控、重启等等内容不见了。这就是ApplicationMaster存在的原因。
上图中的MPI Mast(er)与MR Master就是某一个MPI Job或者MR Job的ApplicationMaster,一定要记住,ApplicationMaster是每一个Job(不是每一种)都有的一个部分,ApplicationMaster可以运行在ResourceManager以外的机器上。老的框架中,JobTracker一个很大的负担就是监控job下的tasks的运行状况,现在,这个部分就扔给ApplicationMaster做了,而ResourceManager中有一个模块叫做ApplicationsMaster,它是监测ApplicationMaster的运行状况,如果出问题,会将其在其他机器上重启。
设计优点一:这个设计大大减小了JobTracker(也就是现在的ResourceManager)的资源消耗,并且让监测每一个Job子任务(tasks)状态的程序分布式化了,更安全、更优美
另外,在新版中,ApplicationMaster是一个可变更的部分,用户可以对不同的编程模型写自己的ApplicationMaster,让更多类型的编程模型能够跑在Hadoop集群中。
设计优点二:能够支持不同的编程模型
设计优点三:对于资源的表示以内存为单位(在目前版本的Yarn中,没有考虑cpu的占用),比之前以剩余slot数目更合理
设计优点四:既然资源表示成内存量,那就没有了之前的map slot/reduce slot分开造成集群资源闲置的尴尬情况了

其实在Yarn中还有很多优美的设计,之后慢慢再给大家说一下
总结:
在Hadoop 0.23版中,就已经加入了Yarn,这个改变让Hadoop从单一的“黑虎掏心”变成了少林七十二绝学,学习了解Yarn也将是一个合格的hadooper的基本素质
hadoop杂记-为什么会有Map-reduce v2 (Yarn)的更多相关文章
- Hadoop简介(1):什么是Map/Reduce
看这篇文章请出去跑两圈,然后泡一壶茶,边喝茶,边看,看完你就对hadoop整体有所了解了. Hadoop简介 Hadoop就是一个实现了Google云计算系统的开源系统,包括并行计算模型Map/Red ...
- 入门大数据---Map/Reduce,Yarn是什么?
简单概括:Map/Reduce是分布式离线处理的一个框架. Yarn是Map/Reduce中的一个资源管理器. 一.图形说明下Map/Reduce结构: 官方示意图: 另外还可以参考这个: 流程介绍: ...
- hadoop入门级总结二:Map/Reduce
在上一篇博客:hadoop入门级总结一:HDFS中,简单的介绍了hadoop分布式文件系统HDFS的整体框架及文件写入读出机制.接下来,简要的总结一下hadoop的另外一大关键技术之一分布式计算框架: ...
- 用通俗易懂的大白话讲解Map/Reduce原理
Hadoop简介 Hadoop就是一个实现了Google云计算系统的开源系统,包括并行计算模型Map/Reduce,分布式文件系统HDFS,以及分布式数据库Hbase,同时Hadoop的相关项目也很丰 ...
- 生动有趣地讲解Map/Reduce基本原理
Hadoop简介 Hadoop就是一个实现了Google云计算系统的开源系统,包括并行计算模型Map/Reduce,分布式文件系统HDFS,以及分布式数据库Hbase,同时Hadoop的相关项目也很丰 ...
- Hadoop Map/Reduce教程
原文地址:http://hadoop.apache.org/docs/r1.0.4/cn/mapred_tutorial.html 目的 先决条件 概述 输入与输出 例子:WordCount v1.0 ...
- 一步一步跟我学习hadoop(5)----hadoop Map/Reduce教程(2)
Map/Reduce用户界面 本节为用户採用框架要面对的各个环节提供了具体的描写叙述,旨在与帮助用户对实现.配置和调优进行具体的设置.然而,开发时候还是要相应着API进行相关操作. 首先我们须要了解M ...
- Hadoop 2.4.1 Map/Reduce小结【原创】
看了下MapReduce的例子.再看了下Mapper和Reducer源码,理清了参数的意义,就o了. public class Mapper<KEYIN, VALUEIN, KEYOUT, VA ...
- Hadoop :map+shuffle+reduce和YARN笔记分享
今天做了一个hadoop分享,总结下来,包括mapreduce,及shuffle深度讲解,还有YARN框架的详细说明等. v\:* {behavior:url(#default#VML);} o\:* ...
随机推荐
- 流操作结束后,一定要调用close(). java有垃圾回收器, 这样做是多此一举吗?
流不单在内存中分配了空间,也在操作系统占有了资源, java的gc是能从内存中回收不使用的对象, 但对操作系统分配的资源是无能为力的, 所以就要调用close()方法来通知OS来释放这个资源.
- Ubuntu 下建立WiFi热点的方法
使用ap-hotspot来创建WIFI热点.终端里输入: $ sudo add-apt-repository ppa:nilarimogard/webupd8 $ sudo apt-get updat ...
- ubuntu12.04下helloworld驱动从失败到成功过程
最近在看linux的设备驱动程序,写一个简单的helloworld程序都花了我好久的时间,具体过程如下: 编写helloworld.c 编写Makefile 注意,makefile中的命令那里是一个t ...
- FFmpeg视频处理必备
http://ffmpeg.org/官网 A complete, cross-platform solution to record, convert and stream audio and vid ...
- Android-PullToRefresh(一)
先讲下这篇写啥东西,也就是这家伙(chrisbanes)写的一个上拉下拉刷新的Demo,连接https://github.com/fengcunhan/Android-PullToRefresh 东西 ...
- myeclipse2014安装jad反编译插件
myeclipse上默认不能查看class文件,需要查看的话安装反编译插件 安装步骤: 准备图中框里的两个文件 1. [net.sf.jadclipse_3.3.0.jar]文件拷贝到如下路径([D: ...
- QQ的未来在那里
http://blog.sina.com.cn/s/blog_53bcb13e0100030g.html 早期的QQ非常清爽,没有广告,友好的界面,飞快的连接速度,为中国人量身订做的体贴功能,非常吸引 ...
- Android开发优化之——从代码角度进行优化
通常我们写程序,都是在项目计划的压力下完成的,此时完成的代码可以完成具体业务逻 辑,但是性能不一定是最优化的.一般来说,优秀的程序员在写完代码之后都会不断的对代码进行重构.重构的好处有很多,其中一点, ...
- FFMPEG音视频解码
文章转自:https://www.cnblogs.com/CoderTian/p/6791638.html 1.播放多媒体文件步骤 通常情况下,我们下载的视频文件如MP4,MKV.FLV等都属于封装格 ...
- ie,cookie,域名与下划线
前几天为了开发方便,和一个同事将XX.qq.com的测试站点拆成两个站点,我那个叫XX_hanks.qq.com,进行功能开发,在调试 cookie功能的时候,发现IE下cookie没有记住,用htt ...